- Oracle Exadata性能優化
- 石云華 陳浩 饒冰
- 3900字
- 2020-05-21 18:00:30
1.2 智能掃描前提條件
看完了上面的一些測試數據,是不是有點熱血沸騰的感覺,覺得Exadata的智能掃描特性簡直就是一件“神器”?在這里有必要先潑點涼水,Exadata的智能掃描特性可不是無條件工作的,它必須滿足一定的條件才會觸發。
1.2.1 前提條件
必須滿足什么樣的條件才有可能觸發智能掃描呢?想要讓SQL語句觸發智能掃描,必須先滿足以下3個先決條件。
■ 全掃描。
■ 直接路徑讀取。
■ 數據存放在Exadata上。
先來說說第二個先決條件,為什么一定要直接路徑讀取才能進行智能掃描呢?這其實是由數據訪問時的內部函數調用順序決定的。當一個會話正在進行智能掃描操作時,通過oradebug工具獲取當前正在執行的函數調用,見代碼清單1.9。
代碼清單1.9 智能掃描的函數調用

在代碼清單1.9中,進程號3109所對應的數據庫會話在執行智能掃描時涉及函數調用,其中kcfis_read()函數即智能掃描函數,kcbldrget()函數即直接路徑讀取函數。從函數的調用順序可以看出,kcbldrget()函數發生之后才會調用kcfis_read()函數。所以要想觸發智能掃描,則必須滿足直接路徑讀取條件。
下面詳細講解這3個觸發智能掃描的條件。
1.全掃描
這里所說的“全掃描”不僅是指TABLE ACCESS FULL,還包括INDEX FAST FULL SCAN和BITMAP INDEX FAST FULL SCANS,即智能掃描的先決條件之一是必須“全表掃描”或者“索引快速全掃描”。
在很多介紹Exadata的文檔或書籍中,大多提及的是TABLE ACCESS FULL,這基本上是共識,大家都能認可,但很少有人提及INDEX FAST FULL SCAN和BITMAP INDEX FAST FULL SCANS也有可能觸發智能掃描。
下面示例展示INDEX FAST FULL SCAN也可進行智能掃描操作。首先將隱含參數_very_large_object_threshold的值設置為1(至于為什么設置_very_large_object_threshold隱含參數,后文會單獨進行講解),然后在會話級別開啟autotrace觀察SQL語句的執行計劃,見代碼清單1.10。
代碼清單1.10 驗證索引快速全掃描也能智能掃描(1)

從以上的代碼輸出可以看出,該SQL語句使用的是索引快速全掃描(INDEX STORAGE FAST FULL SCAN)方式,掃描的索引名為IDX_TEST_OBJECT_ID,執行完該語句花費的時間為3.94s。
執行該SQL語句的同時,對該SQL語句設置10046事件,然后使用tkprof工具來格式化10046事件生成的日志。
代碼清單1.10 驗證索引快速全掃描也能智能掃描(2)
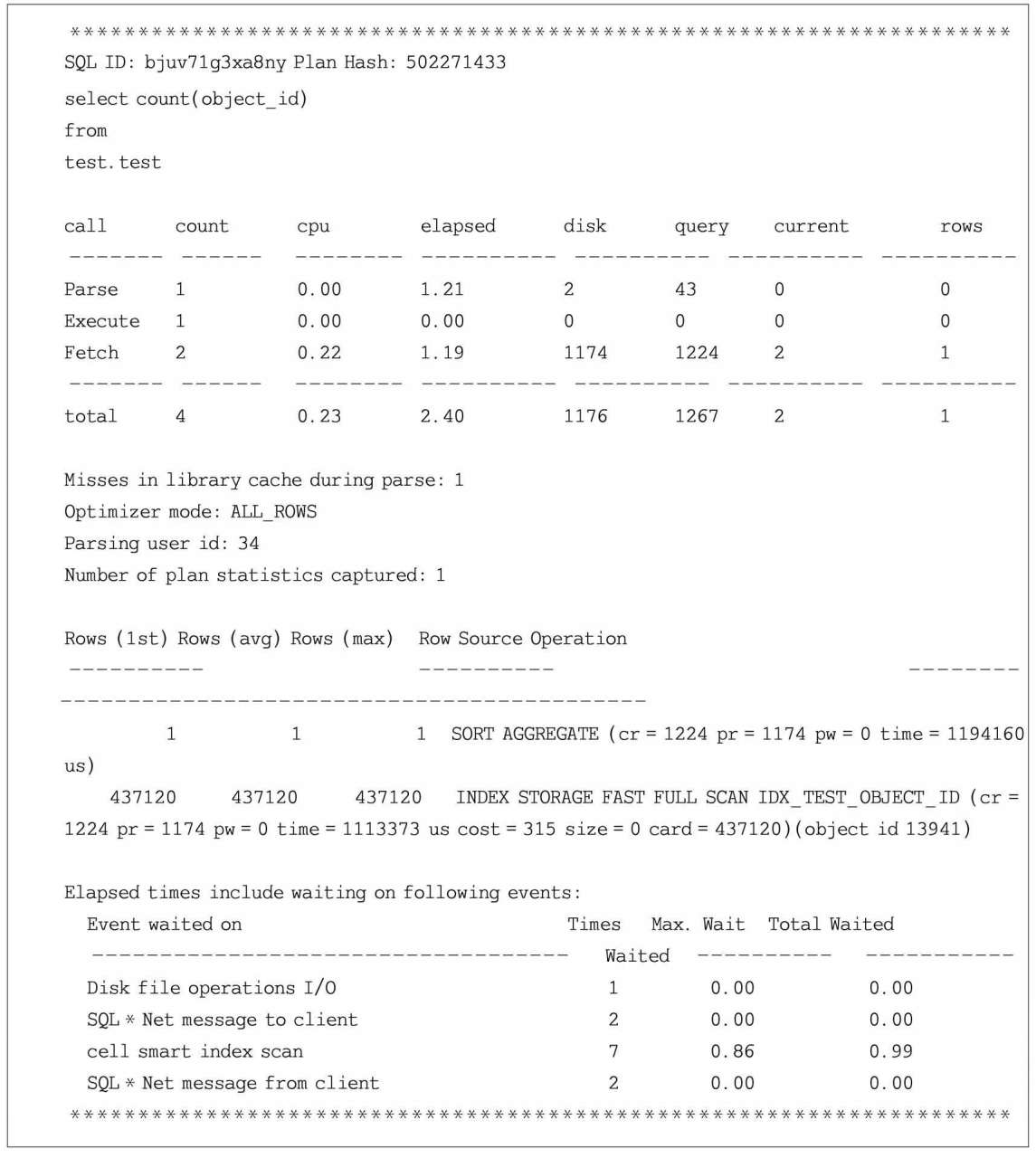
從該SQL語句格式化后的10046事件日志可以看出,該SQL語句使用INDEX STORAGE FAST FULL SCAN索引掃描,對應的主要等待事件為cell smart index scan,說明該SQL語句進行了智能掃描操作。
相同的SQL語句在禁用智能掃描的情況下,執行效率會有什么變化?下面繼續進行測試工作。在以下代碼中,通過在會話級別設置_serial_direct_read隱含參數為never(意味著強制關閉直接路徑讀取,也即強制SQL語句禁止使用智能掃描),來觀察相同的SQL語句此刻的等待事件及執行效率有哪些變化。
代碼清單1.10 驗證索引快速全掃描也能智能掃描(3)

從以上代碼輸出可以看出,在會話級別設置隱含參數_serial_direct_read=never,手動強制不允許該相同的SQL語句采用直接路徑讀取,也即禁用智能掃描,此時該語句花費了17s才運行完成。
在執行該SQL語句的同時,同樣對該SQL語句設置10046事件,然后使用tkprof工具來格式化10046事件生成的日志。
代碼清單1.10 驗證索引快速全掃描也能智能掃描(4)
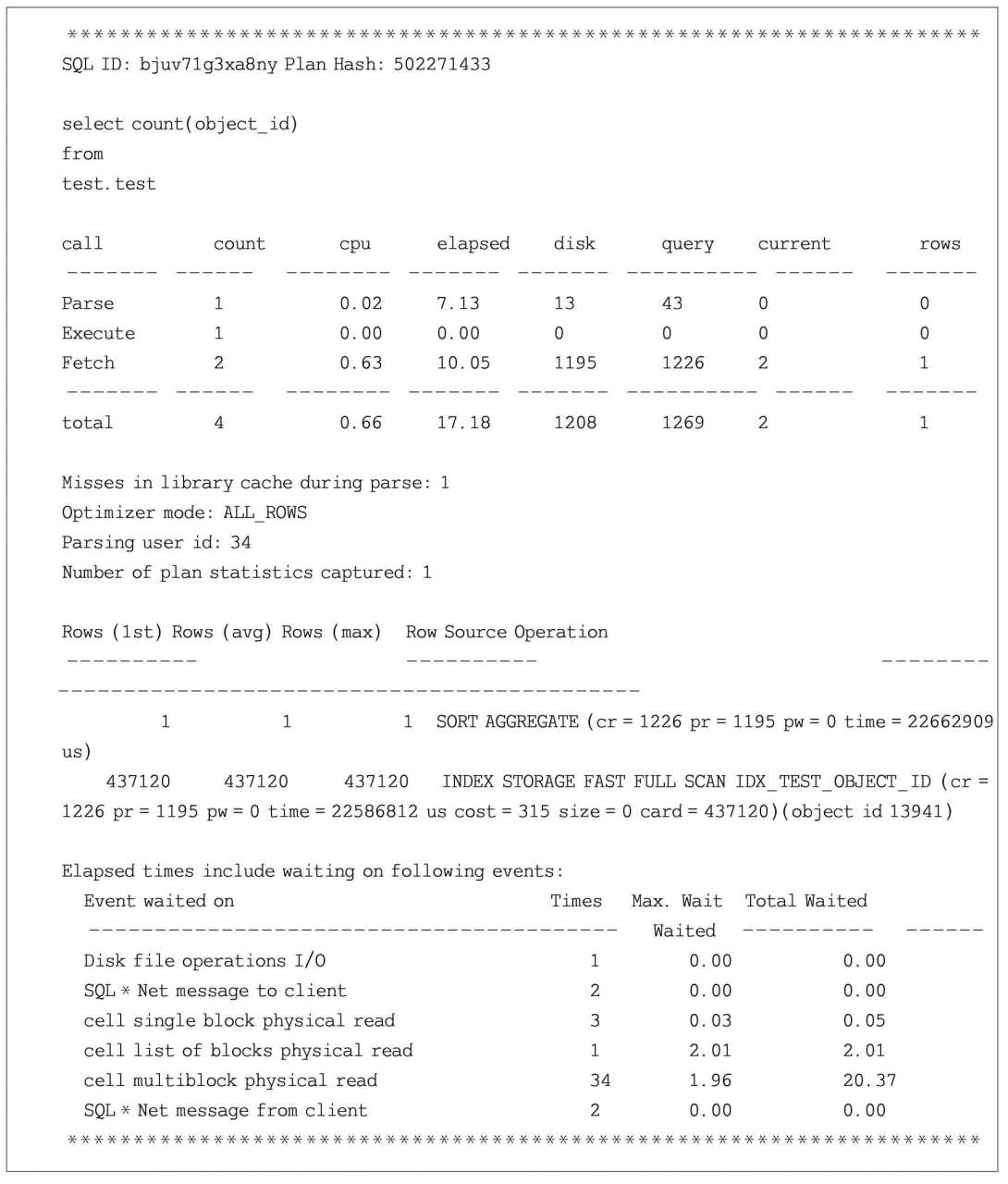
可見,在禁用智能掃描時,該SQL語句的主要等待事件為cell multiblock physical read,同時伴隨著cell single block physical read,但沒有cell smart index scan。
相同的SQL語句,僅僅是設置了不同的系統參數,故意讓第一次執行時使用智能掃描,而第二次執行時不使用智能掃描,兩次的執行效率出現明顯的變化,具體如下所示。
代碼清單1.10 驗證索引快速全掃描也能智能掃描(5)

第一次執行時,進行了智能掃描操作,節省了75%的IO,平均執行時間為3s,而第二次執行時,沒有進行智能掃描操作,沒有節省任何IO操作,平均執行時間高達20s。
有些資料或書籍中提到,執行計劃為index full scan時也能進行智能掃描操作。下面通過具體的示例來驗證這一觀點是否正確,見代碼清單1.11。
代碼清單1.11 驗證索引全掃描不能智能掃描



從以上示例可以看出,當SQL語句的執行計劃進行INDEX FULL SCAN掃描時,即使設置了強制直接路徑讀取,SQL語句也無法進行智能掃描操作,也即INDEX FULL SCAN不滿足觸發智能掃描的條件。
關于INDEX FULL SCAN和INDEX FAST FULL SCAN的區別,在本書中不再進行詳細講解,有興趣的讀者可查閱相關資料。
2.直接路徑讀取
智能掃描除了要求全掃描操作之外,還要求執行讀操作時必須采用Oracle的直接路徑讀取機制。
在Oracle 11g版本之前,并行查詢的子進程默認使用的就是直接路徑讀取機制。Oracle推出并行查詢功能的初衷,是想通過它訪問數量龐大的數據,而這么多的數據不適合存放在SGA的BufferCache中,因此并行服務器將數據直接讀入PGA,從而繞過了SGA。
從Oracle 11g開始,串行執行的SQL語句也同樣有可能采用直接路徑讀取機制了。對Exadata而言,這是個大好消息,最直接的改變就是智能掃描時不一定要求SQL語句開并行。而對傳統架構的Oracle數據庫而言,這種算法的改變就顯得稍稍有點激進了。在很多傳統架構的Oracle數據庫中,可能會遇到直接路徑讀取導致IO耗盡,數據庫性能急劇下降的情況。例如,從數據庫的AWR報告中可以看出性能急劇下降階段,direct path read等待事件對數據庫性能的影響非常嚴重,如圖1.6所示。
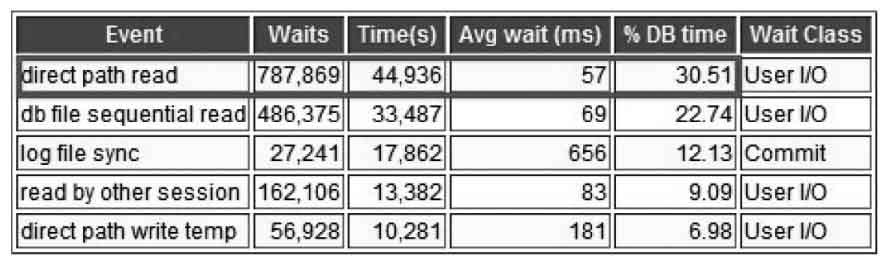
圖1.6 direct path read等待事件影響數據庫性能
因此,在傳統架構的Oracle數據庫中,基本上都會設置10949事件,來關閉掉Oracle 11g數據庫中串行直接路徑讀取的新特性。具體命令如下。

3.Exadata存儲
Exadata智能掃描的前提條件,除了前面提到的“全掃描”和“直接路徑讀取”之外,還有一個必要的條件,就是數據必須存儲在Exadata的存儲服務器上,如果數據存放在外掛的非Exadata的存儲服務器所創建的磁盤組上,則不會進行智能掃描。
其實,除了數據必須存儲在Exadata的存儲服務器上之外,還需要將ASM磁盤組的cell.smart_scan_capable屬性參數設置成true。由于在Exadata環境中該屬性的默認值就是true,所以簡單來講,就是要求數據必須存儲在Exadata的存儲服務器上,見代碼清單1.12。
代碼清單1.12 查詢ASM磁盤組的cell.smart_scan_capable屬性參數值
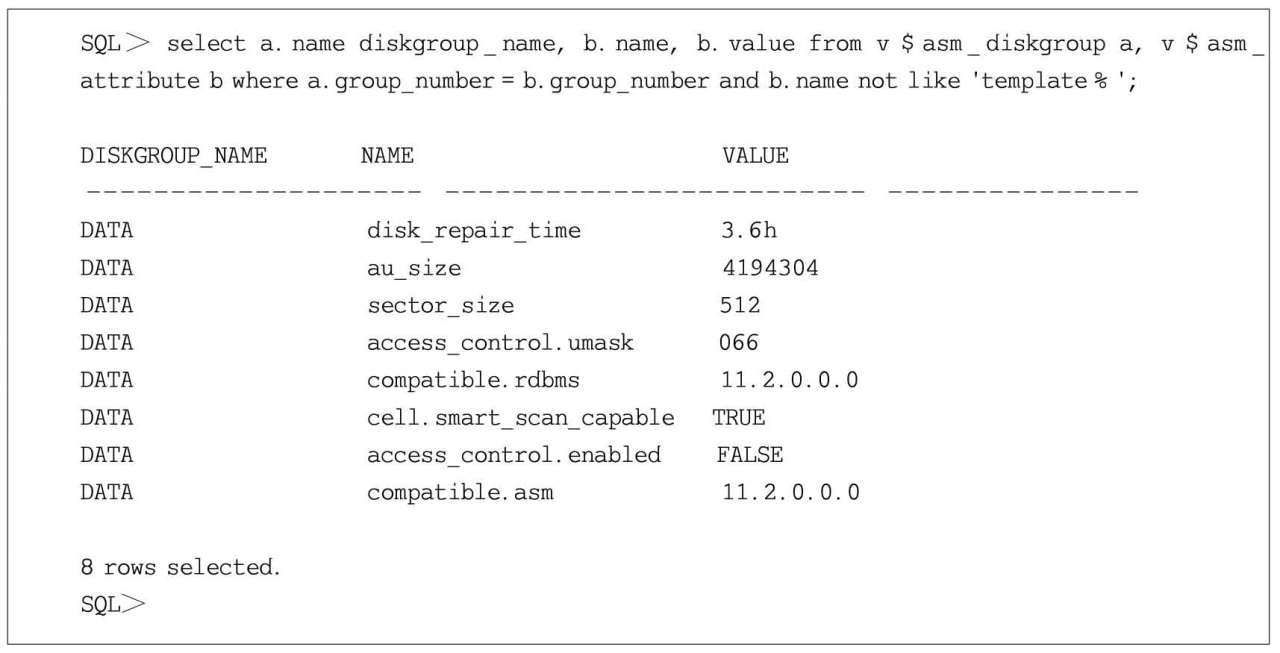
下面通過示例展示ASM磁盤組的cell.smart_scan_capable屬性對智能掃描操作的影響,見代碼清單1.13。
代碼清單1.13 ASM磁盤組的cell.smart_scan_capable屬性對智能掃描操作的影響(1)

只有當ASM磁盤組的cell.smart_scan_capable屬性為默認的true時,SQL語句才有可能進行智能掃描。從以上代碼輸出可以看出,執行這條SQL語句花費了6s。
下面將ASM磁盤組的cell.smart_scan_capable屬性設置為false,然后在相同的會話執行相同的SQL語句。這里在SQL語句中稍稍做了點變動,這點變動不會造成執行計劃的變化,影響執行的結果集,但會重新進行編譯,生成另外一個SQL_ID,目的是展示ASM磁盤組的cell.smart_scan_capable屬性變化所帶來的影響。
代碼清單1.13 ASM磁盤組的cell.smart_scan_capable屬性對智能掃描操作的影響(2)

從以上代碼輸出可以看出,執行相同的SQL語句,當ASM磁盤組的cell.smart_scan_capable屬性設置為false后,運行時間從以前的6s增長到現在的33s。
查詢這兩條SQL語句是否發生過智能掃描。
代碼清單1.13 ASM磁盤組的cell.smart_scan_capable屬性對智能掃描操作的影響(3)

從以上代碼輸出可以看出,當ASM磁盤組的cell.smart_scan_capable屬性設置為false后,本來應該智能掃描的SQL語句已經無法進行智能掃描操作了。
1.2.2 滿足條件但不觸發智能掃描
在此要說明的是,前面介紹的智能掃描的三大先決條件,并不是充分條件,在某些情況下,即使滿足了以上的三大條件,也有可能不觸發智能掃描特性。滿足條件但不觸發智能掃描的情景具體如下。
■ 數據庫參數CELL_OFFLOAD_PROCESSING被設置為false。
■ 正在掃描的表或分區太小。
■ 優化器沒有使用直接路徑讀取。
■ 在cluster表上執行掃描。
■ 在索引組織的表上執行掃描。
■ 對壓縮的索引執行快速全掃描。
■ 對反轉索引執行快速全掃描。
■ 該表已啟用行依賴關系或正在提取rowscn。
■ 優化器掃描希望以ROWID順序返回行。
■ CREATE INDEX命令使用了nosort選項。
■ 正在選擇或查詢LOB或LONG列。
■ 對表執行版本查詢的flashback操作。
■ 查詢非混合列壓縮的表對象時,訪問的列個數超過了255。
■ 表空間被加密,并且CELL_OFFLOAD_DECRYPTION參數被設置為false。為了使Exadata存儲單元執行解密,Oracle數據庫需要將解密密鑰發送到Exadata存儲單元。如果將密鑰通過網絡發送到Exadata存儲單元時存在安全問題,那么會禁用存儲節點解密功能。
■ 表空間并未完全存儲在Oracle Exadata存儲服務器上。
■ 謂詞評估是在一個虛擬的列上。
上述不觸發智能掃描的十幾種情景來自于Exadata官方文檔。除了Exadata官方文檔中提及的情況之外,MOS文檔Exadata Smart Scan FAQ(Doc ID 1927934.1)中另外提及了其他幾種不會觸發智能掃描特性的情況,具體如下。
■ 被訪問的表設置了cache屬性。
■ 隱含參數_serial_direct_read被設置成never。
■ 串行的DML語句。
■ SQL語句被設置了隔離。
■ 共享模式的會話發起的串行SQL查詢語句。
■ table函數中的SQL查詢語句。
■ dbms_sql包中的SQL查詢語句。
■ PL/SQL觸發器中的SQL查詢語句。
■ 存儲節點的CPU使用率非常高。
下面通過示例來驗證表對象設置了cache屬性對智能掃描特性的影響,見代碼清單1.14。
代碼清單1.14 驗證表對象設置了cache屬性對智能掃描特性的影響(1)

這段代碼的含義是當表test.test未設置cache屬性時,計算data_object_id字段的平均值花費了4.81s;然后對表設置cache屬性,再次計算data_object_id字段的平均值時,仍然花費了4.33s。
代碼清單1.14 驗證表對象設置了cache屬性對智能掃描特性的影響(2)

獲取兩條SQL語句的SQL_ID,查詢發現兩條SQL語句都執行了智能掃描,所以花費的時間相當。
這個測試示例與官方的說法有些出入,在進一步說明之前,先來熟悉一下表對象cache屬性的工作原理:當使用全表掃描時,則該表中的數據塊會放置在LRU列表的最近最少使用的尾部(LRU端),因此很快就被淘汰出局。如果表設置了cache屬性,即使對該表使用全表訪問,該表對象的塊仍然被放置在LRU列表最近最多使用的尾部(MRU段)。
注意:設置了cache屬性的對象,并不是立刻就將該對象所涉及的數據塊keep到內存里,而只是盡可能地延長該對象駐留內存的時間。它將數據塊存放在BufferCache中的default子池中。如果將一張表保留到存放在BufferCache中的keep子池中,則該表的數據塊基本上會永久駐留在內存里,除非數據庫重啟,或新keep到內存的數據將以前的數據塊擠出。
在設置cache屬性時,并不會立即將數據塊緩存到內存中,所以它并不能立即阻止智能掃描。設置cache屬性,僅僅是數據塊更趨于緩存到內存中,在內存中緩存的時間更久。只有當內存中緩存的數據塊達到一定的數量,才有可能會阻止智能掃描,詳情參見1.4節。同樣,如果將對象駐留到keep子池也是一樣的道理,只有當內存中緩存的數據塊達到一定的數量,才會阻止智能掃描。因此,“被訪問的表設置了cache屬性就會導致無法智能掃描”這種說法并不是十分嚴謹。
- Learning LibGDX Game Development(Second Edition)
- Learn Type:Driven Development
- Java面向對象程序開發及實戰
- UML+OOPC嵌入式C語言開發精講
- C語言程序設計案例式教程
- Responsive Web Design by Example
- Extreme C
- App Inventor創意趣味編程進階
- C# and .NET Core Test Driven Development
- 代碼閱讀
- Oracle實用教程
- 零基礎學Scratch 3.0編程
- 從零開始學Android開發
- Instant Zurb Foundation 4
- PostgreSQL Developer's Guide