- Flink技術內幕:架構設計與實現原理
- 羅江宇 趙士杰等
- 1863字
- 2021-12-29 15:54:16
1.4 Flink設計理念與基本架構
到目前為止,我們從整體上對Flink的源代碼有了初步了解,接下來將從設計理念的角度將Flink與主流計算引擎Hadoop MapReduce和Spark進行對比,并從宏觀上介紹Flink的基本架構。
1.4.1 Flink與主流計算引擎對比
1. Hadoop MapReduce
MapReduce是由谷歌首次在論文“MapReduce: Simplified Data Processing on Large Clusters”(谷歌大數據三駕馬車之一)中提出的,是一種處理和生成大數據的編程模型。Hadoop MapReduce借鑒了谷歌這篇論文的思想,將大的任務分拆成較小的任務后進行處理,因此擁有更好的擴展性。如圖1-8所示,Hadoop MapReduce包括兩個階段——Map和Reduce:Map階段將數據映射為鍵值對(key/value),map函數在Hadoop中用Mapper類表示;Reduce階段使用shuffle后的鍵值對數據,并使用自身提供的算法對其進行處理,得到輸出結果,reduce函數在Hadoop中用Reducer類表示。其中shuffle階段對MapReduce模式開發人員透明。
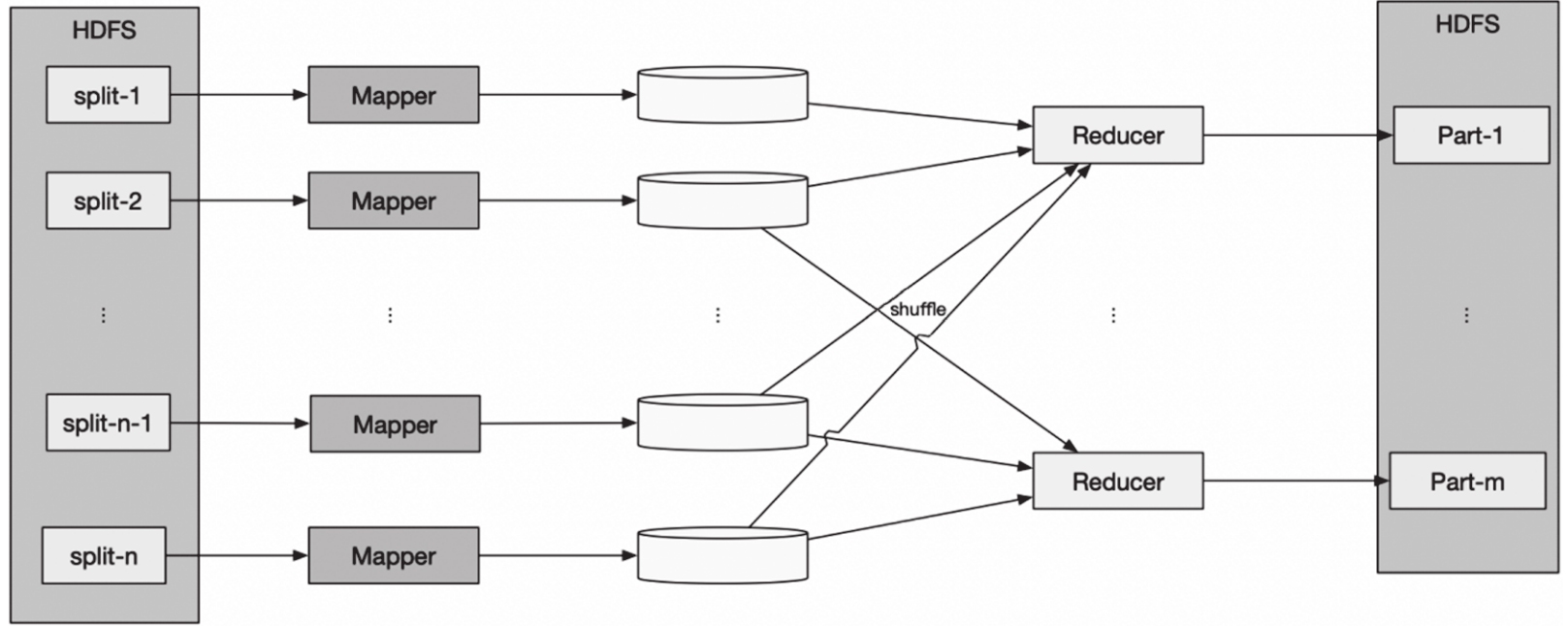
圖1-8 Hadoop MapReduce處理模型
Hadoop MR1通過JobTracker進程來管理作業的調度和資源,TaskTracker進程負責作業的實際執行,通過Slot來劃分資源(CPU、內存等),Hadoop MR1存在資源利用率低的問題。Hadoop MR2為了解決MR1存在的問題,對作業的調度與資源進行了升級改造,將JobTracker變成YARN,提升了資源的利用率。其中,YARN的ResourceManager負責資源的管理,ApplicationMaster負責任務的調度。YARN支持可插拔,不但支持Hadoop MapReduce,還支持Spark、Flink、Storm等計算框架。Hadoop MR2解決了Hadoop MR1的一些問題,但是其對HDFS的頻繁I/O操作會導致系統無法達到低延遲的要求,因而它只適合離線大數據的處理,不能滿足實時計算的要求。
2. Spark
Spark是由加州大學伯克利分校開源的類Hadoop MapReduce的大數據處理框架。與Hadoop MapReduce相比,它最大的不同是將計算中間的結果存儲于內存中,而不需要存儲到HDFS中。
Spark的基本數據模型為RDD(Resilient Distributed Dataset,彈性分布式數據集)。RDD是一個不可改變的分布式集合對象,由許多分區(partition)組成,每個分區包含RDD的一部分數據,且每個分區可以在不同的節點上存儲和計算。在Spark中,所有的計算都是通過RDD的創建和轉換來完成的。
Spark Streaming是在Spark Core的基礎上擴展而來的,用于支持實時流式數據的處理。如圖1-9所示,Spark Streaming對流入的數據進行分批、轉換和輸出。微批處理無法滿足低延遲的要求,只能算是近實時計算。

圖1-9 Spark Streaming處理模型
Structured Streaming是基于Streaming SQL引擎的可擴展和容錯的流式計算引擎。如圖1-10所示,Structured Streaming將流式的數據整體看成一張無界表,將每一條流入的數據看成無界的輸入表,對輸入進行處理會生成結果表。生成結果表可以通過觸發器來觸發,目前支持的觸發器都是定時觸發的,整個處理類似Spark Streaming的微批處理;從Spark 2.3開始引入持續處理。持續處理是一種新的、處于實驗狀態的流式處理模型,它在Structured Streaming的基礎上支持持續觸發來實現低延遲。
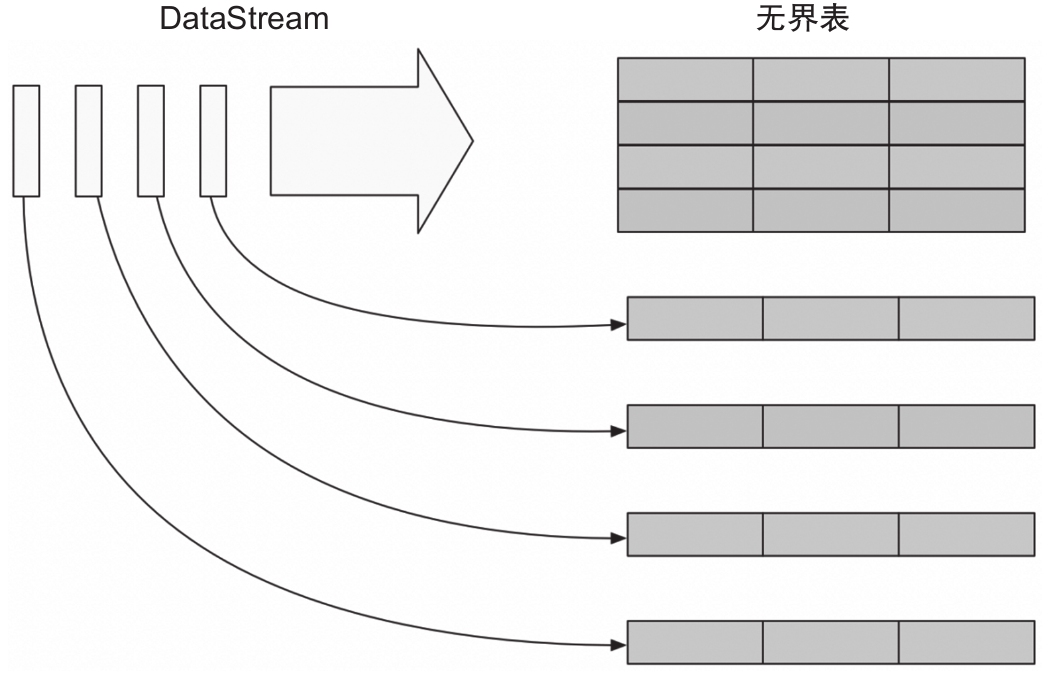
圖1-10 Structured Streaming處理模型
3. Flink
Flink是對有界數據和無界數據進行有狀態計算的分布式引擎,它是純流式處理模式。流入Flink的數據會經過預定的DAG(Directed Acyclic Graph,有向無環圖)節點,Flink會對這些數據進行有狀態計算,整個計算過程類似于管道。每個計算節點會有本地存儲,用來存儲計算狀態,而計算節點中的狀態會在一定時間內持久化到分布式存儲,來保證流的容錯,如圖1-11所示。這種純流式模式保證了Flink的低延遲,使其在諸多的實時計算引擎競爭中具有優勢。
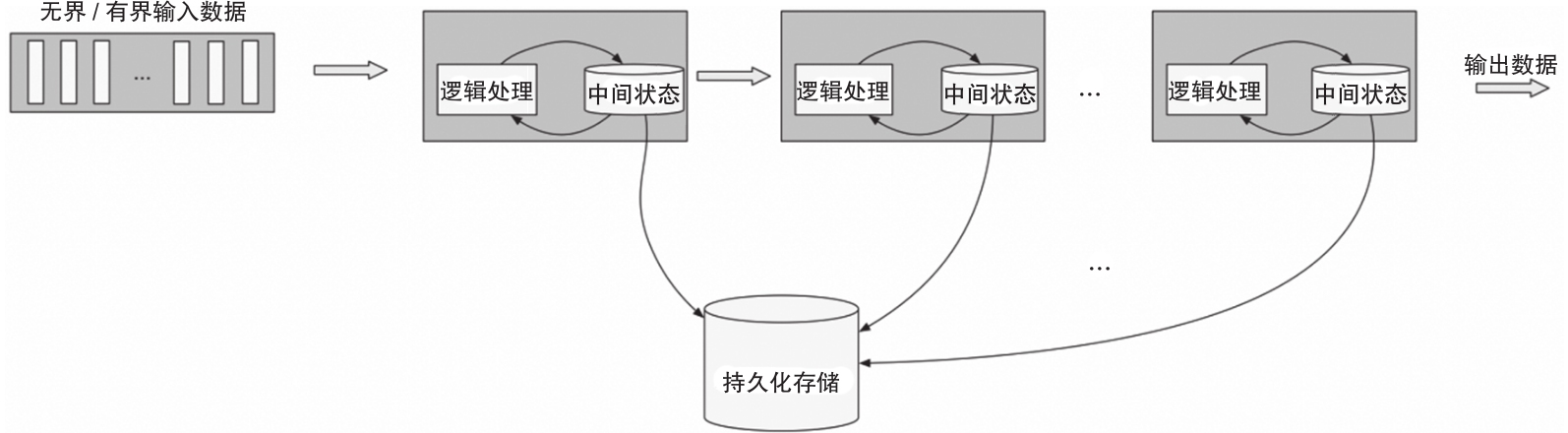
圖1-11 Flink流式處理模型
1.4.2 Flink基本架構
本節從分層角度和運行時角度來介紹Flink基本架構。其中,對于運行時Flink架構,會以1.5版本為分界線對前后版本的架構變更進行介紹。
1. 分層架構
Flink是分層架構的分布式計算引擎,每層的實現依賴下層提供的服務,同時提供抽象的接口和服務供上層使用。整體分層架構如1-12所示。
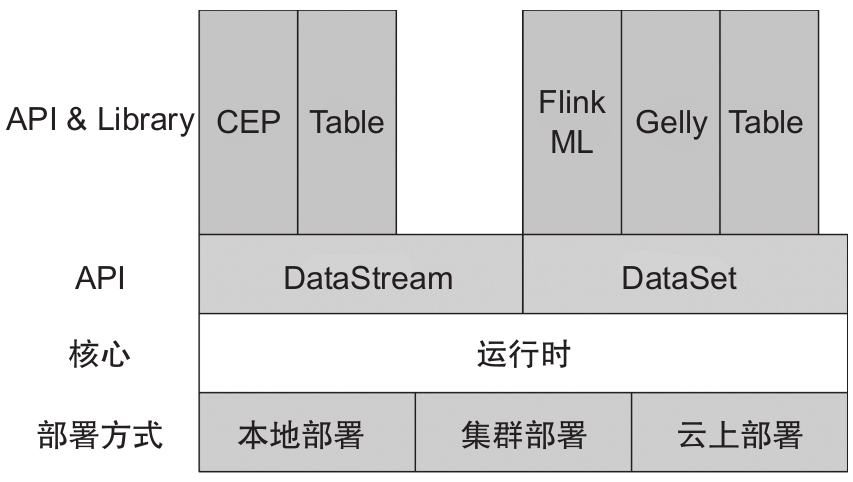
圖1-12 Flink分層架構
- 部署:Flink支持本地運行,支持Standalone集群以及YARN、Mesos、Kubernetes管理的集群,還支持在云上運行。(注:Flink部署模式會在第8章詳細介紹。)
- 核心:Flink的運行時是整個引擎的核心,是分布式數據流的實現部分,實現了運行時組件之間的通信及組件的高可用等。
- API:DataStream提供流式計算的API,DataSet提供批處理的API,Table和SQL API提供對Flink流式計算和批處理的SQL的支持。
- Library:在Library層,Flink提供了復雜事件處理(CEP)、圖計算(Gelly)及機器學習庫。
2. 運行時架構
Flink運行時架構經歷過一次不小的演變。在Flink 1.5版本之前,運行時架構如圖1-13所示。
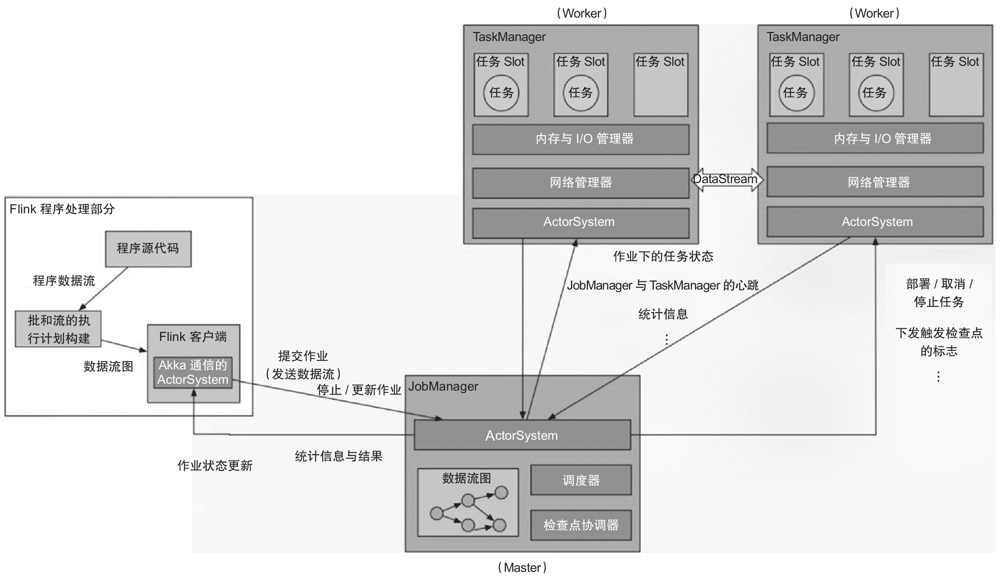
圖1-13 Flink 1.5以前版本的運行時架構
- Client負責編譯提交的作業,生成DAG,并向JobManager提交作業,往JobManager發送操作作業的命令。
- JobManager作為Flink引擎的Master角色,主要有兩個功能:作業調度和檢查點協調。
- TaskManager為Flink引擎的Worker角色,是作業實際執行的地方。TaskManager通過Slot對其資源進行邏輯分割,以確定TaskManager運行的任務數量。
從Flink 1.5開始,Flink運行時有兩種模式,分別是Session模式和Per-Job模式。
- Session模式:在Flink 1.5之前都是Session模式,1.5及之后的版本與之前不同的是引入了Dispatcher。Dispatcher負責接收作業提交和持久化,生成多個JobManager和維護Session的一些狀態,如圖1-14所示。
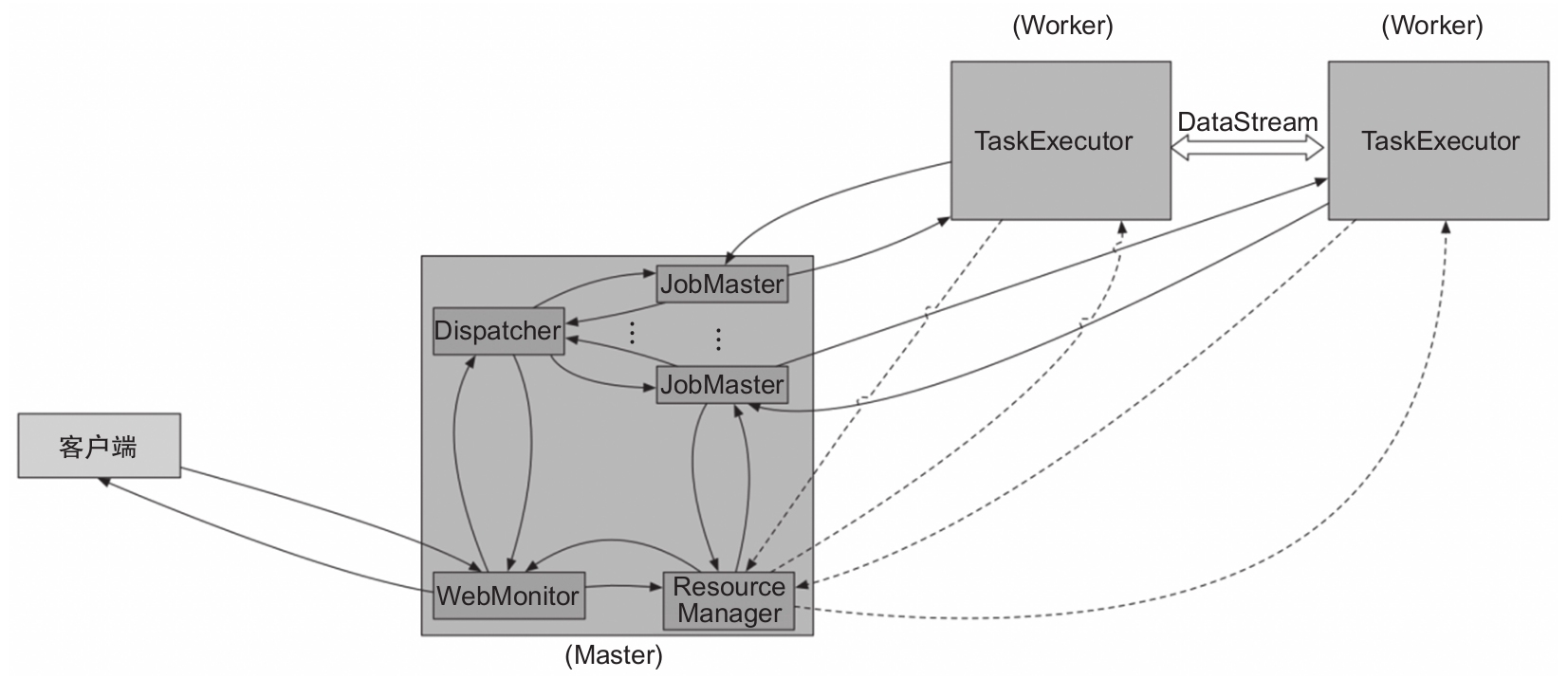
圖1-14 Session模式
- Per-Job模式:該模式啟動后只會運行一個作業,且集群的生命周期與作業的生命周期息息相關,而Session模式可以有多個作業運行、多個作業共享TaskManager資源,如圖1-15所示。
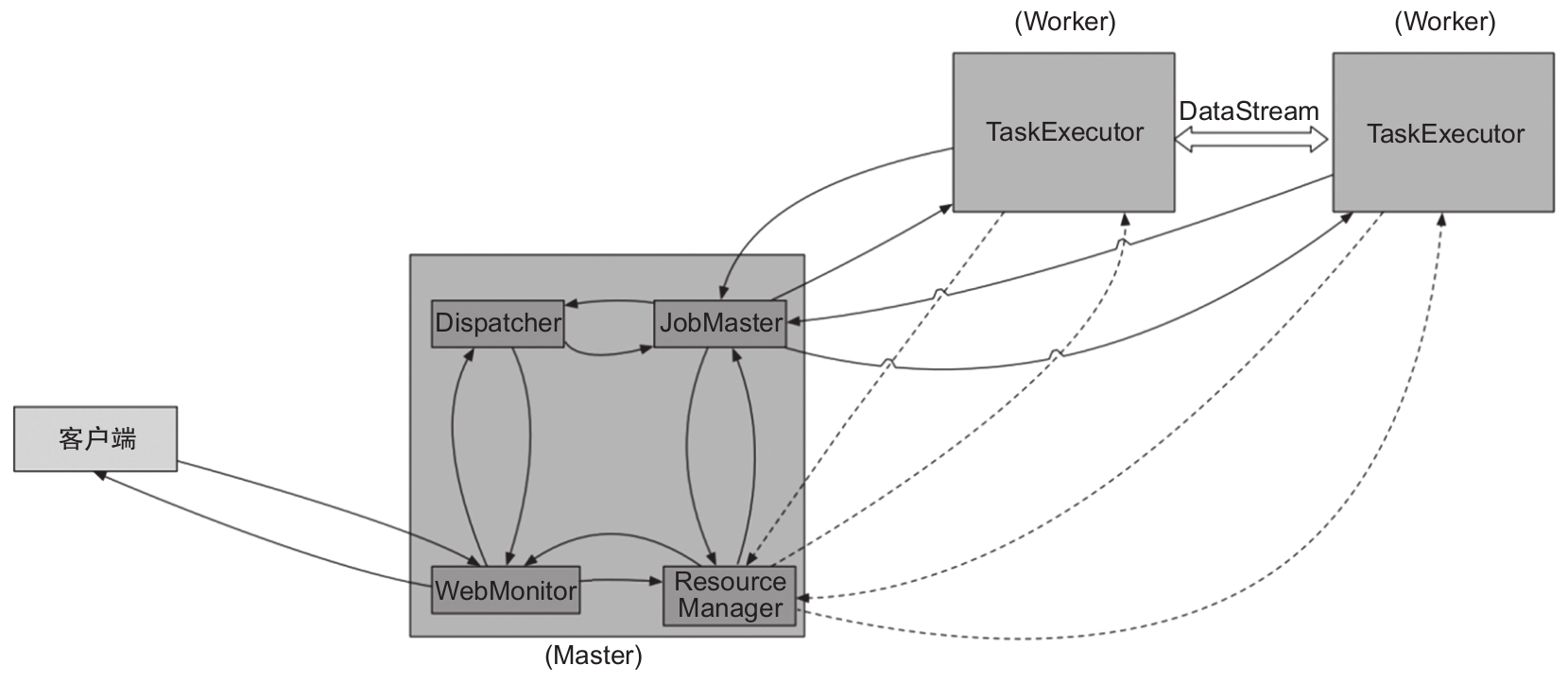
圖1-15 Per-Job模式
- Django+Vue.js商城項目實戰
- C# Programming Cookbook
- Python從菜鳥到高手(第2版)
- PyQt從入門到精通
- Functional Programming in JavaScript
- 新編Premiere Pro CC從入門到精通
- Mastering KnockoutJS
- 數據結構與算法分析(C++語言版)
- Learning Python Data Visualization
- Building UIs with Wijmo
- Java面向對象程序設計教程
- C++ Data Structures and Algorithm Design Principles
- Building Scalable Apps with Redis and Node.js
- Unity與C++網絡游戲開發實戰:基于VR、AI與分布式架構
- Unity AI Game Programming(Second Edition)