- Oracle Exadata性能優化
- 石云華 陳浩 饒冰
- 3811字
- 2020-05-21 18:00:30
1.1 什么是智能掃描
在介紹智能掃描特性之前,先簡單了解一下Exadata中的數據卸載功能。數據卸載功能包括的特性非常多,比如智能掃描、智能文件創建、RMAN智能數據文件還原、智能增量備份等。智能掃描,也稱為Smart Scan,是Exadata中數據卸載功能的一個子集。它同時又包含了多個子特性,比如行過濾、列映射、存儲索引、布隆過濾(Bloom Filters)等。整個Exadata的數據卸載功能可以用圖1.1進行簡要概括。
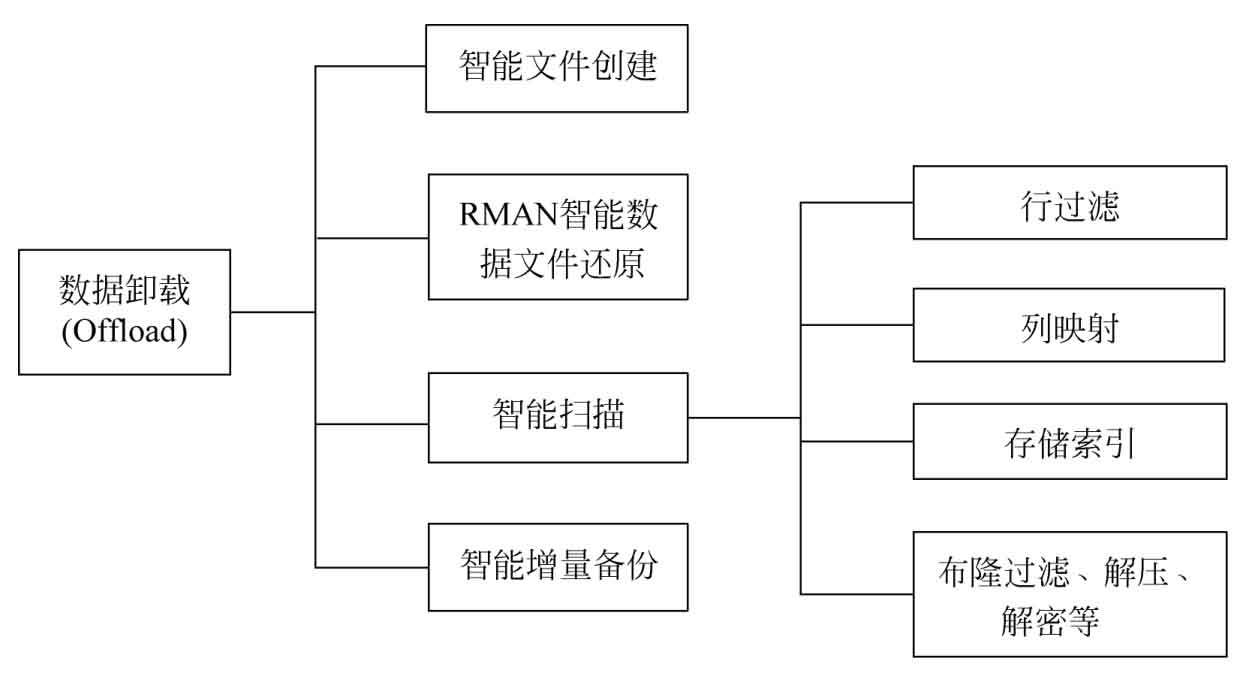
圖1.1 Exadata數據卸載功能
在講解Exadata智能掃描特性之前,先來對“傳統架構”的SQL處理和“Exadata智能掃描架構”的SQL處理做一對比。“傳統架構”的SQL處理流程如圖1.2所示。
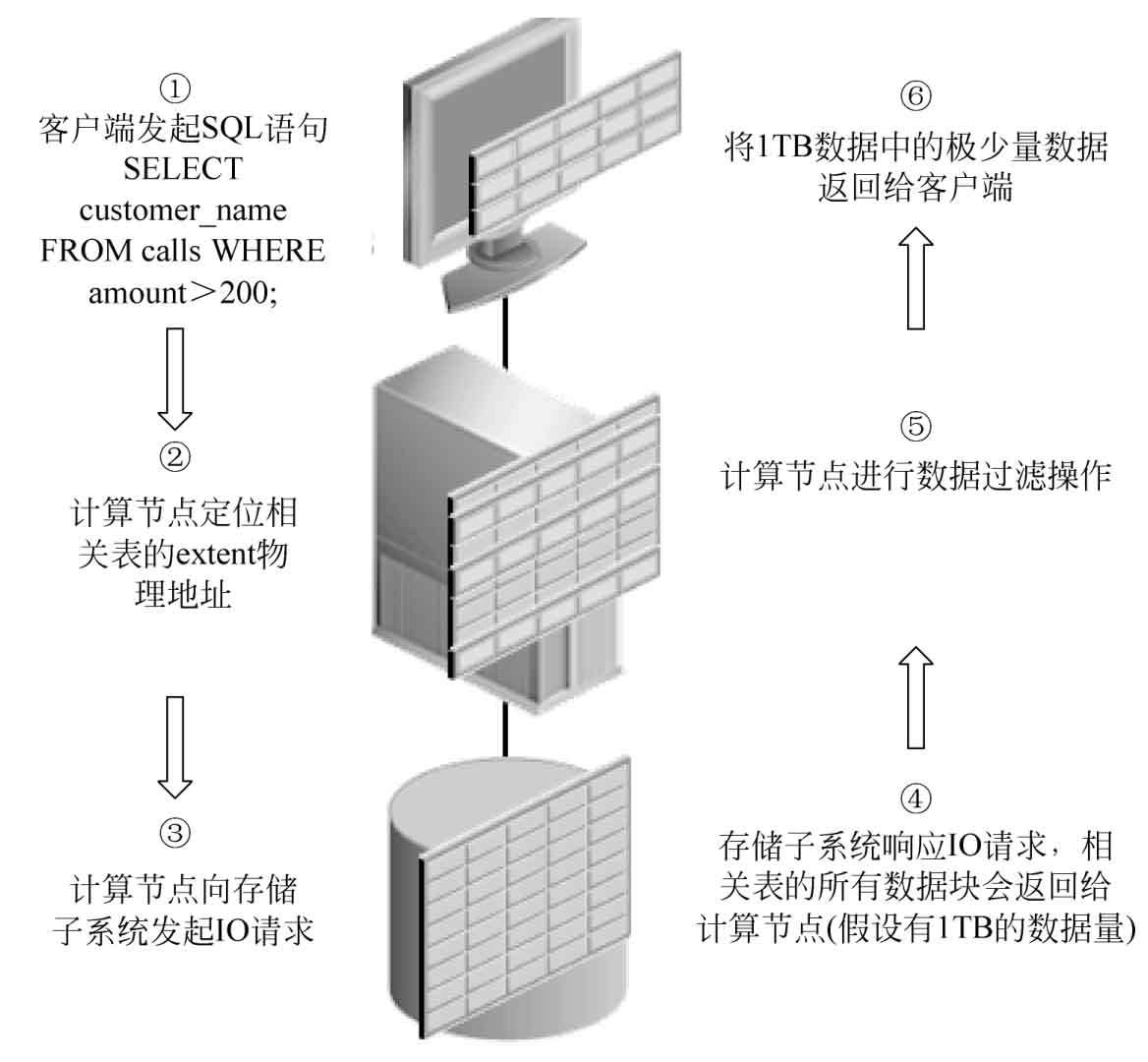
圖1.2 “傳統架構”的SQL處理流程
“傳統架構”整個SQL語句的處理流程簡要描述如下。
(1)客戶端向數據庫服務器發起具體的SQL語句請求,查詢在一次通話過程中花費超過了200元的優質顧客。(當然,這樣的顧客只是極少數。)
(2)對傳統架構而言,數據庫服務器必須標識出包含請求的數據的所有數據區存放位置。
(3)數據庫服務器向傳統存儲子系統發出IO掃描請求。
(4)傳統存儲子系統開始向數據庫服務器返回所有的IO請求。
(5)數據庫服務器進行數據處理,并且會丟棄不滿足需求的數據。
(6)將滿足條件的數據行返回給客戶端。
從“傳統架構”的SQL處理流程中可以看出,存儲子系統傳輸了大量的數據塊給數據庫服務器,但傳輸的這部分數據中,絕大部分是結果集不需要的數據,數據庫服務器在后期的數據處理過程中還是會丟棄這部分不需要的數據。
這種模式無形中就造成了極大的IO資源浪費。那么是否可以只傳輸需要的數據給數據庫服務器呢?基于這個理念,所以有了現在的Exadata。
“Exadata智能掃描架構”的SQL處理流程如圖1.3所示。
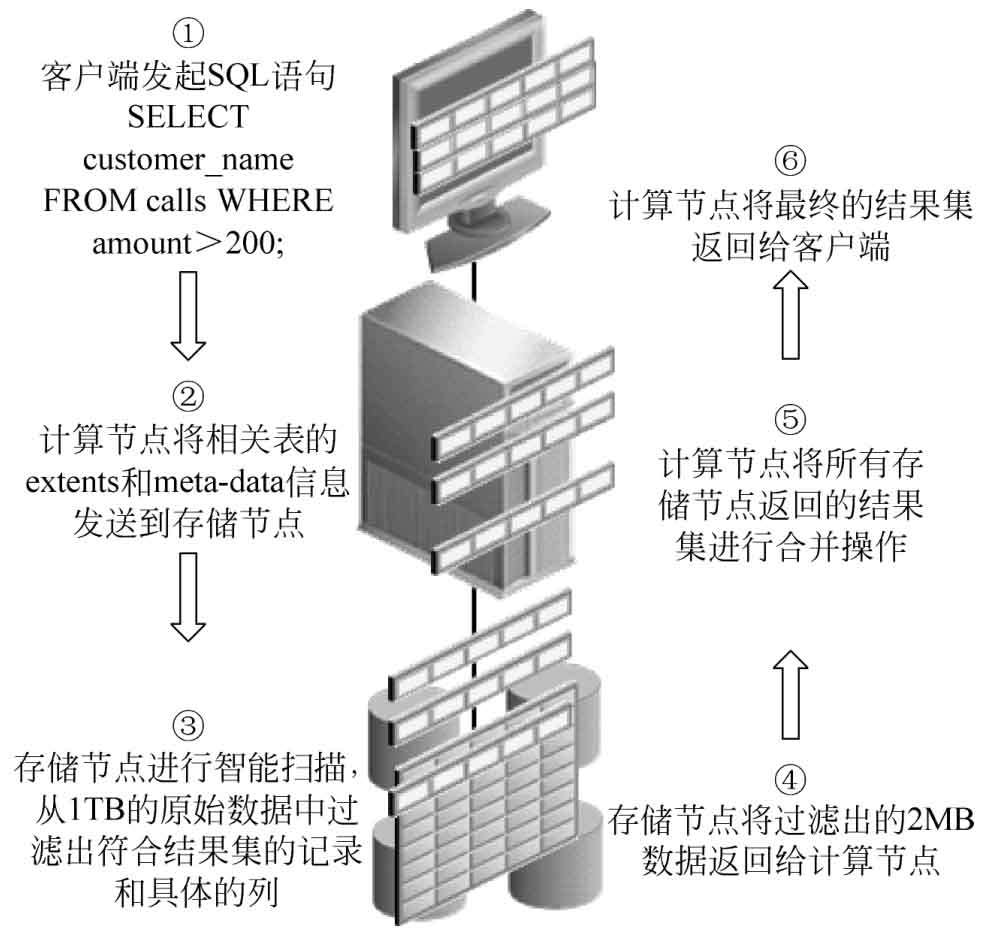
圖1.3 “Exadata智能掃描架構”的SQL處理流程
“Exadata智能掃描架構”整個SQL語句的處理流程簡要描述如下。
(1)客戶端同樣地向數據庫服務器發起具體的SQL語句請求,查詢在一次通話過程中花費超過了200元的優質顧客。(當然,這樣的顧客只是極少數。)
(2)對Exadata智能掃描架構而言,數據庫服務器會標識出可能包含請求的數據的所有數據區存放位置,同時會將所有數據區存放位置和元數據信息通過IDB協議傳送給存儲節點(這里所謂的元數據信息指的是表名、列名、過濾條件等一系列信息),因為真正的數據過濾處理工作是在存儲節點完成的。
(3)存儲服務器進行智能掃描工作,掃描第二步中數據庫服務器定位的數據區存放位置中的所有數據塊,同時根據第二步中的元數據信息進行數據處理和過濾工作,最終得到相應結果集的數據行記錄和相應的列。
(4)存儲服務器將最終得到的相應結果集的數據行記錄和相應的列傳輸給數據庫服務器。如果存儲服務器使用了智能掃描的方式掃描數據,則向數據庫服務器返回的是結果集,也即數據行和列信息,而不是數據塊。
(5)數據庫服務器會整合所有存儲節點返回的數據行記錄和相應的列,形成最終的結果集。
(6)將最終的結果集返回給客戶端。
從“Exadata智能掃描架構”的SQL處理流程中可以看出,所有的數據過濾工作都在存儲服務器上完成,存儲服務器只將相應的結果集數據傳輸給數據庫服務器,也即無用的數據不會傳輸至數據庫。這種方式極大地減輕了IO傳輸的壓力。
注意:①傳統存儲子系統向數據庫服務器返回的是數據塊,而Exadata的智能掃描向數據庫服務器返回的是結果集;②Exadata上并不是所有的SQL語句都會觸發智能掃描,當某條SQL語句沒有觸發智能掃描時,則該SQL語句的整個數據處理流程會變成“傳統架構”的SQL處理流程,此時向數據庫服務器返回的是數據塊。
1.1.1 行過濾
行過濾是智能掃描的一個重要子特性,也稱為“謂詞過濾”。顧名思義,只要發起的SQL語句中帶有where條件,則where條件部分就是謂詞。在進行智能掃描時,只會把滿足where條件的部分行記錄傳輸給數據庫服務器進行后期的數據處理,如圖1.4所示。
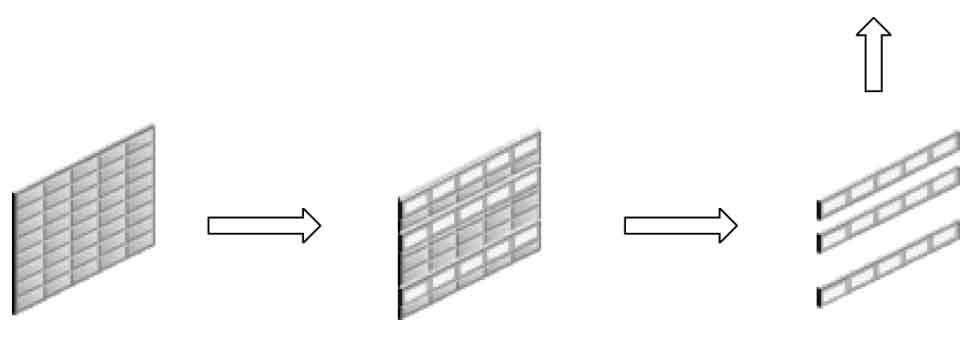
圖1.4 行過濾子特性
下面通過示例來體會智能掃描的行過濾子特性的優越表現,見代碼清單1.1。首先通過將數據庫參數cell_offload_processing設置成false的方式來關閉智能掃描特性,同時觀察SQL語句的執行時間。
代碼清單1.1 驗證智能掃描的行過濾子特性(1)

從以上的代碼輸出可以看出,在關閉智能掃描特性的前提下,該SQL語句運行了15分鐘27秒。
下面開啟智能掃描特性,同時關閉智能掃描特性中的存儲索引子特性,再來觀察相同SQL語句的執行時間是否發生變化。
代碼清單1.1 驗證智能掃描的行過濾子特性(2)

在以上的代碼中,清空了數據庫的BufferCache,防止數據緩存干擾測試結果;同時將數據庫隱含參數_kcfis_storageidx_disabled設置為true,表示禁用智能掃描的存儲索引子特性。可以看到,此時只運行了20s。
代碼清單1.1 驗證智能掃描的行過濾子特性(3)

通過以上代碼,觀察相同的SQL語句在智能掃描特性關閉和開啟時的表現。以上代碼輸出的OFFLOAD列表示該SQL語句是否進行了智能掃描。可以看出,SQL_ID為299fdyckwygkh的這條SQL語句在第一次關閉智能掃描特性的情況下,運行了927s,沒有節省任何IO;而在第二次開啟智能掃描并同時關閉存儲索引子特性的情況下(關閉存儲索引和清空數據庫BufferCache的作用是盡可能地減少其他特性對測試結果的影響,在此重點關注智能掃描中的“行過濾”特性對SQL語句性能的提升),相同的SQL語句只運行了20s。在智能掃描時,存儲節點過濾掉了99.95%的IO,這些無用的IO沒有返回給計算節點,所以節省了大量的時間。
1.1.2 列映射
列映射同樣也是智能掃描的一個重要子特性,在進行智能掃描時,只會把SQL語句中的查詢列和關聯列傳輸給數據庫服務器進行后期的數據處理。所謂查詢列,是指SQL語句中select關鍵字和from關鍵字之間的這一部分具體的列;而關聯列,是指多表關聯查詢時,關聯條件中所涉及的列。
列映射的處理過程如圖1.5所示。例如,某張表中有A、B、C、D、E5個字段,但SQL語句只要求B、D2個字段的信息,此時如果存儲服務器進行智能掃描,則只會把B和D2列的信息傳輸給數據庫服務器。
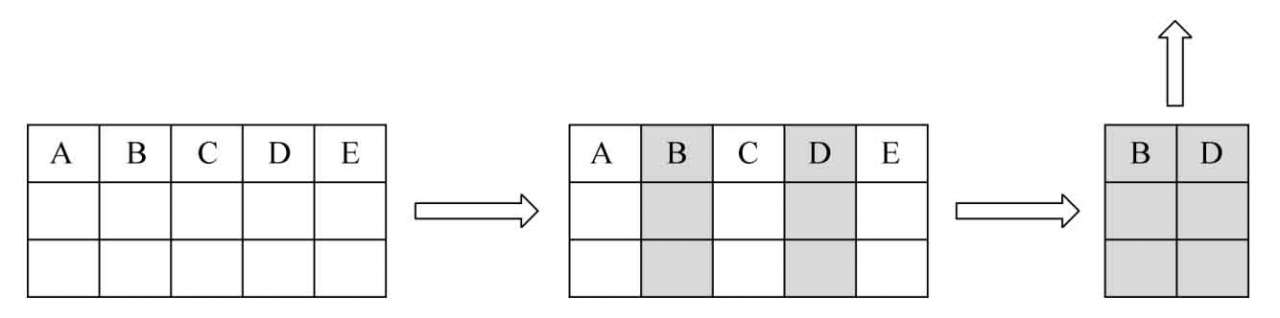
圖1.5 列映射子特性
下面通過示例來體會智能掃描的列映射子特性的優越表現,見代碼清單1.2。
代碼清單1.2 驗證智能掃描的列映射子特性(1)

在觸發智能掃描的前提下,查詢test.test表的id和salary 2列的平均值,花費的時間為20s。
再次查詢相同的表,但只查詢id這一列的平均值,觀察執行時間。
代碼清單1.2 驗證智能掃描的列映射子特性(2)

在觸發智能掃描的前提下,查詢test.test表的id列的平均值花費的時間為12s。
下面觀察智能掃描的列映射子特性的表現。
代碼清單1.2 驗證智能掃描的列映射子特性(3)

從以上輸出可以看出,兩條SQL語句的智能掃描特性已經全部生效,“查詢id和salary兩列的平均值”這條SQL語句用時20s,“查詢id這一列的平均值”這條SQL語句用時12s。這兩條SQL語句都沒有觸發行過濾子特性和存儲索引子特性。之所以“查詢id這一列的平均值”這條SQL語句用時比“查詢id和salary兩列的平均值”這條SQL語句花費的時間少,是因為前者只會返回id這一列的數據到計算節點,而后者需要返回id和salary兩列的數據到計算節點,也即SQL語句中指定的列越少,需要返回給計算節點的數據量就越少。
強調一點,SQL語句在進行智能掃描時,where條件中的非關聯列不會傳輸到數據庫服務器。下面通過示例體會這一點細微的區別,見代碼清單1.3。
代碼清單1.3 智能掃描的列映射不涉及謂詞部分

以上示例的代碼輸出中,A表的object_id字段與B表的object_id字段進行關聯,同時A表的owner字段作為其中的一個過濾條件,最終對A表的data_object_id字段求和。從代碼清單1.3可以看出,dbms_xplan.display_cursor()函數的輸出中Column Projection Information部分,也即智能掃描的列映射相關信息,僅僅提及了A表的object_id字段、data_object_id字段和B表的object_id字段,而作為過濾條件的owner字段并不在列映射的范圍之內,這也間接地說明了where條件中的非關聯列不會傳輸到數據庫服務器。
1.1.3 布隆過濾
布隆過濾(Bloom Filter)是1970年由Burton Howard Bloom提出的,可以用來檢索一個元素是否在一個數據集合中。布隆過濾并不是Exadata特有的特性,在Oracle 10gR2版本中布隆過濾第一次被使用,此時主要用于優化并行操作,減少并行子進程之間通信時的數據傳輸;到了11gR1版本時,布隆過濾特性開始支持多表關聯時的裁剪。
在Exadata環境下,布隆過濾器被作為一個附加的謂詞傳遞到存儲服務器,存儲服務器內部會處理這個布隆過濾器,只將滿足條件的數據傳輸到計算節點進行數據關聯操作,間接地提升SQL語句的查詢性能。
下面通過示例來體會布隆過濾特性帶來的性能提升,見代碼清單1.4。
代碼清單1.4 開啟布隆過濾特性
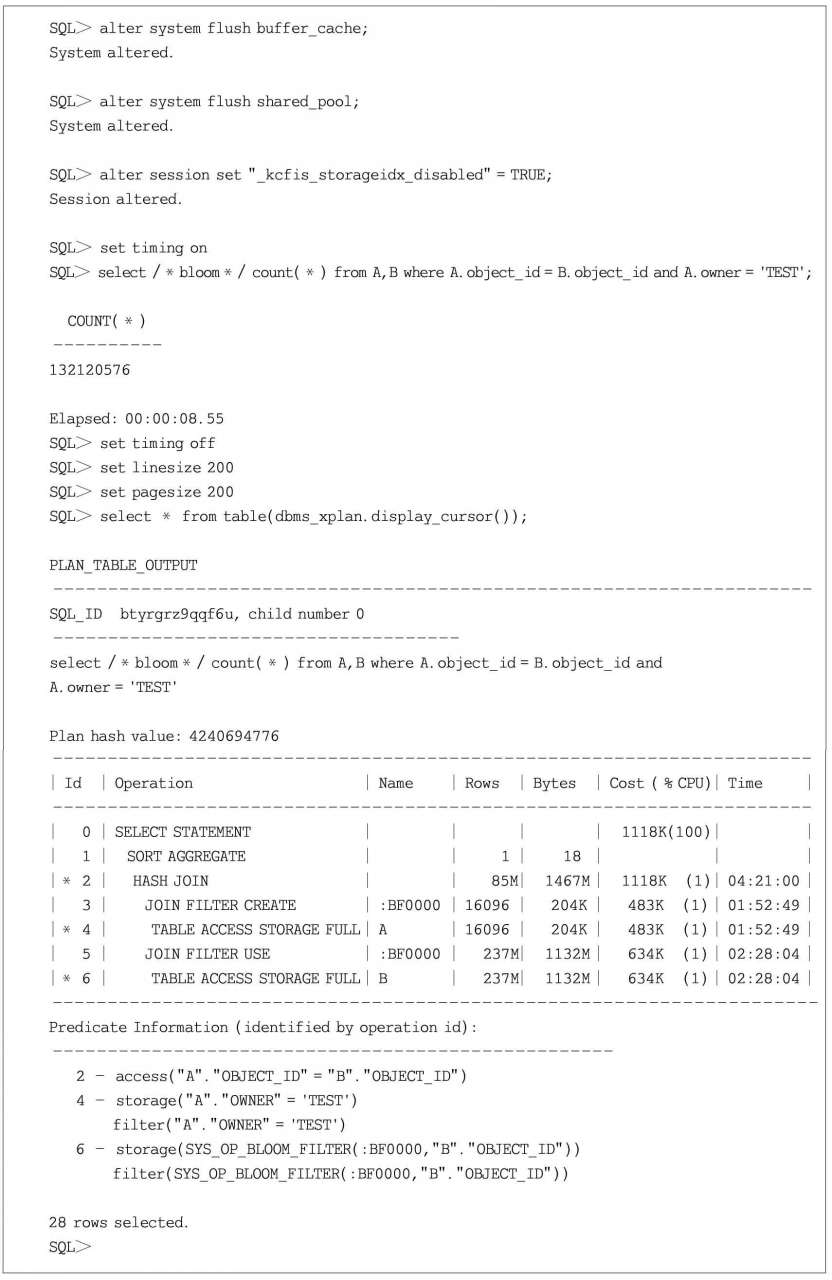
在存儲索引特性關閉的情況下,A和B這兩張表進行Hash關聯,布隆過濾特性默認已經開啟。從以上的SQL語句執行計劃也可以看出布隆過濾特性已經生效,因為在執行計劃的name列中出現了:BF0000。
接著關閉布隆過濾特性,看看完全相同的SQL語句的執行效率,見代碼清單1.5。
代碼清單1.5 關閉布隆過濾特性

可以看出,關閉布隆過濾特性后,相同的SQL語句執行效率比之前慢了一倍。
在MOS文檔FAQ related to some of the Exadata basic administration(Doc ID 1301327.1)中提及將數據庫的隱含參數_bloom_pruning_enabled設置成false,可以關閉布隆過濾特性,下面通過示例進行驗證,見代碼清單1.6。
代碼清單1.6 測試隱含參數_bloom_pruning_enabled

從以上示例可以看出,數據庫的隱含參數_bloom_pruning_enabled已被設置為false,但是布隆過濾特性并沒有被關閉。
查看數據庫隱含參數_bloom_pruning_enabled的具體含義,見代碼清單1.7。
代碼清單1.7 查看隱含參數_bloom_pruning_enabled的具體含義
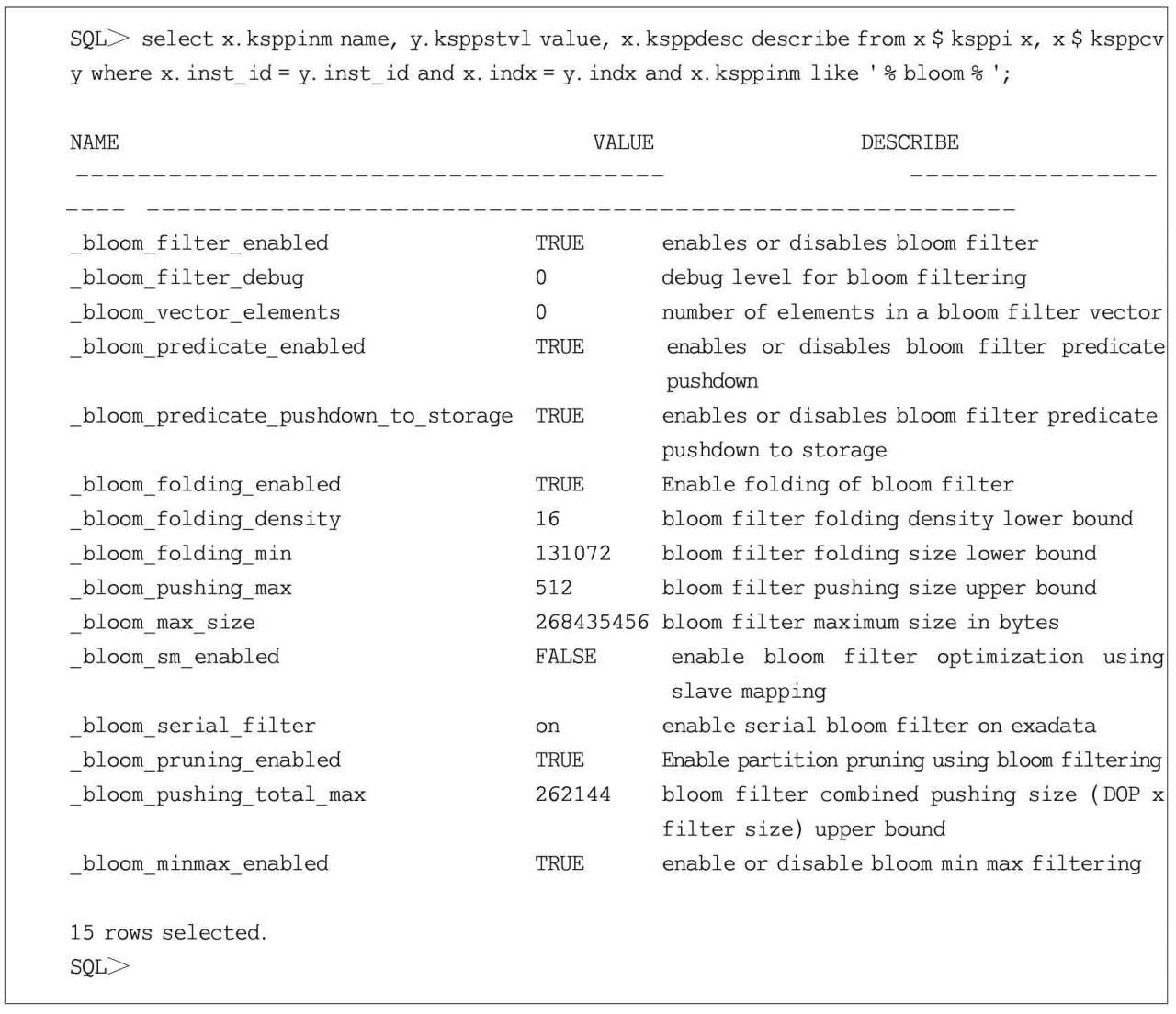
從隱含參數_bloom_pruning_enabled的具體含義可以看出,_bloom_pruning_enabled僅僅只是布隆過濾的一個子特性而已。如果要完全關閉布隆過濾特性,應該由隱含參數_bloom_filter_enabled進行控制。
注意:布隆過濾只有在進行hash連接的情況下才會工作。
1.1.4 函數過濾
V$SQLFN_METADATA視圖中的OFFLOADABLE列表明了哪些內置函數或者操作符是允許智能掃描的,YES表示允許智能掃描,NO表示不允許智能掃描,見代碼清單1.8。
代碼清單1.8 查詢哪些內置函數或操作符允許智能掃描

絕大部分的SQL函數或SQL操作符都是允許進行智能掃描的,以上示例只是羅列了很小的一部分內置函數和操作符而已。在編寫SQL語句時,要盡量避免使用那些會影響智能掃描操作的內置函數和操作符。
- Testing with JUnit
- 數據結構和算法基礎(Java語言實現)
- Learning Docker
- Photoshop智能手機APP UI設計之道
- JavaScript語言精髓與編程實踐(第3版)
- Learning RxJava
- Linux核心技術從小白到大牛
- Visual C++數字圖像模式識別技術詳解
- 64位匯編語言的編程藝術
- Full-Stack React Projects
- 一本書講透Java線程:原理與實踐
- Node學習指南(第2版)
- Geospatial Development By Example with Python
- .NET 4.5 Parallel Extensions Cookbook
- JavaScript從入門到精通(視頻實戰版)