- PyTorch 1.x Reinforcement Learning Cookbook
- Yuxi (Hayden) Liu
- 361字
- 2021-06-24 12:34:41
There's more...
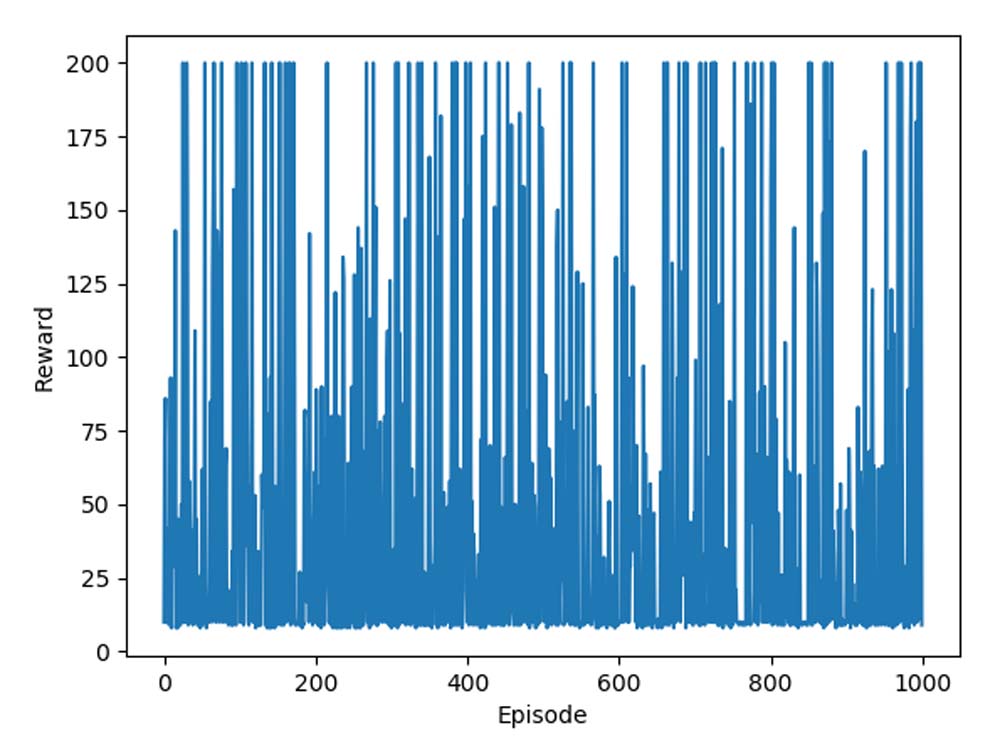
We can also plot the total reward for every episode in the training phase:
>>> import matplotlib.pyplot as plt
>>> plt.plot(total_rewards)
>>> plt.xlabel('Episode')
>>> plt.ylabel('Reward')
>>> plt.show()
This will generate the following plot:
If you have not installed matplotlib, you can do so via the following command:
conda install matplotlib
We can see that the reward for each episode is pretty random, and that there is no trend of improvement as we go through the episodes. This is basically what we expected.
In the plot of reward versus episodes, we can see that there are some episodes in which the reward reaches 200. We can end the training phase whenever this occurs since there is no room to improve. Incorporating this change, we now have the following for the training phase:
>>> n_episode = 1000
>>> best_total_reward = 0
>>> best_weight = None
>>> total_rewards = []
>>> for episode in range(n_episode):
... weight = torch.rand(n_state, n_action)
... total_reward = run_episode(env, weight)
... print('Episode {}: {}'.format(episode+1, total_reward))
... if total_reward > best_total_reward:
... best_weight = weight
... best_total_reward = total_reward
... total_rewards.append(total_reward)
... if best_total_reward == 200:
... break
Episode 1: 9.0
Episode 2: 8.0
Episode 3: 10.0
Episode 4: 10.0
Episode 5: 10.0
Episode 6: 9.0
Episode 7: 17.0
Episode 8: 10.0
Episode 9: 43.0
Episode 10: 10.0
Episode 11: 10.0
Episode 12: 106.0
Episode 13: 8.0
Episode 14: 32.0
Episode 15: 98.0
Episode 16: 10.0
Episode 17: 200.0
The policy achieving the maximal reward is found in episode 17. Again, this may vary a lot because the weights are generated randomly for each episode. To compute the expectation of training episodes needed, we can repeat the preceding training process 1,000 times and take the average of the training episodes:
>>> n_training = 1000
>>> n_episode_training = []
>>> for _ in range(n_training):
... for episode in range(n_episode):
... weight = torch.rand(n_state, n_action)
... total_reward = run_episode(env, weight)
... if total_reward == 200:
... n_episode_training.append(episode+1)
... break
>>> print('Expectation of training episodes needed: ',
sum(n_episode_training) / n_training)
Expectation of training episodes needed: 13.442
On average, we expect that it takes around 13 episodes to find the best policy.
- GNU-Linux Rapid Embedded Programming
- 輕松學(xué)Java
- 數(shù)據(jù)庫(kù)原理與應(yīng)用技術(shù)
- 我也能做CTO之程序員職業(yè)規(guī)劃
- TensorFlow Reinforcement Learning Quick Start Guide
- 電子設(shè)備及系統(tǒng)人機(jī)工程設(shè)計(jì)(第2版)
- Linux Shell編程從初學(xué)到精通
- 傳感器原理與工程應(yīng)用
- Windows 7故障與技巧200例
- 精通ROS機(jī)器人編程(原書第2版)
- Appcelerator Titanium Smartphone App Development Cookbook(Second Edition)
- 大話數(shù)據(jù)科學(xué):大數(shù)據(jù)與機(jī)器學(xué)習(xí)實(shí)戰(zhàn)(基于R語(yǔ)言)
- 深度學(xué)習(xí)實(shí)戰(zhàn)
- Ubuntu 9 Linux應(yīng)用基礎(chǔ)
- 深度剖析:硬盤固件級(jí)數(shù)據(jù)恢復(fù)