- Python網絡爬蟲技術與應用
- 鄧維等主編
- 1144字
- 2023-08-25 12:18:44
1.1.3 網絡爬蟲的抓取
1.概述
網絡爬蟲的不同抓取策略,便是利用不同的方法確定待抓取URL隊列中URL的優先順序。網絡爬蟲的抓取策略有很多種,但不管方法如何,其根本目標一致。網頁的重要性評判標準不同,大部分采用網頁的流行性進行定義。網頁結構分布圖如圖1-5所示。
圖1-5 網頁結構分布圖
2.網絡爬蟲的抓取原理
一開始選取一部分精心挑選的種子URL,把這些URL放入待抓取URL隊列,從待抓取URL隊列中拿出待抓取的URL,解析DNS并且得到主機的IP地址,并把URL相應的網頁下載下來,存放進已下載網頁庫中。此外,把這些URL放進已抓取URL隊列。分析已抓取URL隊列中的URL,分析當中的其他URL,并且把URL放入待抓取URL隊列,繼續進入下一個循環。
3.網絡爬蟲的抓取策略
1)寬度優先遍歷(Breath First)策略
基本思路:將新下載網頁包含的鏈接直接追加到待抓取URL隊列末尾。
倘若網頁是1號網頁,從1號網頁中抽取出3個鏈接指向2號、3號和4號網頁,于是按照編號順序依次放入待抓取URL隊列,圖中網頁的編號便是在待抓取URL隊列中的順序編號,之后網絡爬蟲以此順序進行下載。抓取節點樹結構如圖1-6所示。
2)非完全PageRank(Partial PageRank)策略
基本思路:對于已下載的網頁,加上待抓取URL隊列中的URL一起,形成網頁集合,在此集合內進行PageRank計算,計算完成后,把待抓取URL隊列里的網頁依照PageRank得分由高到低排序,形成的序列便是網絡爬蟲接下來應該依次抓取的URL列表。
設定每下載3個網頁進行新的PageRank計算,此時已經有{1,2,3}3個網頁下載到本地。這三個網頁包含的鏈接指向{4,5,6},即待抓取URL隊列,如何決定下載順序?將這6個網頁形成新的集合,對這個集合計算PageRank的值,這樣4、5、6就獲得對應的PageRank值,由大到小排序,即可得出下載順序。假設順序為5、4、6,當下載5號頁面后抽取出鏈接,指向頁面8,此時賦予8臨時PageRank值,如果這個值大于4和6的PageRank值,則接下來優先下載頁面8,如此不斷循環,即形成非完全PageRank策略的計算思路。非完全PageRank策略結構圖如圖1-7所示。
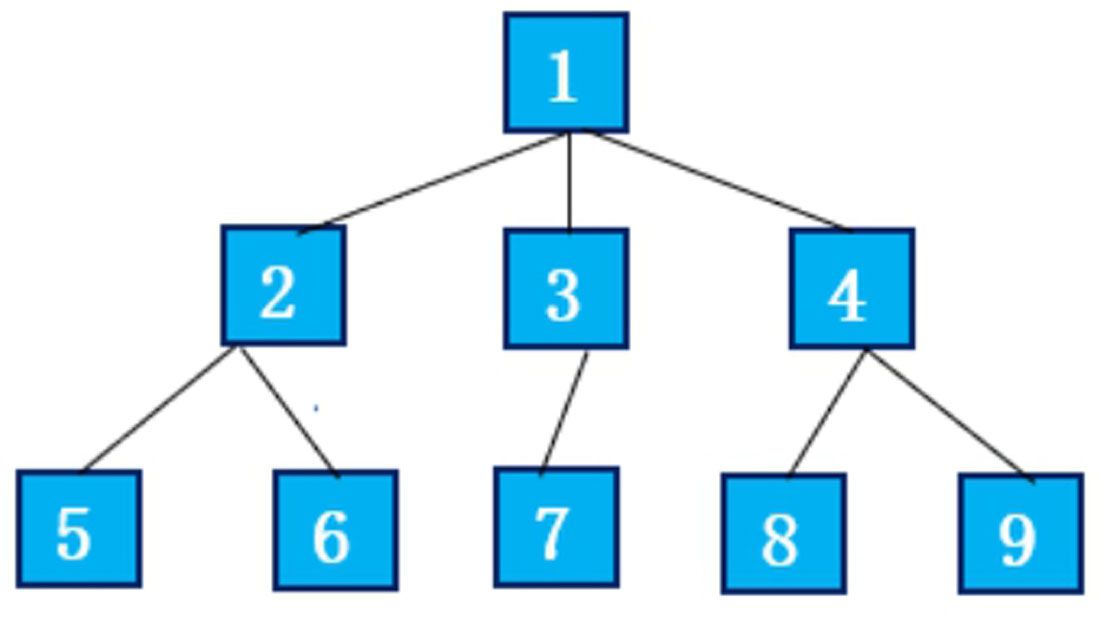
圖1-6 抓取節點樹結構
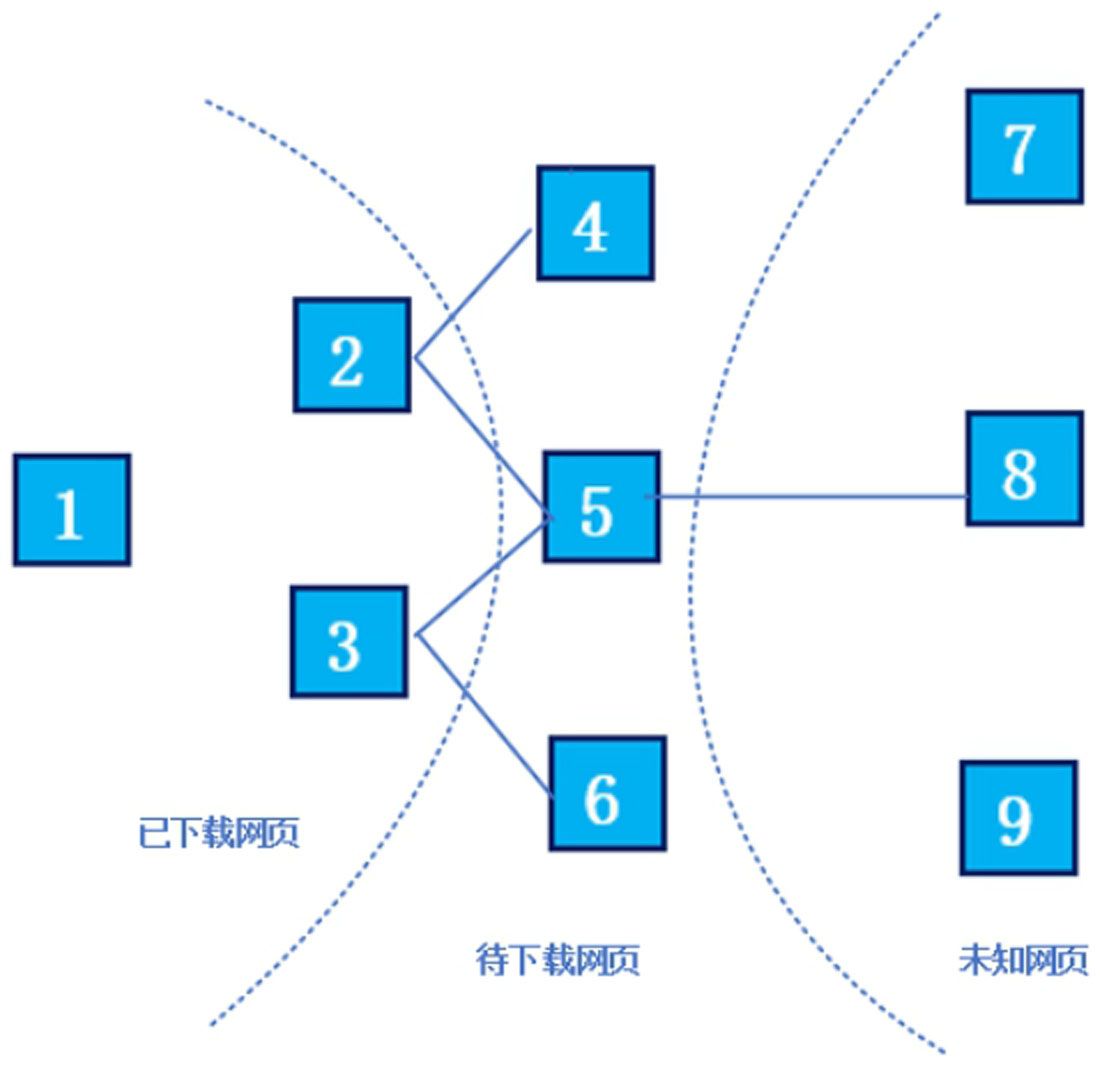
圖1-7 非完全PageRank策略結構圖
3)OPIC(Online Page Importance Computation,在線頁面重要性計算)策略
基本思路:在算法開始之前,每個互聯網頁面都給予相同的“現金”,每當下載某個頁面后,此頁面就把本身具有的“現金”平均分配給頁面中包含的鏈接頁面,把本身的“現金”清空。與PageRank的不同在于:PageRank每次需要迭代計算,而OPIC策略不需要迭代過程。所以,OPIC的計算速度遠遠快于PageRank,適合實時計算使用。
4)大站優先(Larger Sites First)策略
基本思路:以網站為單位來選題網頁重要性,關于待抓取URL隊列中的網頁,按照所屬網站歸類,假如哪個網站等待下載的頁面最多,則優先下載這些鏈接,其本質思想傾向于優先下載大型網站,因為大型網站常常包括更多的頁面。鑒于大型網站往往是著名企業的內容,其網頁質量一般較高,所以這個思路雖然簡單,但是有可靠依據。實驗表明,這個算法結果也要略優先于寬度優先遍歷策略。
- Apache ZooKeeper Essentials
- Learning Cython Programming(Second Edition)
- Java Web基礎與實例教程(第2版·微課版)
- Three.js開發指南:基于WebGL和HTML5在網頁上渲染3D圖形和動畫(原書第3版)
- Getting Started with PowerShell
- Mastering Python High Performance
- HTML5+CSS3+JavaScript Web開發案例教程(在線實訓版)
- Nexus規模化Scrum框架
- H5頁面設計:Mugeda版(微課版)
- 微信小程序入門指南
- Arduino家居安全系統構建實戰
- Procedural Content Generation for C++ Game Development
- FFmpeg開發實戰:從零基礎到短視頻上線
- Learning Nessus for Penetration Testing
- 超簡單:Photoshop+JavaScript+Python智能修圖與圖像自動化處理