- Python網(wǎng)絡爬蟲技術(shù)與應用
- 鄧維等主編
- 1242字
- 2023-08-25 12:18:43
1.1.2 網(wǎng)絡爬蟲的流程
1.基本流程
捜索引擎抓取系統(tǒng)的主要組成部分是網(wǎng)絡爬蟲,把互聯(lián)網(wǎng)上的網(wǎng)頁下載到本地形成一個聯(lián)網(wǎng)內(nèi)容的鏡像備份是網(wǎng)絡爬蟲的主要目標。
網(wǎng)絡爬蟲的基本工作流程如下:一開始選取一部分精心挑選的種子URL;把這些URL放入URL隊列中;從URL隊列中取出待抓取的URL,讀取URL之后開始解析DNS,并把URL對應的網(wǎng)頁下載下來,放進網(wǎng)頁庫中。此外,把這些URL放入已抓取URL隊列。
分析已抓取URL隊列中的URL,并且把URL放入待抓取URL隊列,使其進入下一個循環(huán)。網(wǎng)絡爬蟲的基本流程如圖1-1所示。
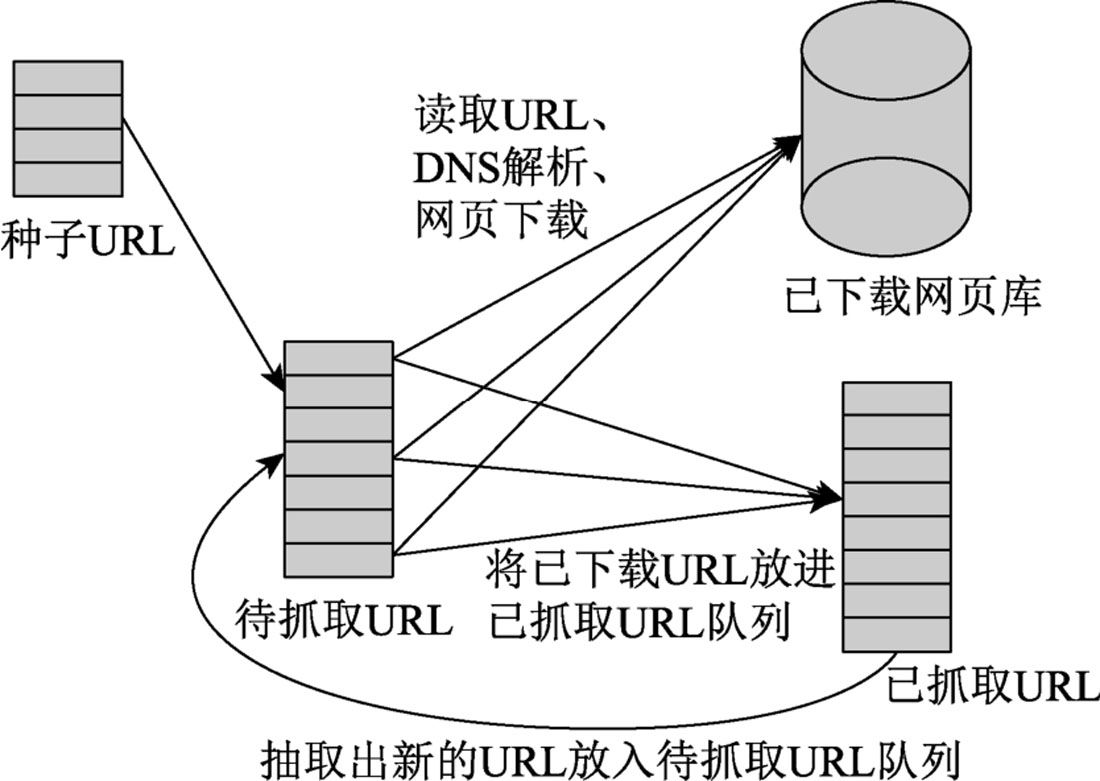
圖1-1 網(wǎng)絡爬蟲的基本流程
用簡短易懂的方式來講,即分為四個步驟:發(fā)送請求→獲取響應內(nèi)容→解析內(nèi)容→保存數(shù)據(jù)。請求流程如圖1-2所示。

圖1-2 請求流程圖
2.從網(wǎng)絡爬蟲的角度對互聯(lián)網(wǎng)進行劃分
從網(wǎng)絡爬蟲的角度可將互聯(lián)網(wǎng)劃分為以下五種:
(1)已下載未過期網(wǎng)頁。
(2)已下載已過期網(wǎng)頁:抓取到的網(wǎng)頁實際上是互聯(lián)網(wǎng)內(nèi)容的一個鏡像與備份,互聯(lián)網(wǎng)是動態(tài)變化的,一部分互聯(lián)網(wǎng)上的內(nèi)容已經(jīng)發(fā)生變化,這時這部分抓取到的網(wǎng)頁就已經(jīng)失效。
(3)待下載網(wǎng)頁:是指待抓取URL隊列中的那些頁面。
(4)可知網(wǎng)頁:尚未抓取下來,也沒有在待抓取URL隊列中,但是能夠經(jīng)由對已抓取頁面或者待抓取URL對應頁面進行分析獲得的URL,認為是可知網(wǎng)頁。
(5)不可知網(wǎng)頁:還有一部分網(wǎng)頁,網(wǎng)絡爬蟲是無法直接抓取下載的,稱為不可知網(wǎng)頁。
網(wǎng)頁類別劃分如圖1-3所示。
3.網(wǎng)頁抓取的基本原理
常見的叫法是網(wǎng)頁抓屏(Screen Scraping)、數(shù)據(jù)挖掘(Data Mining)、網(wǎng)絡收割(Web Harvesting)或其類似的叫法。
理論上,網(wǎng)頁抓取是一種經(jīng)由多種方法收集網(wǎng)絡數(shù)據(jù)的方式,不僅是經(jīng)由與API交互的方式。
最常用的方法是確定爬取的URL,確定數(shù)據(jù)存儲格式,寫一個自動化程序向網(wǎng)絡服務器請求數(shù)據(jù)(通常是用HTML表單或其網(wǎng)頁文件),而后對數(shù)據(jù)進行清洗解析,汲取需要的信息并存入數(shù)據(jù)庫,基本思路如圖1-4所示。
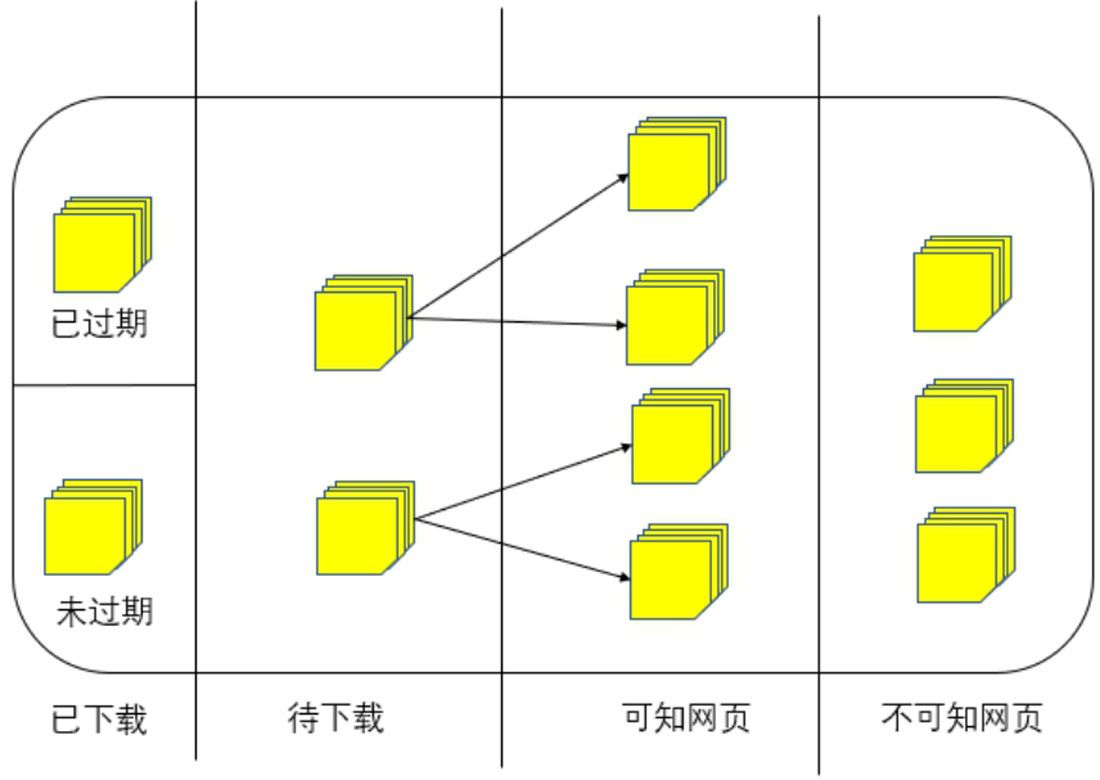
圖1-3 網(wǎng)頁劃分類別
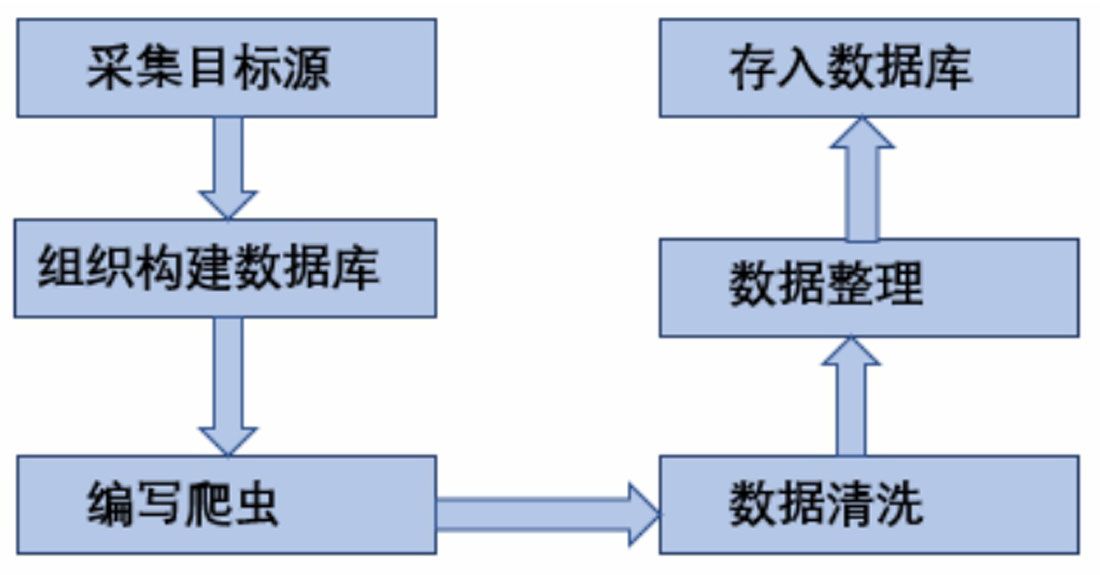
圖1-4 基本思路圖
4.目標源選擇
目標源選擇應依照以下條件進行排序:數(shù)據(jù)相關(guān)性、易抓取程度、數(shù)據(jù)量、Robots協(xié)議。當然,根據(jù)自己的需求能夠自由變更。同等情況下盡量避免大型企業(yè)的官網(wǎng),因為其中大部分都設有反爬機制。
5.編輯網(wǎng)絡爬蟲
推薦使用的庫有requests、BeautifulSoup、Scrapy、Selenium,假如關(guān)于效率需求不是特別高,能夠考慮使用requestspost請求采集頁面,而后使用BeautifulSoup分析頁面標簽,這樣實現(xiàn)較為簡短易懂,也能解決大部分需求;假如對效率比較重視,或需要完成一個工程化的采集項目,Scrapy能夠作為首選。對分布式處理的良好支持和清晰的模塊化層次在提升效率的同時更易于進行代碼的管理。對HTTP的相關(guān)請求,使用requests比用其他函數(shù)更加明智。
6.數(shù)據(jù)清洗
獲得的數(shù)據(jù)和期望中的數(shù)據(jù)總有一定的差別,這一部分的任務便是排除異常數(shù)據(jù),把其余數(shù)據(jù)轉(zhuǎn)換為易于處理的形式。數(shù)據(jù)的異常主要包括數(shù)據(jù)格式異常和數(shù)據(jù)內(nèi)容異常。需要的數(shù)據(jù)可能存放在一個PDF、Word、JPG格式的文件中,把它們轉(zhuǎn)換成文本而后選取相應的信息,這是數(shù)據(jù)清洗工作的一部分。另外,由于網(wǎng)頁發(fā)布者的疏忽,網(wǎng)頁上有部分數(shù)據(jù)和其他頁面呈現(xiàn)不同,但需要把這部分數(shù)據(jù)也抓取下來,此時需要進行一定的處理,把數(shù)據(jù)格式進行統(tǒng)一。
- 極簡算法史:從數(shù)學到機器的故事
- Progressive Web Apps with React
- C#程序設計教程
- UML+OOPC嵌入式C語言開發(fā)精講
- Amazon S3 Cookbook
- FPGA Verilog開發(fā)實戰(zhàn)指南:基于Intel Cyclone IV(進階篇)
- Protocol-Oriented Programming with Swift
- 開源項目成功之道
- Beginning C++ Game Programming
- 零基礎學C語言程序設計
- PHP與MySQL權(quán)威指南
- 超簡單:Photoshop+JavaScript+Python智能修圖與圖像自動化處理
- Hack與HHVM權(quán)威指南
- Python程序設計教程
- 深入大型數(shù)據(jù)集:并行與分布化Python代碼