- SQL Server 2016數據庫應用與開發
- 姜桂洪主編
- 2019字
- 2019-07-01 10:15:10
3.5 數據庫快照和數據分區管理
3.5.1 數據庫快照
數據庫快照(Snapshot)是SQL Server 2016源數據庫的只讀、靜態視圖。多個快照可以位于一個源數據庫中,并且可以作為數據庫始終駐留在同一服務器實例上。
1.數據庫快照的工作方式
數據庫快照為數據庫用戶提供了一種保存某一歷史時刻的數據庫中數據的機制。例如,在某一天的12:00對數據庫test01創建快照,該數據庫用戶就可以在以后的任何時間訪問那一刻test01數據庫中的數據。
下面介紹數據庫快照的工作方式,如為數據庫test01創建快照。假設現在時間為9:00整,用戶對數據庫test01創建一個數據庫快照test01Snap0900。此時,數據庫快照test01Snap0900并不記錄任何信息。而在此之后,數據庫中的文件(準確地說是數據頁)發生任何變化,如數據的刪除、修改等,快照test01Snap0900將記錄在數據頁變化前的原始數據,即僅將修改部分的原始信息復制到數據庫快照。也就是數據庫快照將保留原始頁,保存快照創建時的數據記錄。
要訪問快照數據,系統將以下面的原則讀取數據。
①數據未變化,查詢源數據庫的信息。
②數據發生變化,則查詢存儲在數據庫快照中的信息。
每個數據庫快照在事務上與源數據庫一致。在被數據庫所有者顯式刪除之前,快照始終存在。
2.數據庫快照的用途
(1)維護歷史數據以生成報表。由于數據庫快照可提供數據庫的靜態視圖,因而可以通過快照訪問特定時間點的數據。
(2)可以避免由于用戶失誤造成的數據損失。定期創建數據庫快照,在源數據庫出現用戶錯誤,還可將源數據庫恢復到創建快照時的狀態。丟失的數據僅限于創建快照后數據庫更新的數據。例如,考慮test01數據庫的一系列快照,在每天8:00和20:00,以12h作為間隔創建兩個每日快照(test01Snap0800和test01Snap2000)。每個每日快照保持24h后才被刪除,并被同一名稱的新快照替換。
(3)可以避免由于管理失誤造成的數據損失。在進行大容量更新數據之前,可以先創建一個數據庫快照。一旦出現失誤就可以利用數據庫快照恢復數據庫。
(4)利用快照中的信息,手動重新創建刪除的表或其他丟失的數據。例如,可以將快照中的數據大容量復制到數據庫中,然后手動將數據合并回數據庫中。
3.創建數據庫快照
任何能創建數據庫的用戶都可以創建數據庫快照。Transact-SQL語句是創建數據庫快照的唯一方式。Transact-SQL語法格式如下:

上述格式的主要參數說明如下。
①database_snapshot_name:新數據庫快照的名稱。
②ON(NAME=logical_file_name,FILENAME='os_file_name'):創建數據庫快照,必須在源數據庫中指定文件列表。若要使快照工作,必須分別指定所有數據文件。
③AS SNAPSHOT OF source_database_name:用于指定要創建數據庫快照的原數據庫名為source_database_name。快照和源數據庫必須位于同一實例中。
【例3-9】 為test01創建數據庫快照。
程序代碼如下:
USE master
GO
create database test01snapshot
on
(
name = 'test01',
filename = 'D:\sqlprogram\test01_1200.ss')
AS SNAPSHOT OF test01
程序執行后,展開“數據庫”→“數據庫快照”子目錄,即可發現數據庫快照test01snapshot已經創建成功,如圖3-29所示。而數據庫快照文件test01_1200.ss則已經存儲于指定文件夾中。
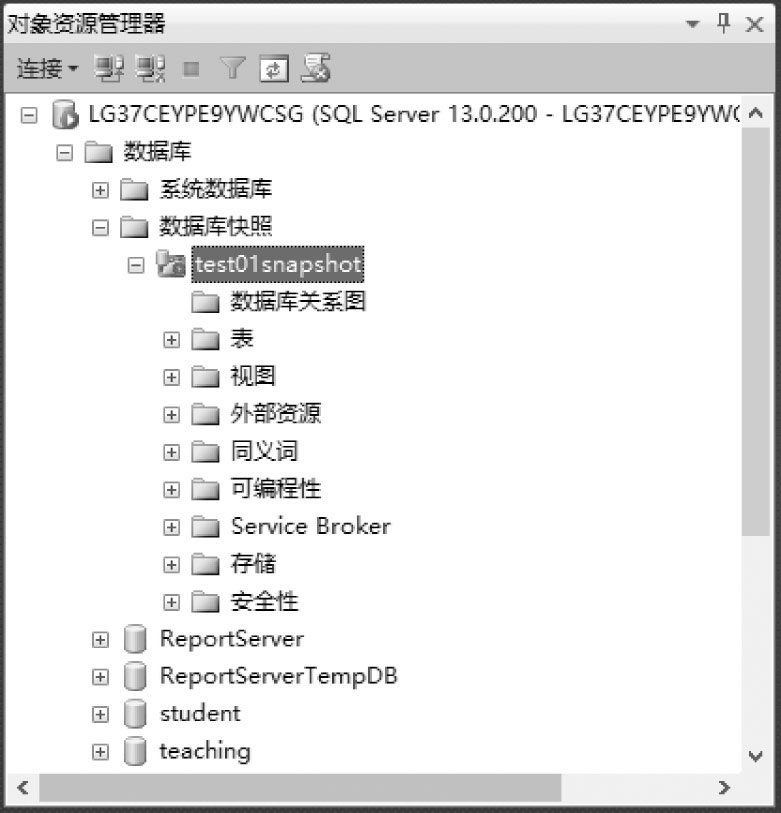
圖3-29 數據庫快照
右擊數據庫快照test01snapshot,在彈出的快捷菜單中選擇“屬性”命令,在彈出的對話框中可以觀察到與數據庫屬性窗口近似的“數據庫屬性-test01snapshot”對話框,如圖3-30所示。
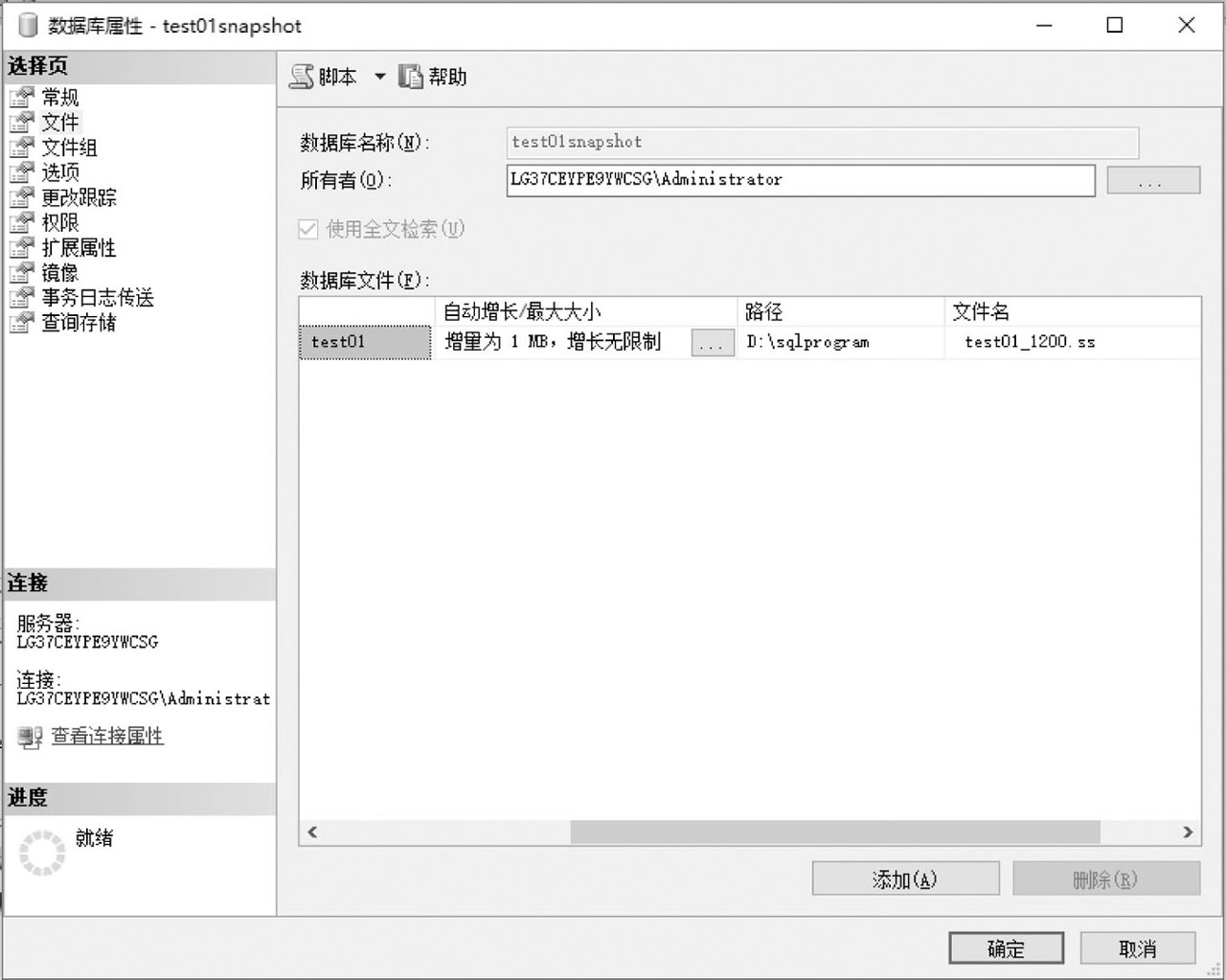
圖3-30 數據庫快照的屬性
4.刪除數據庫快照
具有DROP DATABASE權限的任何數據庫用戶都可以通過刪除操作來刪除數據庫快照。刪除數據庫快照的方法與刪除數據庫相同。
刪除數據庫快照的方法有以下兩種。
(1)在SQL Server Management Studio中查看數據庫快照,然后右擊,在彈出的快捷菜單中選擇“刪除”命令即可。
(2)使用DROP DATABASE語句。如在查詢窗口中輸入以下命令并執行,即可刪除數據庫快照test01snapshot:
USE master
GO
DROPDATABASE test01snapshot
GO
關于數據庫快照的其他內容可以參考聯機叢書的內容。
3.5.2 數據分區管理
數據分區即將一個原本的大數據表拆分成較小的多個數據表,由于需要查詢的數據局限于空間的局部性,即查詢的行往往位于同一分區中。通過分區可以將在大量數據集中進行查詢的操作轉換為在小部分數據中進行查詢的操作,從而獲得更快、更高的查詢效率。此外,將數據分區也有利于數據庫的維護操作,如重新生成索引或備份表也可以更快地運行。
實際操作過程中,也可以不拆分數據表,而是將數據表安排到不同磁盤驅動器上的方法來實現分區。例如,將數據表放在某個物理驅動器上,并將相關的表放在不同的驅動器上,同樣可以提高查詢性能,因為在運行涉及表間連接的查詢時,多個磁頭可以同時讀取數據。可以使用SQL Server 2016文件組來指定放置表的磁盤。
如果將原有的大數據表拆分成多個小數據表,則通常被稱為水平分區。水平分區的特點是每個分區中包含的列數是一樣的,但是其每個分區表中的行數被減少了。與之對應,還存在著一種被稱為垂直分區的方案,即將一個數據表中的列劃分到多個結構較為簡單的數據表中。
在SQL Server 2016中創建分區表的參考步驟如下。
(1)創建分區函數以指定如何分區,以及分區所涉及的數據表。
(2)創建分區方案以指定分區函數的分區在文件組上的位置。
(3)創建使用分區方案的表。
表、索引和大型對象數據可以與指定的文件組相關聯。在這種情況下,它們的所有頁將被分配到該文件組,或者對表和索引進行分區。已分區表和索引的數據被分割為單元,每個單元可以放置在數據庫中的單獨文件組中。
有關分區的詳細介紹讀者可參見Microsoft提供的聯機文檔。
- 垃圾回收的算法與實現
- 深入淺出Prometheus:原理、應用、源碼與拓展詳解
- Internet of Things with the Arduino Yún
- Java應用開發技術實例教程
- Unity UI Cookbook
- Android開發三劍客:UML、模式與測試
- 深入剖析Java虛擬機:源碼剖析與實例詳解(基礎卷)
- Android驅動開發權威指南
- OpenStack Networking Essentials
- Visual Basic程序設計(第三版)
- 小程序從0到1:微信全棧工程師一本通
- Moodle 3.x Developer's Guide
- 微服務設計
- Splunk Developer's Guide(Second Edition)
- Python數據分析與挖掘實戰(第2版)