- 軟件系統(tǒng)優(yōu)化
- 郭健美 黃波 劉通宇 林曉東 趙鵬
- 1576字
- 2025-08-07 15:12:57
1.5 循環(huán)分塊
我們進(jìn)一步思考如何利用底層硬件中的CPU高速緩存來優(yōu)化程序性能。雖然通過交換循環(huán)順序提高了程序訪存的空間局部性和緩存命中率,但CPU高速緩存的大小是有限的,放不下所有要訪問的數(shù)據(jù)。簡單估算一下,在i,k,j的循環(huán)順序之下,對(duì)結(jié)果矩陣寫一行數(shù)據(jù)需要多少次訪存需求呢?如圖1.2a所示,對(duì)于結(jié)果矩陣C,在寫入一行數(shù)據(jù)之時(shí),需要4096次的數(shù)據(jù)寫入。而針對(duì)矩陣A,此時(shí)需要讀入矩陣的一行數(shù)據(jù)作為計(jì)算的輸入,即4096次內(nèi)存讀入。而對(duì)于矩陣B,則需要讀取整個(gè)矩陣作為計(jì)算輸入,即需要4096×4096=224次內(nèi)存數(shù)據(jù)讀入。由此可見,在寫入一行矩陣C的數(shù)據(jù)時(shí),共計(jì)有212+212+224次內(nèi)存訪問需求。由于讀取的數(shù)據(jù)都是double類型,根據(jù)機(jī)器的應(yīng)用二進(jìn)制程序接口(Application Binary Interface,ABI)的定義,double類型數(shù)據(jù)的大小為8字節(jié),那么在矩陣C寫入一行時(shí)就需要約128MiB的內(nèi)存訪問量。這個(gè)內(nèi)存訪問量明顯大于實(shí)驗(yàn)環(huán)境下CPU上的三級(jí)緩存(L3 Cache)容量。這就表明,在處理一行矩陣C的結(jié)果時(shí),要發(fā)生多次緩存未命中來進(jìn)行內(nèi)存數(shù)據(jù)訪問。那么,有什么好的方法能夠提高緩存數(shù)據(jù)的復(fù)用性呢?
一個(gè)可行的方法就是對(duì)矩陣乘法進(jìn)行分塊(tiling)處理。比如,將4096×4096矩陣乘法拆分成64×64個(gè)更小規(guī)模的64×64小矩陣乘法進(jìn)行迭代處理。如圖1.2b所示,可以估算一下采用這種方法的內(nèi)存訪問需求量。在寫入矩陣C的一個(gè)小分塊時(shí),需要64×64=212次內(nèi)存寫入,對(duì)于矩陣A則需要64×4096=218次內(nèi)存讀取。對(duì)于矩陣B,也需要4096×64=218次內(nèi)存讀取。在這種情況下,總共需要約4MiB的內(nèi)存訪問量,這個(gè)規(guī)模的數(shù)據(jù)就可以考慮都放在CPU三級(jí)緩存中復(fù)用,從而增加緩存命中率。代碼1.7給出了對(duì)代碼1.6進(jìn)行循環(huán)分塊優(yōu)化的示例,注意,它與代碼1.6的主要差別是對(duì)循環(huán)體進(jìn)行了更深層次的拆分。
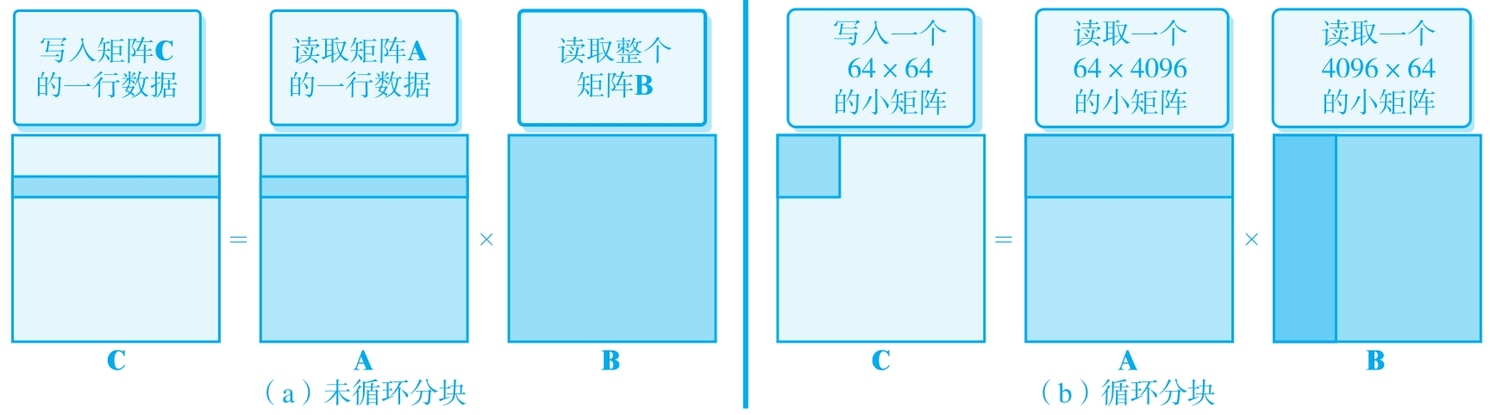
圖1.2 矩陣乘法的循環(huán)分塊
代碼1.7 采用了循環(huán)分塊的矩陣乘法


由于循環(huán)拆分的特性,此時(shí)可以對(duì)最外面的兩層循環(huán)同時(shí)進(jìn)行并行化處理。我們使用OpenMP中的collapse(2)接口來對(duì)外面兩層循環(huán)同時(shí)進(jìn)行并行化。實(shí)際上,在OpenMP編程規(guī)范的具體實(shí)現(xiàn)中,會(huì)把外面兩層循環(huán)重新合并計(jì)算為一層循環(huán),再對(duì)合并后的單層循環(huán)進(jìn)行并行化。不過,編譯器會(huì)自動(dòng)處理這個(gè)合并操作,我們只需要按照原本分析問題的邏輯編寫程序即可。
然而,這里又會(huì)出現(xiàn)一個(gè)問題,我們?cè)撊绾卧O(shè)定分塊大小才能讓性能更好?最好的辦法就是通過實(shí)驗(yàn)測(cè)量來判定,這也是一項(xiàng)常見的配置參數(shù)調(diào)優(yōu)工作。對(duì)于代碼1.7,可以利用以下命令在編譯程序的時(shí)候就直接傳入分塊S的大小:
此外,在上述代碼和命令的基礎(chǔ)上,可以實(shí)現(xiàn)一個(gè)簡單的自動(dòng)調(diào)優(yōu)器(autotuner),枚舉各種可能的分塊大小,再編譯和運(yùn)行程序,最后根據(jù)運(yùn)行結(jié)果選擇性能最優(yōu)的分塊大小。這里,枚舉不同的分塊大小后,獲得的運(yùn)行數(shù)據(jù)如表1.6所示。根據(jù)實(shí)驗(yàn)結(jié)果可以看到,在我們的機(jī)器上將4096×4096矩陣乘法拆分為32×32個(gè)128×128的子矩陣乘法進(jìn)行處理是一個(gè)性能較優(yōu)的方案。接下來,我們?cè)诖朔謮K配置的基礎(chǔ)上繼續(xù)優(yōu)化。
表1.6 矩陣分塊大小對(duì)運(yùn)行時(shí)間的影響

注意,盡管上述循環(huán)分塊使得一次子矩陣乘法計(jì)算的數(shù)據(jù)量能夠存放在CPU三級(jí)緩存中進(jìn)行復(fù)用,但目前還是沒有充分利用底層硬件的CPU緩存。這是因?yàn)镃PU緩存通常是一個(gè)多層體系結(jié)構(gòu),包括一級(jí)、二級(jí)和三級(jí)緩存。緩存的級(jí)別越高(一級(jí)最高,三級(jí)最低),速度越快,但容量越小。因此,可以考慮進(jìn)一步分塊,使計(jì)算規(guī)模更小,盡可能復(fù)用級(jí)別更高、速度更快的緩存。代碼1.8給出了參考實(shí)現(xiàn),它與代碼1.7的主要區(qū)別是進(jìn)行了更深層次的二級(jí)循環(huán)分塊。
代碼1.8 采用了二級(jí)循環(huán)分塊的矩陣乘法


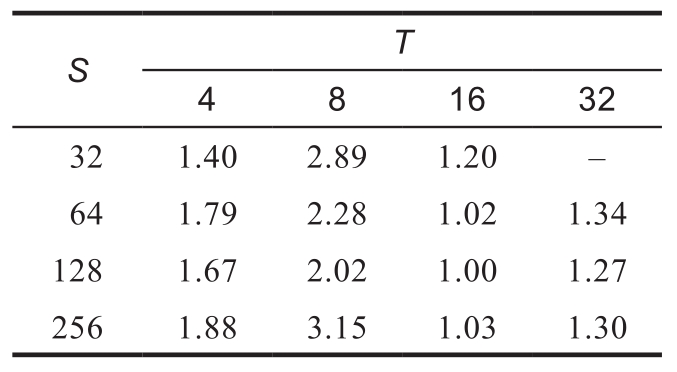
在代碼1.8中,首先將4096×4096矩陣乘法拆分為4096/S×4096/S個(gè)大小為S×S的子矩陣乘法進(jìn)行處理,然后,將這些S×S子矩陣乘法進(jìn)一步拆分為S/T×S/T個(gè)更小的T×T子矩陣乘法。采用自動(dòng)調(diào)優(yōu)的方法,可以嘗試S和T的不同大小,找到適合實(shí)驗(yàn)環(huán)境下CPU緩存的循環(huán)分塊配置。表1.7列出了實(shí)驗(yàn)結(jié)果,可以看到,當(dāng)S為128、T為16的時(shí)候,可以獲得實(shí)驗(yàn)環(huán)境下性能最優(yōu)的二級(jí)循環(huán)分塊配置。
表1.7 二級(jí)循環(huán)分塊參數(shù)對(duì)運(yùn)行時(shí)間(秒)的影響
- Instant Node Package Manager
- Drupal 8 Blueprints
- 程序員面試筆試寶典
- 程序員面試算法寶典
- Rust Cookbook
- Windows Presentation Foundation Development Cookbook
- Learning Data Mining with R
- Android程序設(shè)計(jì)基礎(chǔ)
- Python深度學(xué)習(xí):模型、方法與實(shí)現(xiàn)
- SciPy Recipes
- Mastering Android Studio 3
- Anaconda數(shù)據(jù)科學(xué)實(shí)戰(zhàn)
- scikit-learn Cookbook(Second Edition)
- INSTANT Apache ServiceMix How-to
- AI自動(dòng)化測(cè)試:技術(shù)原理、平臺(tái)搭建與工程實(shí)踐