- Flink原理深入與編程實戰:Scala+Java(微課視頻版)
- 辛立偉編著
- 1582字
- 2023-07-17 18:54:31
1.4.1 Flink獨立集群安裝和測試
Flink集群可以運行在單節點上,這稱為Standalone Cluster模式(在一臺機器上,但在不同的進程中)。獨立模式是部署Flink最簡單的方式。
1.Standalone集群安裝
Standalone集群安裝步驟如下。
(1)要運行Flink,要求必須安裝好Java 1.8。檢查Java是否已經正確安裝,命令如下:

如果已經正確地安裝了Java 1.8,則輸出內容如圖1-22所示。

圖1-22 在安裝Flink之前,驗證是否已經安裝了JDK
(2)下載Flink安裝包。下載網址為https://archive.apache.org/dist/flink/flink-1.13.2/。可以選擇任何喜歡的Hadoop/Scala組合。本書使用的是1.13.2版本,基于Scala 2.12。因為Flink版本更新迭代比較快,并且每次版本升級都有許多API變動,因此建議讀者學習時也安裝與本書相同的版本,如圖1-23所示。
(3)解壓縮安裝包。將下載的安裝包放在~/software/目錄下,然后將其解壓縮到指定的位置(例如,~/bigdata/目錄下)。在終端執行的命令如下:
圖1-23 建議與本書保持一致,安裝Flink 1.13.2版本

(4)啟動一個本地Flink集群。
對于單節點設置,Flink是開箱即用的,即不需要更改默認配置,直接啟動即可,命令如下:

使用jps命令查看進程,可以看到啟動了以下兩個進程:

打開瀏覽器,輸入地址http://localhost:8081,可查看調度程序的Web前端。Web前端應該報告有單個可用的TaskManager實例,如圖1-24所示。
還可以通過檢查log目錄中的日志文件來驗證系統是否正在運行,命令如下:

(5)要關閉Flink集群,使用的命令如下:

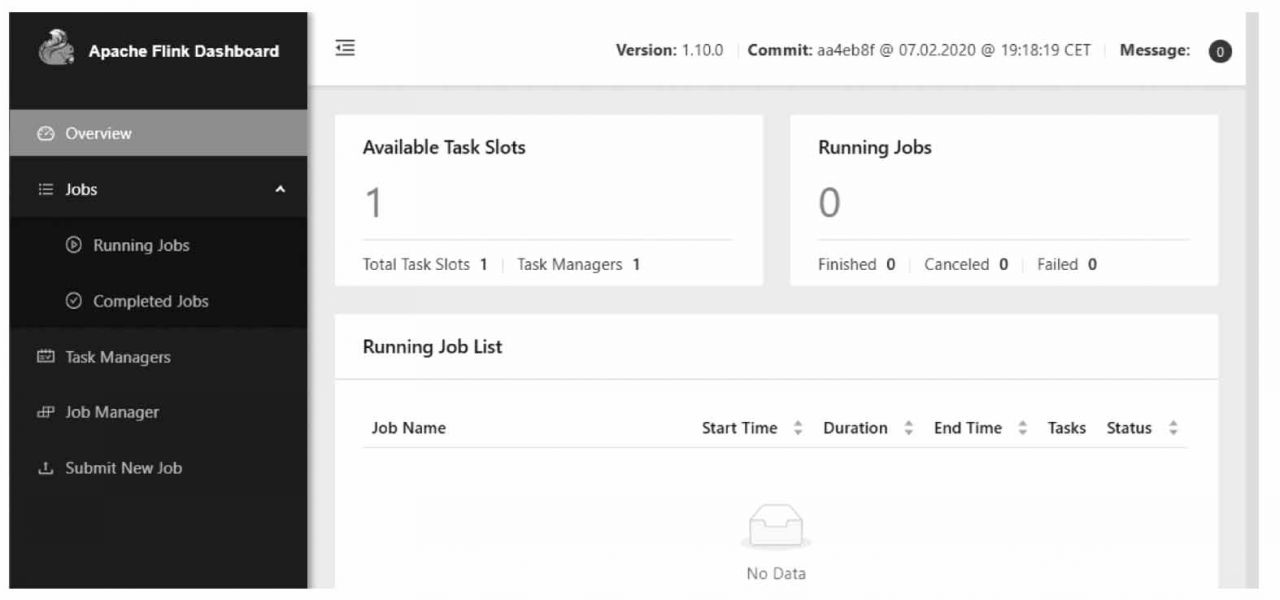
圖1-24 Flink調度程序的Web前端
2.運行Flink自帶的實時單詞計數流程序
Flink安裝包自帶了一個以Socket作為數據源的實時統計單詞計數的流程序,位于Flink下的example/streaming/SocketWindowWordCount.jar包中。可以通過運行這個流程序來測試Flink集群的使用方法。建議按以下步驟執行。
(1)首先,啟動netcat服務器,運行在9000端口,使用的命令如下:

(2)打開另一個終端,啟動Flink集群,執行的命令如下:

(3)啟動Flink示例程序,監聽netcat服務器的輸入,命令如下:

這個實時單詞計數流程序將從Socket套接字中讀取輸入的文本內容,并每5s打印前5s內每個不同單詞出現的次數,即處理時間的滾動窗口。
(4)在netcat控制臺,鍵入一些單詞,Flink將會處理這些單詞。例如,輸入以下內容:

(5)啟動第3個終端窗口,并在該窗口中執行以下命令,查看日志中的輸出:

可以看到輸出結果如下:

(6)還可以檢查Flink Web UI來查看Job是怎樣執行的,如圖1-25所示。
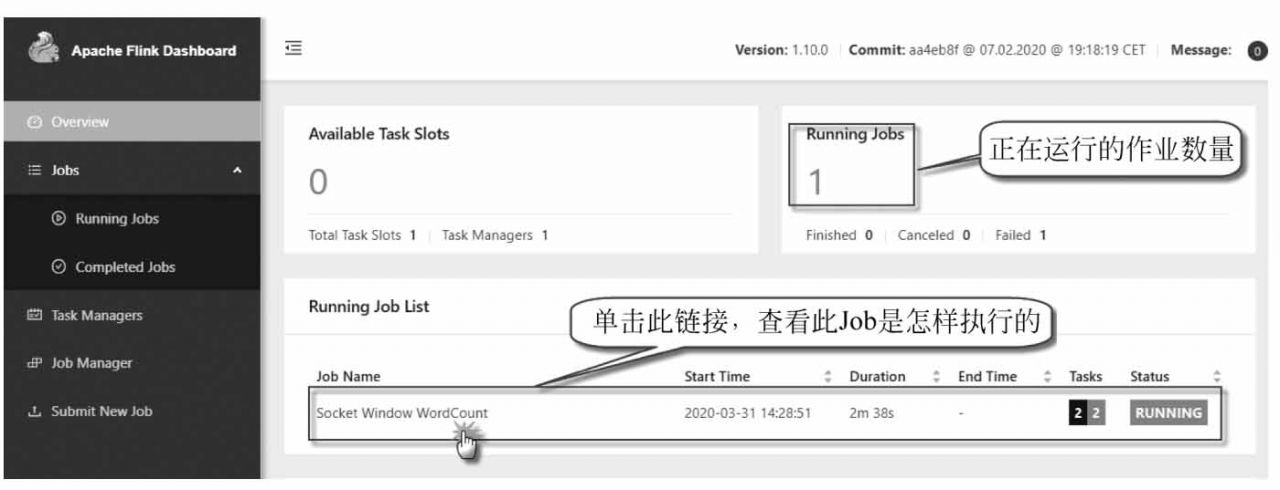
圖1-25 在Flink Web UI中查看作業的執行
單擊圖中的Running Job List下正在運行的作業列表,查看某個正在運行的作業執行情況,如圖1-26所示。
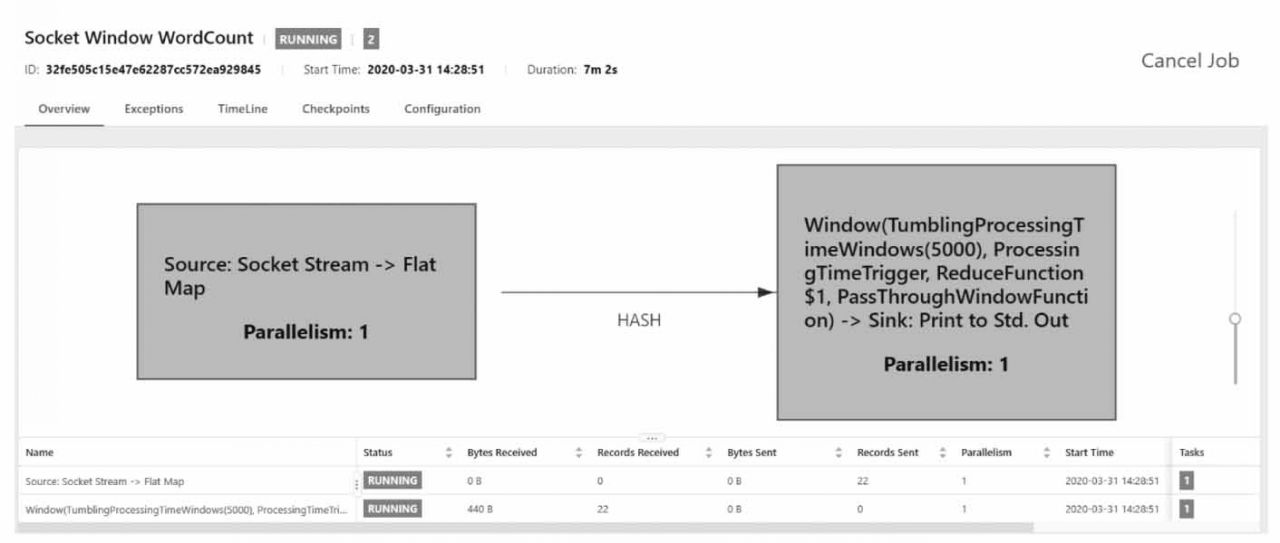
圖1-26 在Flink Web UI中查看正在運行的作業執行情況
(7)最后停止Flink集群,使用的命令如下:

3.運行Flink自帶的單詞計數批處理程序
Flink安裝包自帶了一個以文本文件作為數據源的單詞計數批處理程序,位于Flink下的example/batch/目錄下的WordCount.jar包中。下面演示如何在Flink集群上執行該程序,讀取HDFS上的輸入數據文件進行處理,并將計算結果輸出到HDFS上。
建議按以下步驟執行。
(1)集成Hadoop。因為要讀取HDFS上的源數據文件,所以需要在Flink中集成Hadoop包。從Flink 1.8開始,Hadoop不再包含在Flink的安裝包中,所以需要單獨下載并復制到Flink的lib目錄下。
如果使用的是Hadoop 2,則可從Flink官網下載flink-shaded-hadoop2-uber-2.7.5-1.10.0.jar,如圖1-27所示。
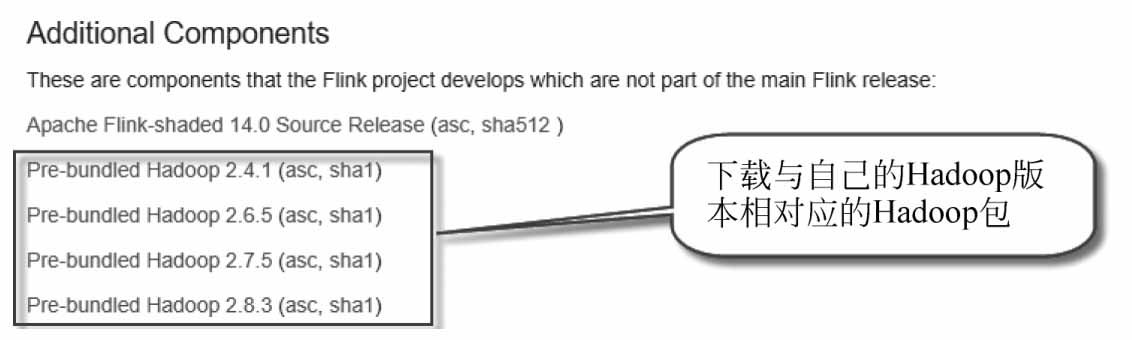
圖1-27 從Flink官網下載兼容Hadoop 2的集成包
如果使用的是Hadoop 3,則需要從Maven官方資源庫下載。下載網址為https://mvnrepository.com/artifact/org.apache.flink/flink-shaded-hadoop-3-uber,如圖1-28所示。
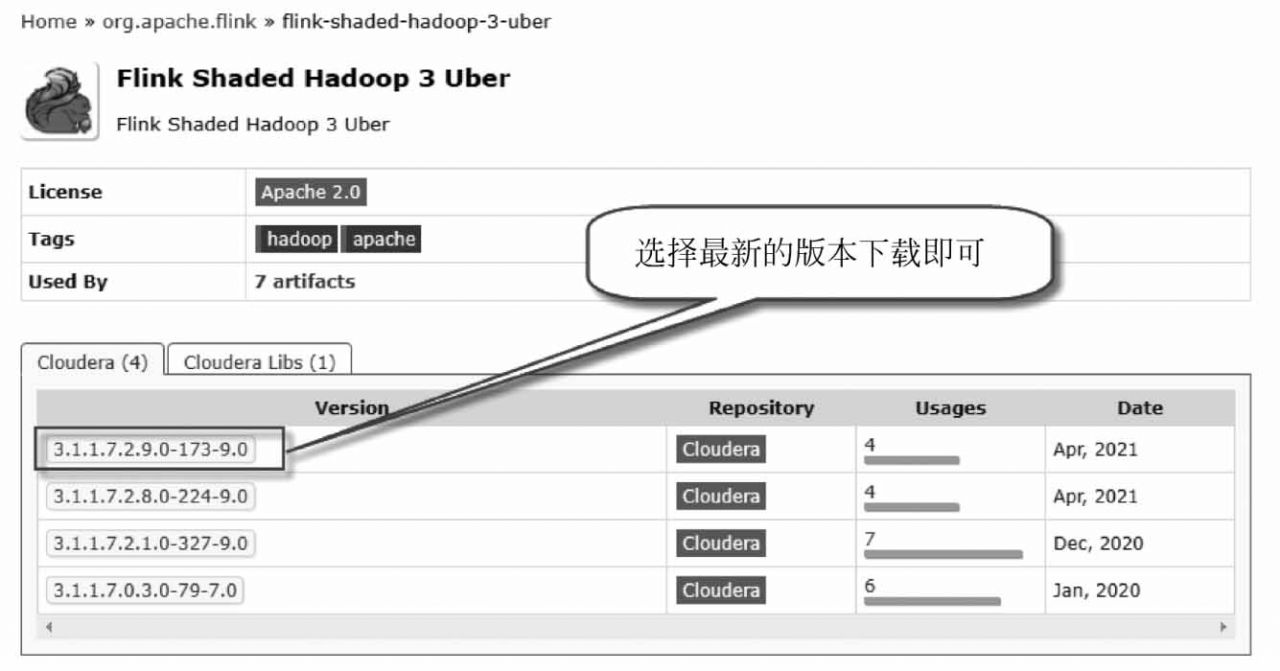
圖1-28 從Maven下載兼容Hadoop 3的集成包
本書中使用的是Hadoop-3.2.2這個版本,所以需要從Maven官方資庫下載flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar包。將下載的JAR包復制到Flink的lib目錄下。
(2)準備環境。先啟動Flink集群,再啟動HDFS集群。在終端窗口中,執行的命令如下:

(3)準備數據文件。編輯數據文件wc.txt,內容如下:

然后將該文件上傳到HDFS的/data/flink/目錄下,使用的命令如下:

(4)執行Flink的批處理程序,命令如下:

執行過程如圖1-29所示。
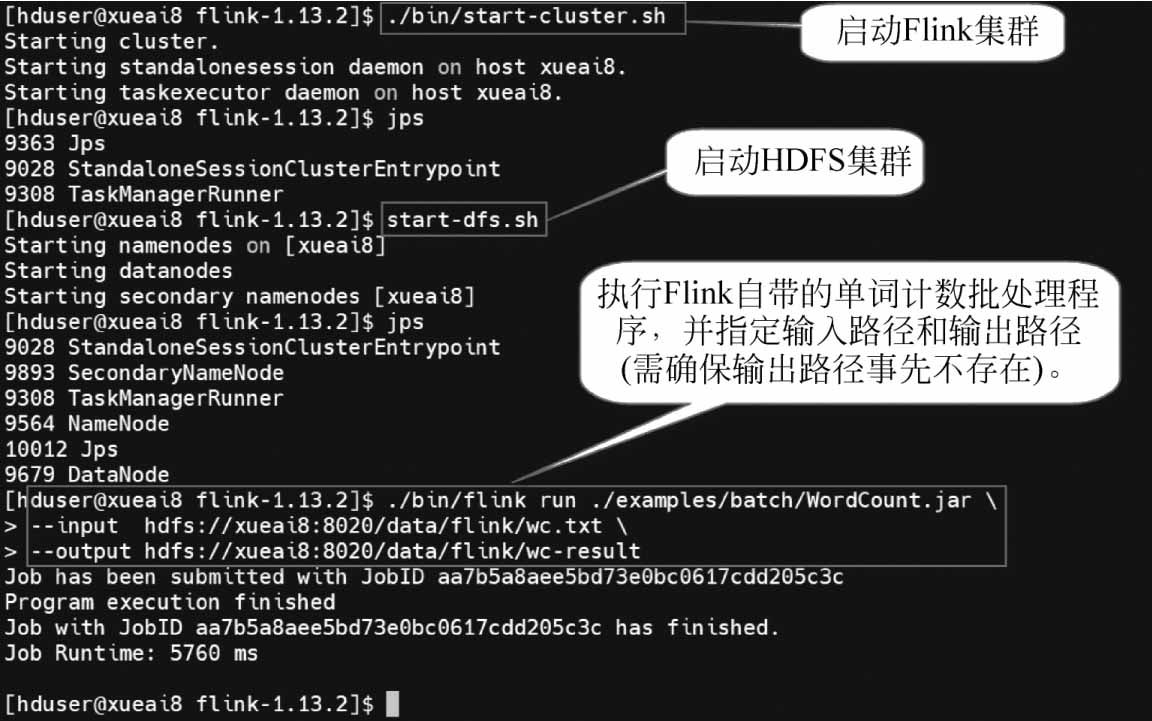
圖1-29 Flink單詞計數批處理程序執行過程
上面的命令是在運行WordCount時讀寫HDFS中的文件的,其中--input參數用于指定要處理的輸入文件,--output參數用于指定將計算結果輸出到哪個文件(注:如果不加hdfs://前綴,則默認使用本地文件系統)。
在執行此程序時,很可能會出現錯誤信息,信息如下:

原因是Flink缺少了commons-cli的相關JAR包。從Maven倉庫下載該JAR包,復制到Flink的lib目錄下即可。
(5)查詢輸出結果。在終端窗口中,執行的命令如下:

可以看到以下計算結果:

- Expert C++
- Spring 5.0 By Example
- Android應用程序開發與典型案例
- Learning Neo4j 3.x(Second Edition)
- 程序員修煉之道:通向務實的最高境界(第2版)
- 自然語言處理Python進階
- QGIS By Example
- Apache Spark 2.x for Java Developers
- Mastering JavaScript Design Patterns(Second Edition)
- 精通Python自動化編程
- WordPress 4.0 Site Blueprints(Second Edition)
- 區塊鏈技術與應用
- PLC應用技術(三菱FX2N系列)
- Raspberry Pi Robotic Projects(Third Edition)
- Tableau Desktop可視化高級應用