- 計算社會學:基礎理論篇
- 郭斌 梁韻基 於志文
- 3374字
- 2024-05-24 17:40:31
PREFACE
前言
2009年,以哈佛大學拉澤爾教授為首的15名頂級學者在《科學》(Science)發表署名文章,首次提出“計算社會學”(Computational Social Science)這一概念。計算社會學以移動互聯網、社交媒體、物聯網等新興技術為基礎,借助于統計理論、知識推理和人工智能等理論體系,從跨域、連續、非結構化的海量數據中分析個體的靜態屬性,洞察群體和宏觀社會的動態變化,是一門蓬勃發展的綜合性交叉學科。計算社會學已經廣泛地應用到政治、經濟、社會文化、公共健康等多個領域,與大眾的切身利益休戚相關,對國家的戰略安全與社會穩定意義重大。
十多年來,以移動社交網絡、智能手機與可穿戴設備、泛在的物聯網終端為代表的信息技術和產品得到廣泛應用,為計算社會學提供了前所未見的大規模、多側面的人類行為感知能力。同時,以大數據和人工智能為代表的數據科學理論,使得研究人員能夠抽絲剝繭從大量紛繁蕪雜的數據中發現和洞悉其中的本質。層出不窮的新型感知技術和智能算法為研究人類社會提供了一個全新的路徑,正在不斷地改變社會科學家和數據科學家探索世界、發現規律的方式。
《計算社會學》是一本系統性梳理計算社會學相關理論和方法的論著。一方面,本書從傳統復雜網絡分析的角度,詳細闡述了社會網絡分析的基礎理論和動力學模型——隨機網絡、小世界網絡、無標度網絡和網絡統計分析理論等,并將網絡過程和行為應用于涌現、流行病學研究等方面。另一方面,融合人工智能在自然語言處理、推薦算法等領域的進展,闡述了人工智能算法尤其是深度學習理論等在智能推薦、文本分析、假消息檢測、虛擬社交機器人等領域的應用。在兼顧廣度和深度的前提下,本書深度融合計算機科學、社會學、人工智能和復雜網絡等多學科的專業概念,突出闡述了計算社會學領域近年來的最新研究成果和關鍵技術突破。
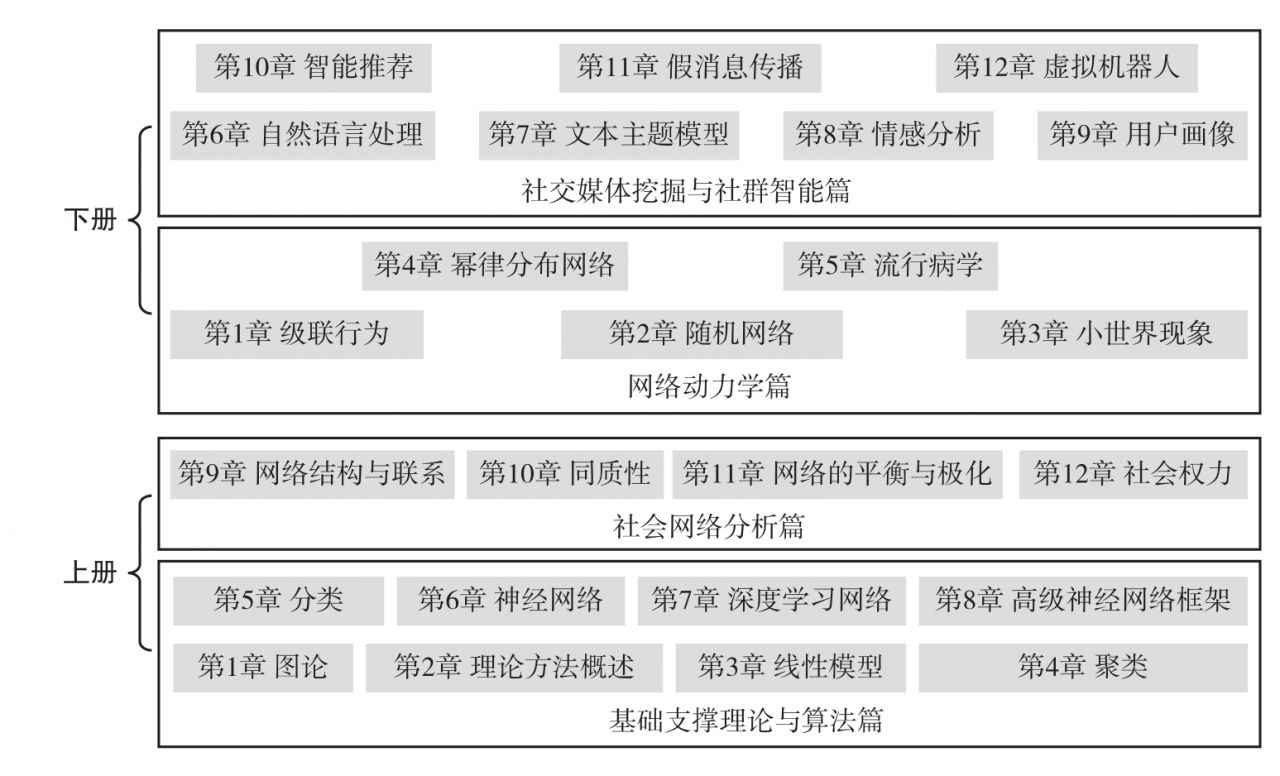
本書分為上、下兩冊,采用理論、方法與關鍵技術相結合的方式安排各章內容。上冊《計算社會學:基礎理論篇》分為基礎支撐理論與算法篇和社會網絡分析篇,首先介紹圖論及機器學習的基本概念,進而對典型的機器學習算法如線性回歸、聚類算法和分類算法,以及極具代表性的深度神經網絡算法(如卷積神經網絡、循環神經網絡、對抗生成網絡等)進行基礎性介紹,最后從網絡基本理論(三元閉包等)出發介紹了強關系和弱關系的應用和聯系,從選擇和社會影響兩個角度闡述了同質化的形成原理,并且闡述了網絡極化的形成機理與度量方法,進而從節點權力的角度闡述社會權力的核心內涵。下冊《計算社會學:系統應用篇》分為網絡動力學篇和社交媒體挖掘與社群智能篇,首先介紹了典型的網絡動力學模型,如逾滲理論、ER隨機模型、小世界模型和無標度網絡模型等,并重點介紹了傳染病的建模方法,同時以自然語言理解為基礎介紹社交媒體挖掘方法,包括自然語言模型、話題模型等,進而介紹了用戶畫像、智能推薦、假消息傳播和虛擬機器人等計算社會學前沿技術。
上冊:
1.基礎支撐理論與算法篇(第1~8章)
第1章簡要介紹圖論的基本概念和計算理論,包括圖的表示、存儲、遍歷和最短路徑等經典問題。第2章介紹機器學習的基本概念和發展歷程,重點介紹機器學習的基本數據處理流程,包括數據預處理、特征抽取與選擇、誤差的產生和模型評估等。
第3~5章為基礎算法。其中第3章主要介紹線性回歸模型,包括一元線性回歸和多元線性回歸。第4章為聚類算法,從聚類問題的核心目標任務出發,引入了聚類中的一個重要概念——距離度量,系統梳理了聚類任務中的典型算法。第5章主要內容包括貝葉斯分類器、支持向量機、決策樹和隨機森林。另外針對單一模型能力有限的問題,介紹集成學習方法,支持相同或者不同基模型的融合。
第6~8章為高級算法。其中第6章介紹傳統的神經網絡的基本概念和理論,包括神經元模型、多層感知機、誤差反向傳播以及其他新型的神經網絡,例如玻爾茲曼機、脈沖神經網絡等。第7章介紹卷積神經網絡、循環神經網絡、圖神經網絡等模型,并從模型訓練出發介紹網絡模型訓練優化方法。第8章介紹其他高級神經網絡,包括生成對抗網絡、自編碼器、編-解碼器、注意力機制。
2.社會網絡分析篇(第9~12章)
第9章從三元閉包等理論出發介紹了強關系和弱關系的應用和聯系。第10章首先引入了社會同質現象,并從社會選擇和社會影響兩個角度闡述同質化的形成原理,并介紹同質化的社會性影響,包括人群隔離、感知偏差、同伴效應等。第11章從網絡結構的角度介紹認知平衡模型和結構平衡理論,針對網絡中廣泛存在的極化現象,闡述了極化的成因以及極化網絡的檢測和量化方法。第12章從節點權力的角度對社會網絡進行深入分析,闡述社會權力的形成機理和量化方法,包括納什均衡與網絡議價、節點權力的度量等。
下冊:
1.網絡動力學篇(第1~5章)
第1章從隨大流現象出發,介紹了網絡中信息傳播的經典模型,包括級聯模型、晶格理論、逾滲理論及其變種。第2章重點介紹了ER隨機模型及其統計特性,并通過仿真實驗對ER模型進行驗證分析。第3章從經典的六度分隔實驗出發,引入小世界現象,進而介紹了小世界網絡模型的數學形式化表達及屬性。第4章介紹了冪律分布的數學特性以及冪律分布的典型應用,并基于上述觀察,引入無標度網絡及其模型特性。第5章介紹了典型的傳染病模型,并講解了傳染病的防控和干預。
2.社交媒體挖掘與社群智能篇(第6~12章)
第6~8章主要介紹以自然語言理解為基礎的社交媒體挖掘方法。其中第6章首先介紹了經典語言建模工作,包括詞袋模型、n-gram模型;然后重點介紹了自然語言處理中典型的序列數據處理方法,包括隱馬爾可夫和條件隨機場;最后介紹了自然語言處理中的典型任務和預訓練模型。第7章介紹了主題分析模型,包括潛在語義分析、概率潛在語義分析、潛在狄利克雷分配模型。第8章系統梳理情感挖掘領域的工作,從詞語、句子/文檔和屬性三個粒度總結了情感分析的研究進展。
第9~12章則介紹了計算社會學領域的新興技術。其中第9章從單模態用戶畫像和多模態用戶畫像兩個角度總結了用戶畫像技術的最新工作進展。第10章首先介紹協同過濾和基于內容的推薦兩類典型模型;然后介紹基于深度學習的推薦算法,概述基于情境感知的推薦方法;最后總結了推薦系統中現有的評估策略和方法。第11章主要從假消息的定義、假消息的認知機理、多模態假消息檢測方法、群智融合假消息檢測、可解釋假消息檢測五個方面展開介紹。第12章主要對虛擬機器人設計與實現過程中所涉及的關鍵技術進行總結,包括虛擬形象塑造和個性化內容生成等,講解虛擬機器人塑造完成流程。此外,重點介紹了典型虛擬機器人塑造平臺AI-Mate系統架構。
在本書成稿的過程,西北工業大學智能感知與計算工信部重點實驗室的研究生深度參與,為書稿的編撰付出了辛勞和智慧:趙志英(上冊第1章)、孫月琪(上冊第2、3章)、李智敏(上冊第4章,下冊第9章)、成家慧(上冊第5章)、王虹力(上冊第6章)、任浩陽(上冊第7章)、郝少陽(上冊第8章)、張秋韻(上冊第9、11章)、馮煦陽(上冊第10章)、丁亞三(上冊第12章,下冊第1、4、11章)、吳廣智(下冊第2、5章)、張玉琪(下冊第3章)、王梓琪(下冊第4章)、王豪(上冊第8章,下冊第6、12章)、李可(下冊第7章)、李諾(上冊第4章,下冊第8、9、10章)、張巖(下冊第10章)。在此對他們的辛勤付出表示感謝!感謝實驗室學術帶頭人周興社教授和學術顧問張大慶教授多年來的悉心培養、指導以及在本書編寫和審校過程中給予的寶貴意見。此外還要特別感謝機械工業出版社的編輯們在本書準備過程中給予的全力支持與專業指導。
我們還要特別感謝美國亞利桑那州立大學劉歡教授、澳大利亞新南威爾士大學姚麗娜教授、北京大學李曉明教授、中國科學院自動化研究所曾大軍教授、上海交通大學薛可教授、北京航空航天大學馬帥教授、北京航空航天大學李建欣教授、西安交通大學饒元教授、微軟亞洲研究院首席研究員謝幸博士、微軟小冰首席科學家宋睿華博士、京東集團副總裁、京東城市總裁鄭宇博士、華為云人工智能領域副總裁袁晶博士等計算社會學領域的同行學者,本書也融入了部分以前大家一起研討或項目合作的成果。在本書成稿過程中,還有很多同事和朋友以不同形式提供了幫助,難免有所疏漏,在此就不一一列舉,敬請各位諒解。
計算社會學作為一個快速發展的新興研究領域,新概念、新問題、新方法不斷涌現,限于作者的學識水平和研究局限,本書難免會存在疏漏或不足之處,敬請讀者批評指正。
作者
2023年10月于西安