- Solr權威指南(下卷)
- 蘭小偉
- 1619字
- 2019-01-03 15:33:41
11.5 Solr Facet Function
傳統的Facet查詢解決了基于某個Facet約束條件來統計查詢結果集問題,Solr中擴展傳統Facet的Facet Function支持對Document的域進行聚合操作。將Facet Function與Subfacet功能結合,兩者可以提供強大的實時分析統計能力,具體請看后續章節的JSON Facet API部分。
11.5.1 聚合函數
Subfacet將主體信息劃分為多個Facet Bucket,每個Bucket又可以嵌套多個Subfacet,最終會返回每個Bucket的詳細信息。Solr提供了Aggregation Function(聚合函數)用于Subfacet的查詢統計,如表11-8所示。
表11-8 聚合函數
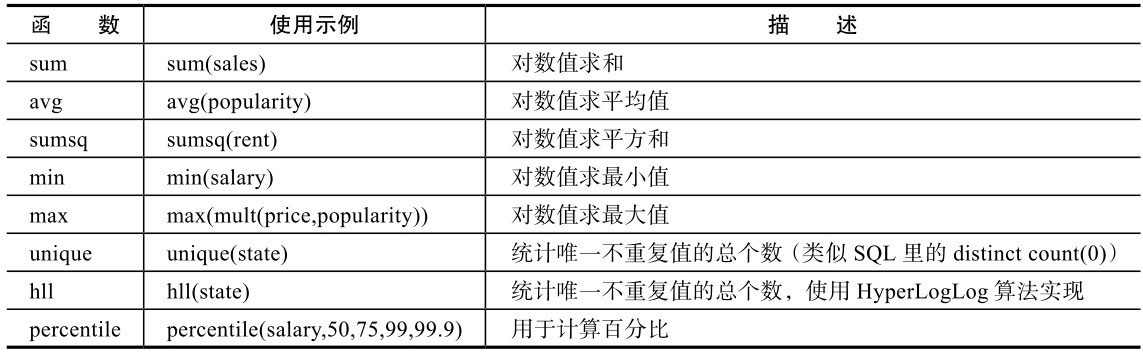
數值聚合函數,比如sum、avg,可以作用于數字域或者另外一個函數,也就是說聚合函數也是可以嵌套使用的。不監測計算所有唯一值想要實現100%精確度的數據統計幾乎是不可能的,但是通常有很多種方法可以用來預算估計。
Facet Function中的“unique”是Solr中用來計算唯一值總數的最快實現。對于單個Solr節點,unique函數總是能夠提供確切的數值,對于分布式查詢模式下,當每個Solr節點上的每個數值不超過100,那么也可以能夠提供確切的數值。當任意給定分片上的唯一值數量超過100時,那么統計時會使用下列算法:
??每個分片發送Top 100結果集以及每個分片的確切的unique函數計算的唯一值數量;
?totalSeen就是我們能夠從所有分片看到的實際結果集數量;
?uniqueSeen就是我們能夠從所有分片看到的實際唯一值的數量;
?notSeen就是所有分片未發送的結果集中的唯一值數量(因為每個分片我們只發送前100條結果);
?factor=uniqueSeen/totalSeen;
??最后估算公式:estimate = uniqueSeen + (notSeen * factor)。
11.5.2 聚合函數與Subfacet結合
Facet查詢統計首先會按照q參數構建的主查詢和Filter Query來過濾索引文檔,然后我們就可以在剩下的整個索引文檔基礎之上執行數據統計和分析操作。請看下面這個查詢示例:
http://localhost:8080/solr/select? q=*:*&json.facet={x:'avg(price)'}
上面的查詢示例中我們在price域定義了一個名稱為x的Facet(維度),對price域求平均值,這有點類似于SQL里的select count(0), avg(price) frin table_name group by price。
假如你想要實現每個分類的求和和求平均值等聚合操作,即類似SQL里的“select avg(price) as x, sum(price) as y from table_name group by cat”功能,那么你可以像下面這樣實現:
json.facet={
categories:{
type : terms, //這里的terms相當于傳統Facet里的根據單個域進行Facet統計
field : cat,
facet:{
x : "avg(price)",
y : "sum(price)"}}}
11.5.3 Solr中的Percentile函數
Percentile聚合函數是新Solr Facet模塊中新增的函數,它允許每個Facet Bucket計算一個百分比(即Facet生成的每個組下的所有索引文檔),甚至可以按照任意指定的percentile(百分比)對Facet Bucket進行排序。Percentile聚合函數甚至還支持Solr分布式查詢,內部使用的算法是t-digest,此算法能夠以相對較少的內存消耗提供較高精度的近似值。
 注意
注意
Percentile聚合函數至少需要Solr 5.1版本或者更高版本才能使用。
想要使用Percentile聚合函數,首先讓我們先創建一個"percentile" Core并導入測試數據,請照例根據隨書源碼提供的文件創建好Core并導入測試數據。
現在讓我們使用Facet聚合函數來“切割”數據!假設要統計一下我們的工作職位測試數據中,25%、50%、75%的工作職位的薪酬大概是多少:
http://localhost:8080/solr/percentile/select? q=*:*&json.facet={
salary_percentiles : "percentile(salary,25,50,75)"
}
返回結果集如下所示:
"facets":{
"count":15,
"salary_percentiles":[51000.0,74000.0,79500.0]}}
我們還可以添加其他統計,比如工作職位的平均薪水、工種總個數、工作地點總個數:
http://localhost:8080/solr/percentile/select? q=*:*&json.facet={
average_salary : "avg(salary)",
num_jobs : "unique(job)",
num_states : "unique(loc)",
salary_percentiles : "percentile(salary,25,50,75)"
}
返回結果集如下所示:
"facets":{
"count":15,
"average_salary":63374.6,
"num_jobs":5,
"num_states":3,
"salary_percentiles":[51000.0,74000.0,79500.0]
}
現在讓我們看看所有工作職位里薪水中間檔次對于男女分別是多少:
http://localhost:8080/solr/percentile/select? q=*:*&json.facet={
by_gender:{terms:{
field:gender,
facet:{
median_salary:"percentile(salary,50)"
}
}}
}
返回結果如下所示:
"facets":{
"count":15,
"by_gender":{
"buckets":[{
"val":"M",
"count":8,
"median_salary":62750.0},
{
"val":"F",
"count":7,
"median_salary":81000.0}]}}}
我們還可以根據percentile聚合函數統計出來的數值進行排序,如果你請求了多個percentile值,percentile聚合函數會返回多個統計數值,此時會按照第一個值進行排序。讓我們統計看看99.9%的工作職位的薪資對于不同工作地點分別大概是處于什么水平,最后按照percentile聚合函數統計出來的每個工作地點的大概薪資進行排序:
http://localhost:8080/solr/percentile/select? q=*:*&json.facet={
rich_states:{terms:{
field : loc,
sort : {sal:desc}, //你也可以寫成sort:"sal desc"
facet : {
sal : "percentile(salary,99.9)"
}
}}
}
返回的結果如下所示:
"facets":{
"count":15,
"rich_states":{
"buckets":[{
"val":"CT",
"count":5,
"sal":109909.19600000001},
{
"val":"NY",
"count":5,
"sal":89438.00000000001},
{
"val":"NJ",
"count":5,
"sal":80976.0}]}}}
我們甚至可以執行更有趣的嵌套Facet查詢,比如統計一下看看每個工作地點里最掙錢的職業是什么?
http://localhost:8080/solr/percentile/select? q=*:*&json.facet={
states:{terms:{
field:loc,
facet:{
top_jobs:{terms:{
field : job,
sort : "sal desc",
limit : 1,
facet:{
sal : "percentile(salary,99.9,50,10)"}}} }}}}
返回的結果集太長了,這里就省略不貼了。我們甚至還可以統計每個工作點的工作職位的中間檔薪酬隨著時間推移的變化趨勢:
http://localhost:8080/solr/percentile/select? q=*:*&json.facet={
states:{terms:{
field:loc,
facet:{
over_time:{range:{
field : year,
start : 2011,
end : 2015,
gap : 1,
facet:{
median_salary : "percentile(salary,50)"
}
}}
}
}}
}
到此我想你已經感受到了Percentile聚合函數的強大了,請盡情發揮你自己的想象力,并結合實際項目需求構造出更復雜的統計查詢。
- Hyper-V 2016 Best Practices
- Mastering ServiceStack
- Beginning C++ Game Programming
- MySQL 8從入門到精通(視頻教學版)
- VMware vSphere 6.7虛擬化架構實戰指南
- Mastering Unity Shaders and Effects
- 差分進化算法及其高維多目標優化應用
- Learning Apache Kafka(Second Edition)
- Learning Zurb Foundation
- C程序設計實踐教程
- Mastering ROS for Robotics Programming
- Corona SDK Mobile Game Development:Beginner's Guide(Second Edition)
- C語言開發基礎教程(Dev-C++)(第2版)
- Geospatial Development By Example with Python
- Android傳感器開發與智能設備案例實戰