- 另類數據:投資新動力(數字經濟系列03)
- 王聞 孫佰清
- 2193字
- 2025-08-08 15:15:35
新聞標題
在這個小節中,我們將介紹Sesen et al.(2019)基于財經新聞討論的并購套利案例。并購套利是一種成熟的投資策略。簡單來說,它是一種在并購公告日建倉的風險策略,然后押注所涉的并購交易會最終完成。根據Jetley/Ji(2010)的分析,雖然隨著時間推移,并購策略的獲利能力會下降,但即使是基于公開信息,投資者也可以從這種策略上獲取相當大的風險溢價。長久以來,像對沖基金這些的機構投資者會使用并購策略,而現在散戶投資者也可以通過ETF或者是公募基金投資于并購策略。
當前,就新聞媒體在并購交易中的角色已經有了很好的研究。Liu/McConnell(2013)分析了新聞媒體的報道可能會讓有聲譽風險的公司放棄進行并購交易,而Ahern/Sosyura(2015)則指出,新聞媒體可能會傳播讓報紙讀者感興趣的并購謠言,而這些謠言會扭曲股票價格,并且導致價格波動。與之相比,分析新聞資訊流在并購套利中的作用就比較少了。在有關并購交易的文本分析中,Buehlmaier/Zechner(2021)發現,市場對并購新聞的反應存在著不足,需要花費幾天的時間才能完成定價。根據新聞內容設計的一個簡單并購策略,可以讓風險調整收益率增加12%。更進一步,他們發現,如果用財經新聞過濾掉實現概率較低的并購交易,那么并購套利的獲利將會顯著增加。
Sesen et al.(2019)的分析是通過各種機器學習方法,把并購相關的新聞標題和并購無關的新聞標題區隔開來。這種算法首先對并購新聞進行分類標記,然后從中提取分類模式。最終通過這個“新聞過濾器”(NewsFilter)的模型,推斷出其他的新聞標題是屬于和并購有關還是無關的分類。這種分析可以幫助投資者及時對并購公告做出反應,篩選出與并購交易相關的股票,并且啟動并購套利交易。
作者分析的數據集覆蓋了從2017年1月到2017年6月之間總計1.3萬條新聞標題。某家大型資管公司的投資經理把這些新聞標題分為和并購套利相關與無關兩類。在這個數據集中,總計有31%的新聞標題被標記為“相關”類型,剩下的被標記為“無關”類型。
一般來說,一篇財經新聞常常會涉及多家公司,同時對這些公司的討論強度各有不同。大多數新聞服務商像瑞文一樣,會對特定的新聞報道給出關聯性分數,從而可以量化某篇新聞報道對于特定公司主體的報道強度。在并購相關的新聞中,因為所涉及的主體主要就是收購公司和收購目標公司,所以相比于其他類型的財經新聞,其中的實體匹配問題比較小。在Sesen et al.(2019)分析的數據集中,數據服務商已經給出了關聯性標簽(relevance tags),這樣就很容易把并購新聞和相關的公司證券代碼聯系起來。
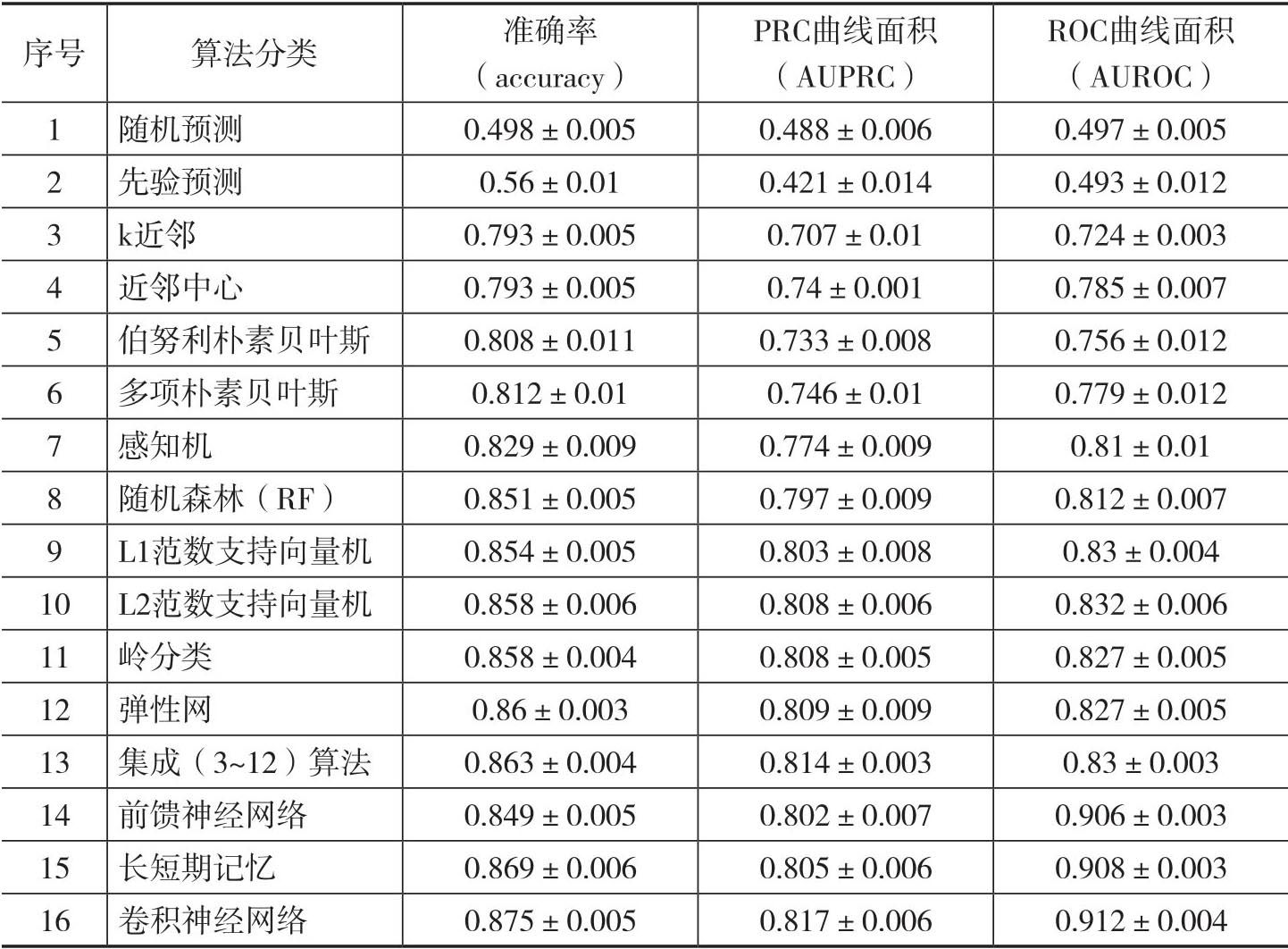
Sesen et al.(2019)將人工標記的并購新聞標題數據集等分成五組,其中每組并購相關和并購無關的頻率和總體樣本的頻率大致相當,也就是并購相關的標題約為69%。對于各種不同基于分類算法,作者在四組樣本上進行訓練,然后在剩下的一組中進行測試,這個過程將在所有五組中通過迭代的方式來進行,因此就進行了五次交叉驗證(cross-validation)。最后,所有的預測模型都將根據以下三個指標來評估績效:
(1)準確率(accuracy);
(2)精確-召回曲線(precision-call curve/PRC)下方的面積(AUPRC);
(3)接收者操作特征曲線(receiver operation characteristic/ROC)下方的面積(AUROC)。[17]
表1.6報告了各種二元分類算法的預測績效。第1行和第2行給出了“隨機預測”(random predictor)和“先驗預測”(prior predictor)這兩個基準分類器的結果。顧名思義,隨機預測就是說隨機分配一半的新聞標題為并購相關,然后剩下的一半標題分類為并購無關。先驗預測與隨機預測相似,只不過此時我們將樣本按照某個先驗分類而不是等概率的方式進行隨機分配。從直覺上看,這兩個分類器效果不會太好,而績效指標結果支持了這個直覺判斷。
第3行和第4行給出了k近鄰(k-Nearest Neighbors/k-NN)和近鄰中心(Nearest Centroid)這兩種近鄰算法的分類績效。結果表明它們的分類效果也很一般。不過一個有趣的結果是,雖然兩者的平均準確率幾乎相同,但是AUPRC和AUROC表明近鄰中心的算法在分類效果上更好。
第5行和第6行給出了兩種樸素貝葉斯(Na?ve Bayes/NB)方法的結果,即伯努利樸素貝葉斯(Bernouli NB)和多項樸素貝葉斯(Multinomial NB)。多項樸素貝葉斯通常要求在文檔術語(document-term matrix)中采用整數型單詞計數的方式,不過在實際應用中,類似詞頻-逆文頻(TF-IDF)這樣的比率型計數方式也很常用。[18]與多項方法相比,伯努利方法具有二進制特征,這樣詞頻-逆文頻就會退化為0和1。表1.6的結果表明,雖然多項分類器具有更復雜的結構,但是它的分類績效并沒有比二項分類器好很多。
第7行到第12行報告了其他各種常用分類算法的結果,這些分類算法包括感知機(perceptron)、隨機森林(random forest)、具有不同正則化懲罰的支持向量機(supporting vector machine/SVM)、嶺分類(ridge classifier)以及彈性網(elastic net),它們可以歸為傳統但是相對復雜分類算法。結果表明它們在對新聞標題進行分類方面表現得不錯。
第13行報告了把第3行到第12行的分類器進行集成(ensemble)的分類效果。正如其名稱所示,集成分類算法得到的結果要好于所有成分算法,當然從績效指標上看,它只是略微強于彈性網這種在前面12種算法中最優算法產生的分類效果。
近些年飛速發展的以神經網絡為代表的人工智能和深度學習技術也開始應用到文本分析中。[19]表1.6的最后三行給出了前饋神經網絡(feedforward neural network/FNN)、長短期記憶(long short-term memory/LSTM)和卷積神經網絡(convolutional neural network/CNN)三種方法的分類效果。[20]從中可以看到前饋神經網絡的預測績效要好于感知機。因為神經網絡模型擁有更多的隱藏層,所以就比感知機擁有更強的表征能力,所以這個結果并不意外。如果把三種不同的神經網絡算法進行比較,顯然后面兩種更為復雜的神經網絡方法分類效果更好,雖然增加的績效比較有限。[21]
表1.6 NewsFilter樣本數據集的五倍交叉驗證預測性能結果