- Hands-On Java Deep Learning for Computer Vision
- Klevis Ramo
- 525字
- 2021-07-02 13:25:46
Initializing the weights
We are already aware that we have no weight values at the beginning. In order to solve that problem, we will initialize the weights with random non-zero values. This might work well, but here, we are going to look at how initializing weights greatly impacts the learning time of our neural network.
Suppose we have a deep neural network with many hidden layers, and each of these high layers is connected to two neurons. For the sake of simplicity, we'll not take the sigmoid function but the identity activation function, which simply leaves the input untouched. The value is given by F(z), or simply Z:

Assume that we have weights as depicted in the previous diagram. Calculating the Z at the hidden layer and the neuron or the activation values are the same because of the identity function. The first neuron in the first hidden layer will be 1*0.5+1*0, which is 0.5. The same applies for the second neuron. When we move to the second hidden layer, the value of Z for this second hidden layer is 0.5 *0.5+0.5 *0, which gives us 0.25 or 1/4; if we continue the same logic, we'll have 1/8, 1/16, and so on, until we have the formula 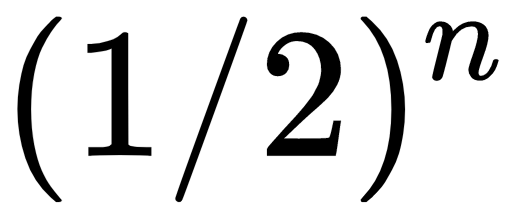 . What this tells us is that the deeper our neural network becomes, the smaller this activation value gets. This concept is also called the vanishing gradient. Originally, the concept referred to the gradient rather than activation values, but we can easily adapt it to gradients and the concept holds the same. If we replace the 0.5 with a 1.5, then we will have
. What this tells us is that the deeper our neural network becomes, the smaller this activation value gets. This concept is also called the vanishing gradient. Originally, the concept referred to the gradient rather than activation values, but we can easily adapt it to gradients and the concept holds the same. If we replace the 0.5 with a 1.5, then we will have 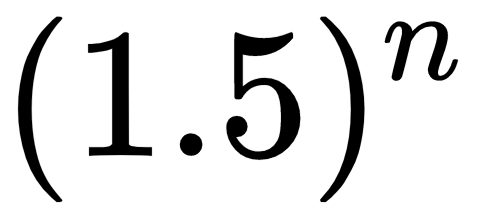 in the end, which tells us that the deeper our neural network gets, the greater the activation function becomes. This is known as the exploding gradient values.
in the end, which tells us that the deeper our neural network gets, the greater the activation function becomes. This is known as the exploding gradient values.
In order to avoid both situations, we may want to replace the zero value with a 0.5. If we do that, the first neuron in the first hidden layer will have the value 1*0.5+1*0.5, which is equal to 1. This does not really help our cause because our output is then equal to the input, so maybe we can slightly modify to have not 0.5, but a random value that is as near to 0.5 as possible.
In a way, we would like to have weights valued with a variance of 0.5. More formally, we want the variance of the weights to be 1 divided by the number of neurons in the previous layer, which is mathematically expressed as follows:

To obtain the actual values, we need to multiply the square root of the variance formula to a normal distribution of random values. This is known as the Xavier initialization:
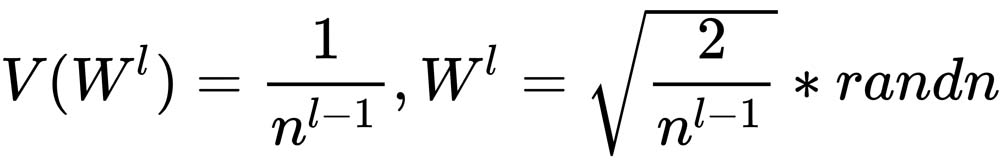
If we replace the 1 with 2 in this formula, we will have even greater performance for our neural network. It'll converge faster to the minimum.
We may also find different versions of the formula. One of them is the following:
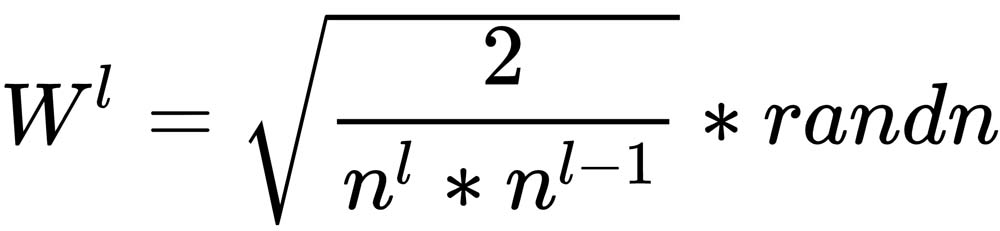
It modifies the term to have the multiplication of the number of neurons in the actual layer with the number of neurons in the previous layer.