- Python全棧開發:數據分析
- 夏正東編著
- 4177字
- 2023-07-17 20:52:44
1.4.2 網頁數據解析庫
由于HTML文檔本身就是結構化的文本,并且具有一定的規則,所以通過解析該結構就可以提取指定的數據,于是就有了lxml、Beautiful Soup和PyQuery等網頁信息解析庫,其中,lxml庫具有很高的解析效率,并且支持XPath語法;Beautiful Soup庫翻譯成中文就是“美麗的湯”,這個奇特的名字源自于《愛麗絲夢游仙境》,可以用于從HTML或XML文件中提取數據;PyQuery庫則得名于jQuery,可以使用類似jQuery的語法對網頁中指定的數據進行解析。
1.lxml庫
lxml庫是一款高性能的HTML和XML解析器,其主要功能是解析和提取HTML或XML中的數據,并且lxml庫支持XPath語法,可以快速定位特定的元素及節點信息。關于XPath的基礎語法在《Python全棧開發——基礎入門》一書中已經詳細講解過,這里不再贅述。
可以通過lxml.etree模塊中的HTML()方法對HTML字符串進行解析,其語法格式如下:
HTML(text)
其中,參數text表示HTML字符串。
此外,HTML()方法會返回一個_Element對象,該對象具有一個xpath()方法,用于快速定位特定的元素及節點信息。
下面就以爬取百度貼吧(Python吧)中帖子的點贊次數、標題和作者名稱為例,講解如何使用lxml庫進行網頁數據解析,示例代碼如下:


圖1-21 點贊次數、文章標題和作者名稱
2.Beautiful Soup庫
Beautiful Soup是一個高效的網頁解析庫,可以從HTML或XML文件中提取數據。其最大的特點是簡單易用,不必像正則表達式和XPath一樣需要記住很多特定的語法,盡管那樣效率會更高更直接,但是對于大多數初學網絡爬蟲的讀者來講,好用比高效更重要,因為爬取所需的數據才是最終的目的。
Beautiful Soup屬于Python的第三方庫,所以需要進行安裝,只需在命令提示符中輸入命令pip install beautifulsoup4。
在完成安裝后,需要引入該包才可以正常使用Beautiful Soup進行編程,需要注意的是,引入的包名是bs4,而不是beautifulsoup4,示例代碼如下:
#資源包\Code\chapter1\1.4\0135.py
import bs4
Beautiful Soup會將HTML文檔轉換成一個復雜的樹形結構,而其中的每個節點都是一個Python對象,該對象可分為4種,即BeautifulSoup對象、Tag對象、NavigableString對象和Comment對象。
1)BeautifulSoup對象
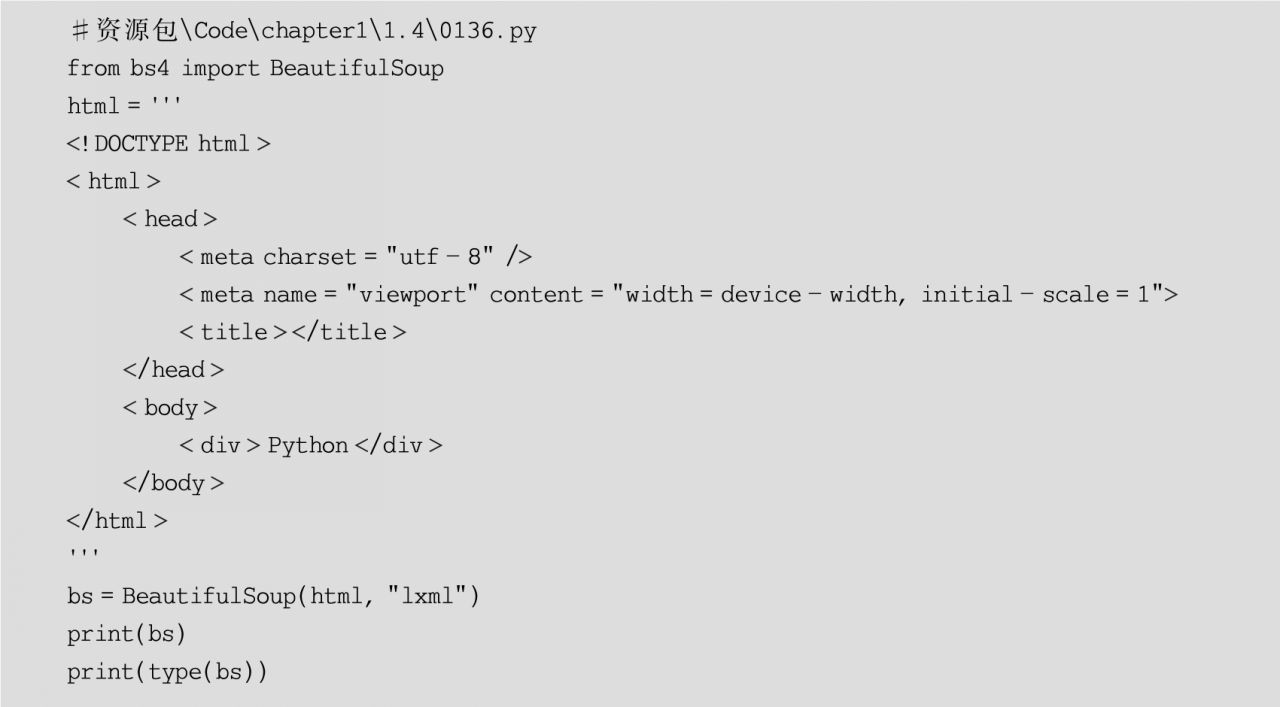
該對象表示HTML文檔的全部內容,可以通過BeautifulSoup類創建BeautifulSoup對象,其語法格式如下:
BeautifulSoup(markup,features)
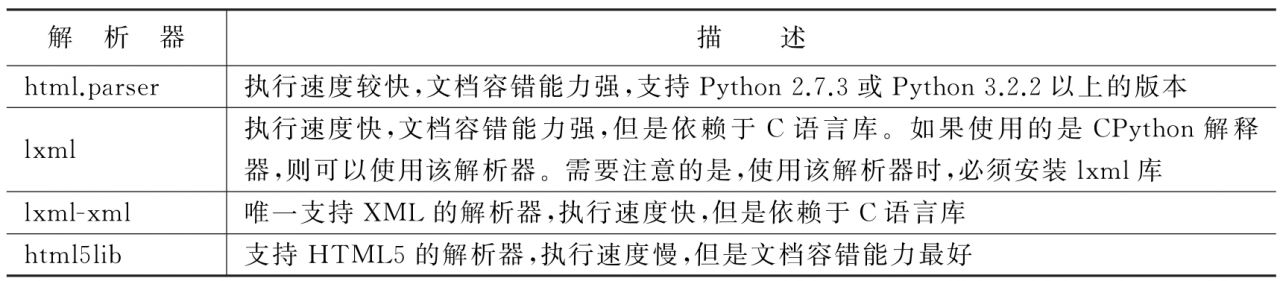
其中,參數markup表示待分析的字符串;參數features表示解析器,主要用于對HTML、XML和HTML5等進行解析,其類別如表1-11所示。
表1-11 BeautifulSoup的解析器
示例代碼如下:
2)Tag對象
該對象表示HTML文檔中的標簽,可以通過“BeautifulSoup對象+選擇器”的方式創建Tag對象,其中的選擇器包括以下3種:
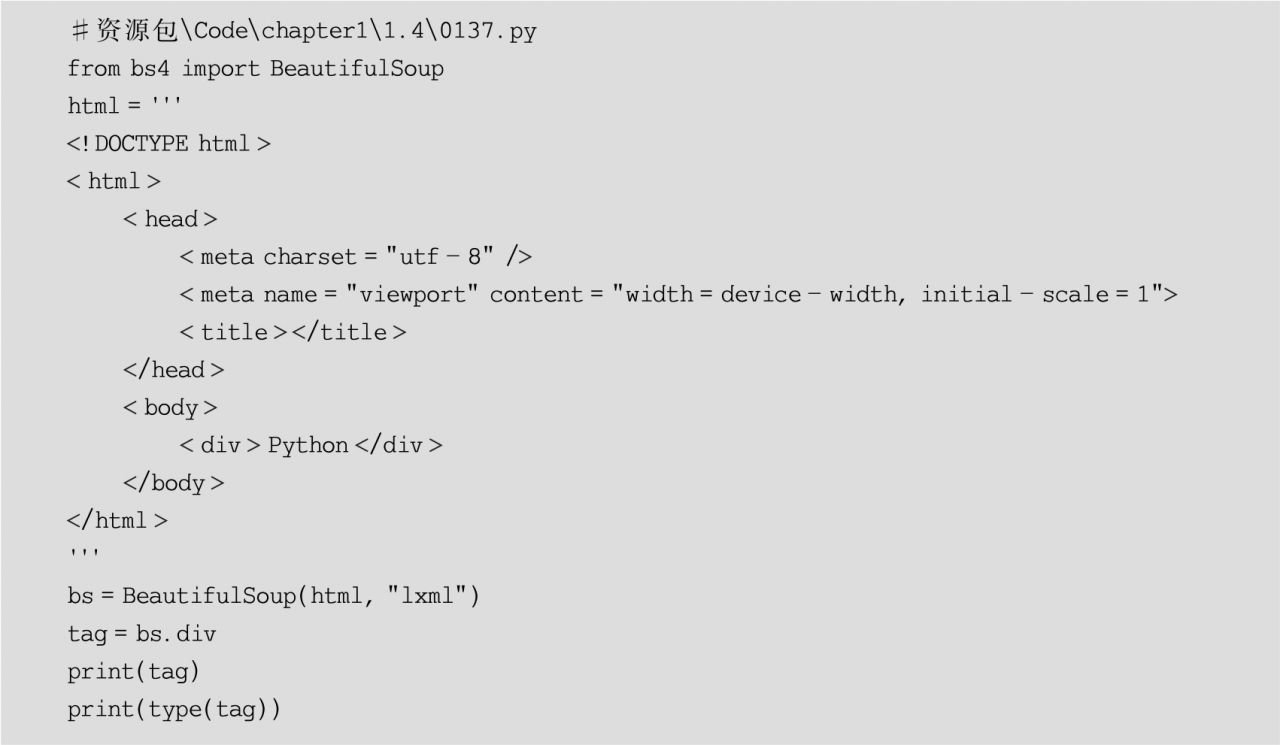
(1)節點選擇器,當待獲取節點的結構層次非常清晰時,建議使用該選擇器,其使用方式如下:
beautifulsoup.tag[.tag]
其中,beautifulsoup表示BeautifulSoup對象;tag表示標簽,如title、li、a等,注意,標簽可以進行嵌套選擇。
示例代碼如下:
(2)方法選擇器,當待獲取節點的結構層次比較復雜時,建議使用該選擇器,其包括兩種常用的方法:
一是find_all()方法。該方法用于獲取與節點名、屬性、文本內容等相符合的所有節點,并返回一個ResultSet對象,其語法格式如下:
find_all(name,attrs,text)
其中,參數name表示節點名;參數attrs表示屬性名和屬性值組成的字典;參數text表示文本內容。
此外,通過對ResultSet對象進行迭代處理,可以進一步獲取Tag對象。
示例代碼如下:

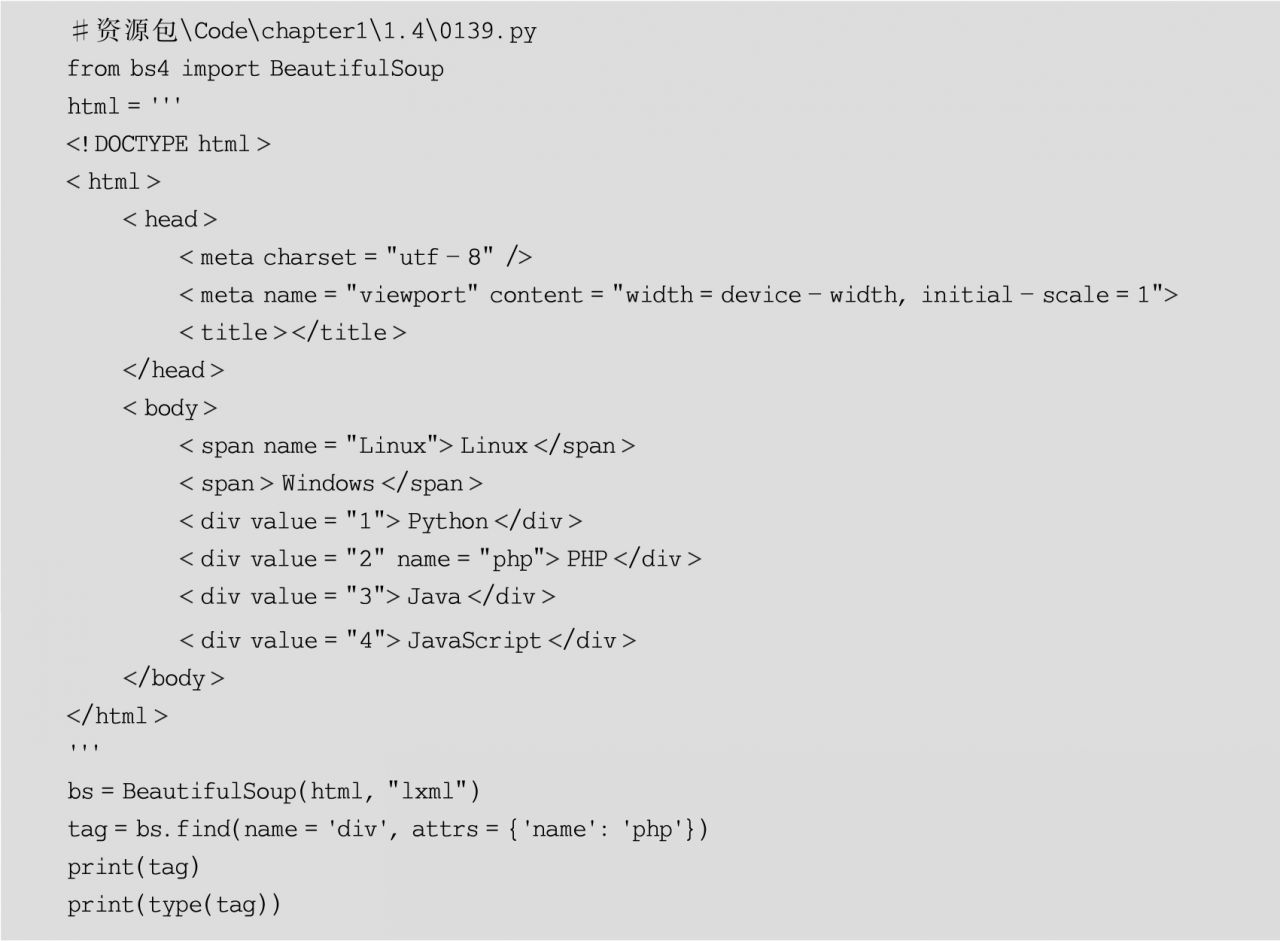
二是find()方法。該方法用于獲取與節點名、屬性、文本內容等相符合的第1個節點,并返回一個Tag對象,其語法格式如下:
find(name,attrs,text)
其中,參數name表示節點名;參數attrs表示屬性名和屬性值組成的字典;參數text表示文本內容。
示例代碼如下:
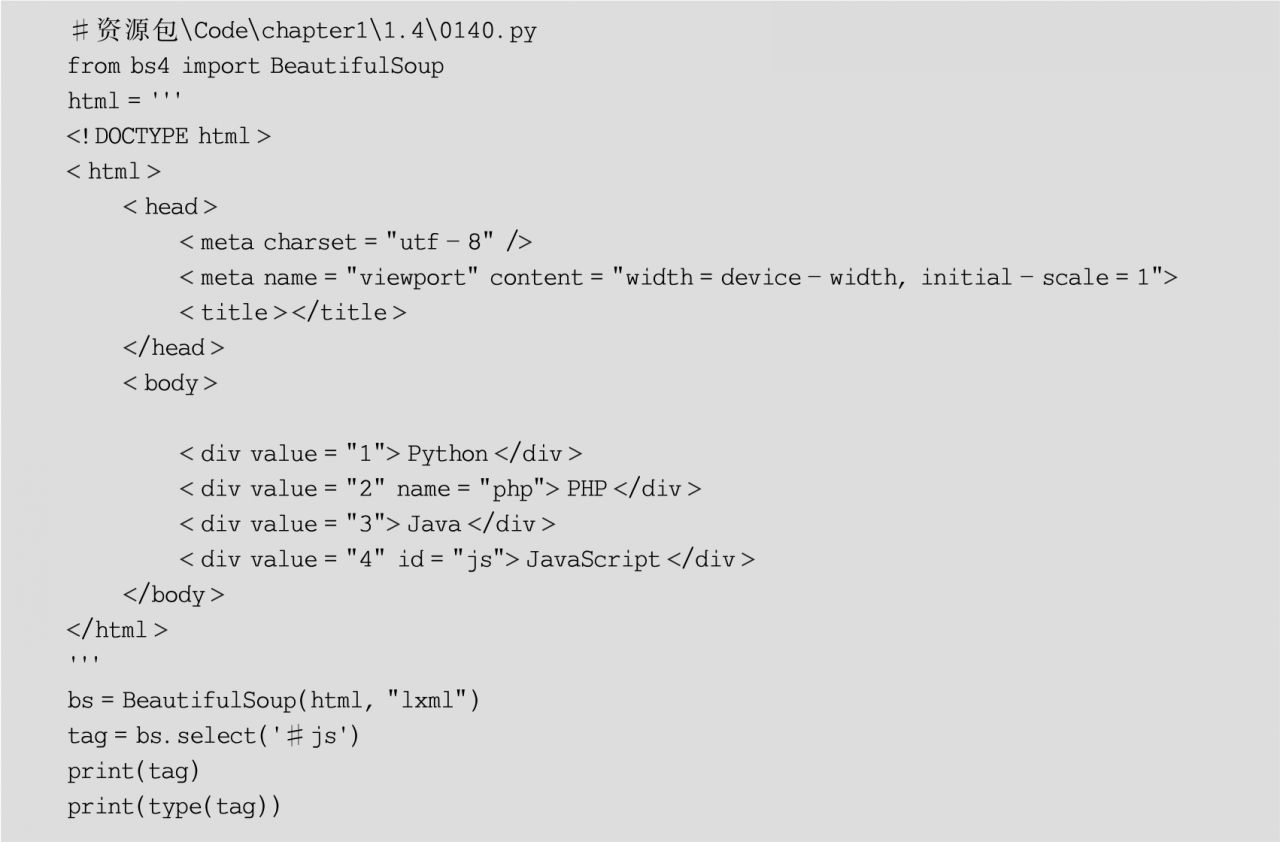
(3)CSS選擇器,該選擇器主要借助CSS選擇器進行節點的篩選,并且需要通過BeautifulSoup對象的select()方法實現,該方法返回一個ResultSet對象,其語法格式如下:
select(selector)
其中,參數selector表示CSS選擇器。
示例代碼如下:
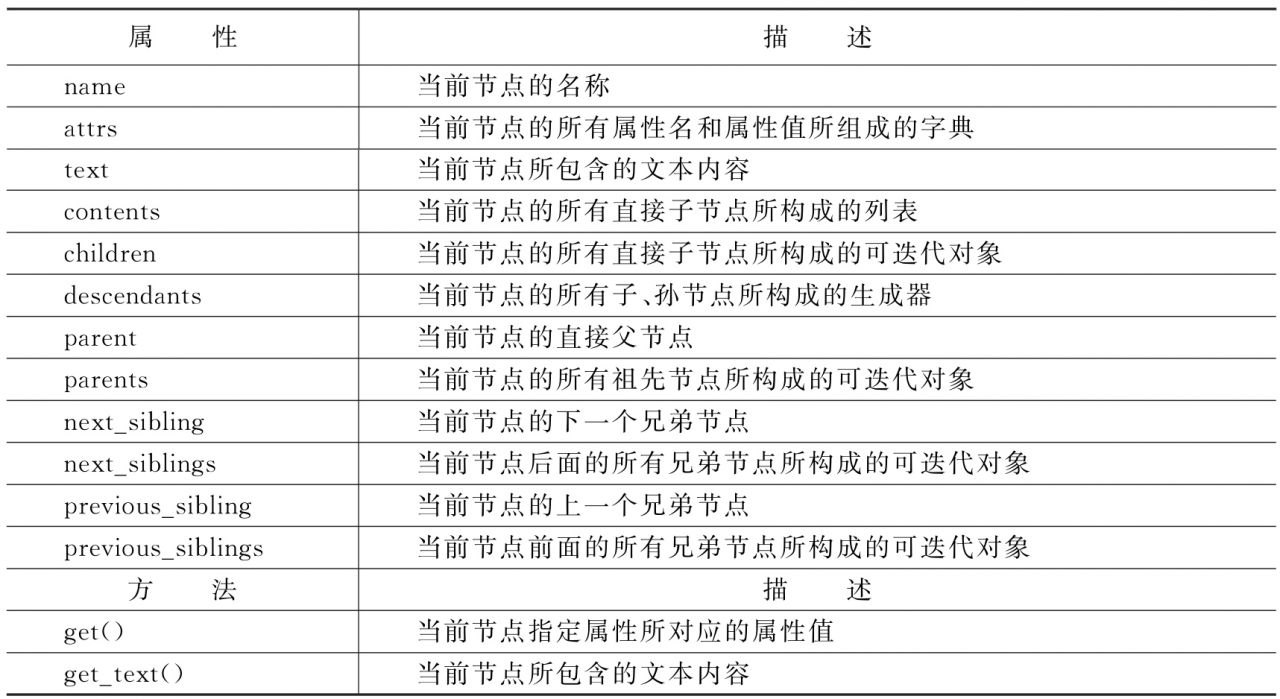
在通過上面所介紹的3個選擇器獲取Tag對象后,就可以通過Tag對象的相關屬性和方法獲取當前節點的信息,其相關屬性和方法如表1-12所示。
表1-12 Tag對象的相關屬性和方法
這里需要重點注意的是,節點中不僅只有Tag對象一種,還包括后面即將講解的NavigableString對象和Comment對象,所以在處理節點之間的關系時,如子孫節點、兄弟節點等,務必注意節點中的NavigableString對象和Comment對象。
示例代碼如下:

3)NavigableString對象
該對象表示HTML文檔中的文本內容、換行符,以及標簽中的文本內容等,可以通過“BeautifulSoup對象+string”的方式獲取NavigableString對象。
示例代碼如下:

4)Comment對象
該對象是一個特殊的NavigableString對象,表示包含注釋的文本內容。與NavigableString對象一樣,可以通過“BeautifulSoup對象+string”的方式獲取Comment對象。
示例代碼如下:

此外,還可以通過Beautiful Soup對節點進行動態修改,為在某些特定的場景下獲取節點信息帶來極大的便利。
1)刪除節點
可以通過BeautifulSoup對象的decompose()方法刪除Tag對象節點,其語法格式如下:
decompose()
可以通過BeautifulSoup對象的extract()方法刪除Tag對象節點、NavigableString對象節點或Comment對象節點,其語法格式如下:
extract()
示例代碼如下:

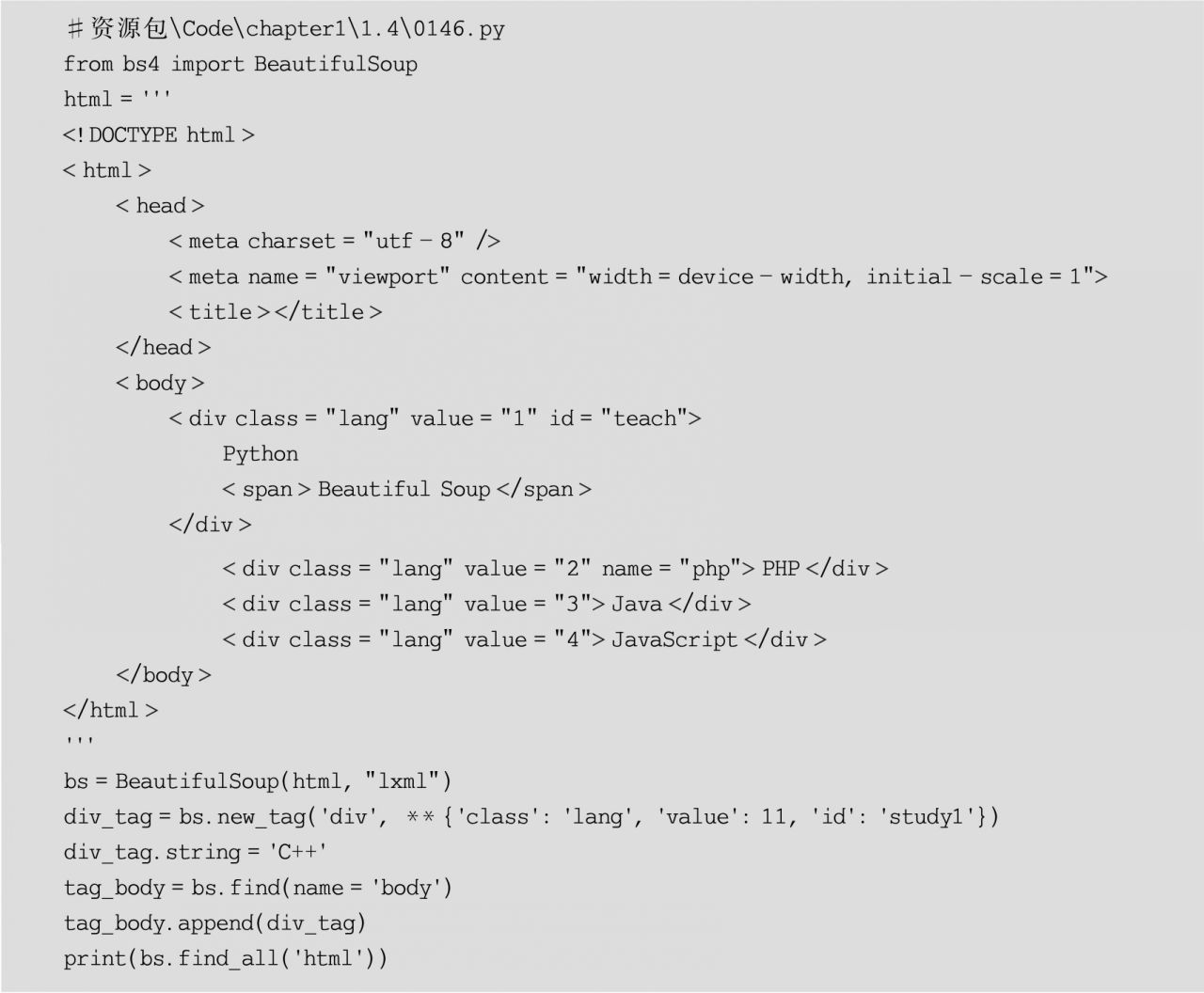
2)添加節點
首先,需要使用BeautifulSoup對象的相關方法生成一個新的節點,其常用的方法如下:
(1)new_tag()方法,該方法用于生成Tag對象節點,其語法格式如下:
new_tag(name,**kwattrs)
其中,參數name表示標簽名;參數kwattrs表示屬性名和屬性值所組成的字典。
(2)new_string()方法,該方法用于生成NavigableString對象節點,其語法格式如下:
new_string(s)
其中,參數s表示文本內容。
其次,在生成新的節點后,通過該節點的相關方法進行添加,其常用的方法如下:
(1)append()方法,該方法表示在當前節點的末尾添加節點,其語法格式如下:
append(tag)
其中,參數tag表示節點。
(2)insert()方法,該方法表示在當前節點的指定位置添加節點,其語法格式如下:
insert(position,new_child)
其中,參數position表示添加的位置;參數new_child表示節點。
(3)insert_before()方法,該方法表示在當前節點前添加節點,其語法格式如下:
insert_before(new_child)
其中,參數new_child表示節點。
(4)insert_after()方法,該方法表示在當前節點后添加節點,其語法格式如下:
insert_after(new_child)
其中,參數new_child表示節點。
示例代碼如下:

3)修改節點文本內容
可以通過節點的屬性string對文本內容進行修改,其語法格式如下:
string
示例代碼如下:
4)刪除節點文本內容
可以通過節點的clear()方法對文本內容進行刪除,其語法格式如下:
clear()
示例代碼如下:

5)修改節點屬性
可以通過“節點[屬性名]”的形式修改節點的屬性,示例代碼如下:

6)刪除節點屬性
可以通過del語句刪除節點的屬性,示例代碼如下:

7)替換節點
可以通過節點的replace_with()方法對當前節點進行替換,其語法格式如下:
replace_with(replace_with)
其中,參數replace_with表示HTML字符串或節點,示例代碼如下:

3.PyQuery庫
具有Web前端開發經驗的程序員都知道jQuery選擇器的功能要強于CSS選擇器,因此,雖然Beautiful Soup的功能非常強大,但是其CSS選擇器的功能相對較弱,而此時PyQuery庫就是絕佳選擇了。PyQuery庫同樣是一個非常強大且靈活的網頁解析庫,是仿照jQuery語法封裝成的一個包,其語法與jQuery幾乎完全相同,可以用于網頁數據的解析。
PyQuery庫屬于Python的第三方庫,所以需要進行安裝,只需在命令提示符中輸入命令pip install pyquery。
1)解析HTML
在使用PyQuery庫提取指定節點的信息前,首先需要使用pyquery模塊中的PyQuery類對HTML數據進行解析,解析后的每個節點都是一個PyQuery對象,并且通過對該對象進行迭代,即可獲取一個HtmlElement對象。
PyQuery類可以解析以下3種格式的HTML數據:
(1)HTML字符串,該格式可以使用HTML字符串作為參數進行解析,其語法格式如下:
PyQuery(html_str)
其中,參數html_str表示HTML字符串,示例代碼如下:

(2)URL,該格式可以使用URL作為參數進行解析,其語法格式如下:
PyQuery(html_url)
其中,參數html_url表示URL,示例代碼如下:
#資源包\Code\chapter1\1.4\0152.py
from pyquery import PyQuery as pq
pq_obj=pq(url='http://www.oldxia.com')
print(pq_obj)
print(type(pq_obj))
(3)HTML文件,該格式可以使用HTML文件作為參數進行解析,其語法格式如下:
PyQuery(filename)
其中,參數filename表示HTML文件的名稱,示例代碼如下:
#資源包\Code\chapter1\1.4\01\0153.py
from pyquery import PyQuery as pq
pq_obj=pq(filename='index.html')
print(pq_obj)
print(type(pq_obj))
2)獲取節點
在使用PyQuery類對HTML數據進行解析后,可以通過“PyQuery對象+選擇器”的方式獲取指定的節點,其中選擇器包括以下3種:
(1)節點選擇器,當需要獲取節點的結構層次非常清晰時,建議使用該種選擇器,其使用方式如下:
pyquery(tag)
其中,pyquery表示PyQuery對象;tag表示標簽,如title、li、a等,注意,標簽可以進行嵌套選擇,示例代碼如下:

(2)jQuery選擇器,該選擇器主要借助jQuery選擇器進行節點的篩選,其使用方式如下:
pyquery(selector)
其中,pyquery表示PyQuery對象;selector表示jQuery選擇器,示例代碼如下:

(3)方法選擇器,當需要獲取節點的結構層次比較復雜時,建議使用該選擇器,其包括以下5種常用的方法:
一是find()方法,該方法用于獲取符合條件的所有節點,其語法格式如下:
find(selector)
其中,參數selector表示節點選擇器或jQuery選擇器。
二是children()方法,該方法用于獲取符合條件的所有直接子節點,其語法格式如下:
children(selector)
其中,參數selector為可選參數,表示節點選擇器或jQuery選擇器,默認表示無條件。
三是parent()方法,該方法用于獲取符合條件的直接父節點,其語法格式如下:
parent(selector)
其中,參數selector為可選參數,表示節點選擇器或jQuery選擇器,默認表示無條件。
四是parents()方法,該方法用于獲取符合條件的所有祖先節點,其語法格式如下:
parents(selector)
其中,參數selector為可選參數,表示節點選擇器或jQuery選擇器,默認表示無條件。
五是siblings()方法,該方法用于獲取符合條件的所有兄弟節點,其語法格式如下:
siblings(selector)
其中,參數selector為可選參數,表示節點選擇器或jQuery選擇器,默認表示無條件。
示例代碼如下:

3)獲取節點信息
在獲取節點后,可以通過HtmlElement對象或PyQuery對象的相關屬性和方法提取節點的信息。
(1)HtmlElement對象,通過對PyQuery對象進行迭代或使用索引方式就可以得到HtmlElement對象,其相關屬性和方法如表1-13所示。
表1-13 HtmlElement對象的相關屬性和方法

示例代碼如下:

(2)PyQuery對象,該對象的相關方法如表1-14所示。
表1-14 PyQuery對象的相關方法

此外,由于對PyQuery對象進行迭代所獲得的是HtmlElement對象,所以如果想通過迭代獲得PyQuery對象,則需要使用PyQuery對象的items()方法,示例代碼如下:

4)修改節點
可以通過PyQuery對節點進行動態修改,為在某些特定的場景下獲取節點信息帶來極大的便利。
(1)刪除節點,可以通過PyQuery對象的remove()方法刪除節點,其語法格式如下:
remove(expr)
其中,參數expr為可選參數,表示節點選擇器或jQuery選擇器,默認表示無條件,示例代碼如下:

(2)添加節點,可以通過PyQuery對象的prepend()方法或append()方法分別在頭部或尾部添加節點,其語法格式分別如下:
prepend(value)
其中,參數value表示HTML字符串。
append(value)
其中,參數value表示HTML字符串。
示例代碼如下:

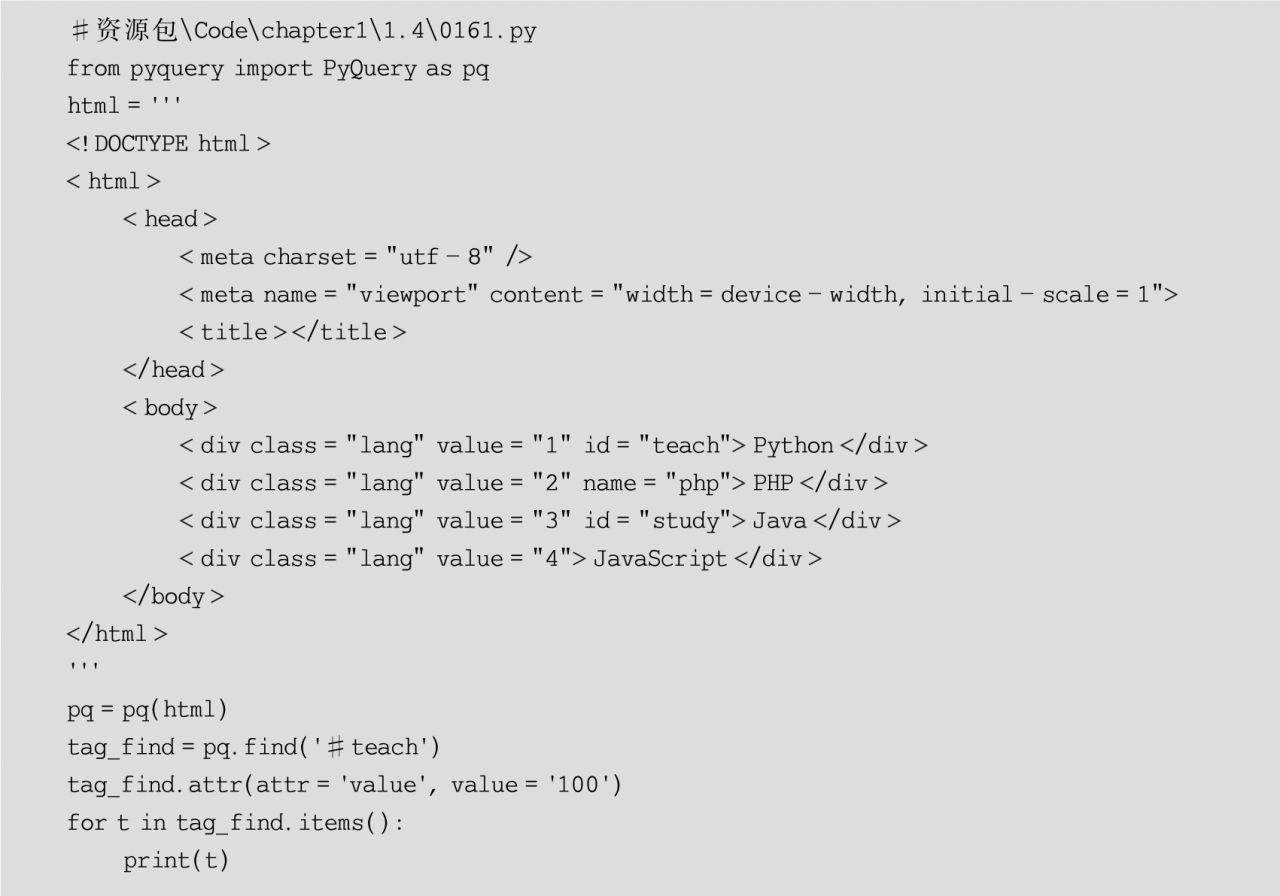
(3)修改節點屬性,可以通過PyQuery對象的attr()方法修改節點屬性,其語法格式如下:
attr(attr,value)
其中,參數attr表示屬性名稱;參數value表示屬性值,示例代碼如下:
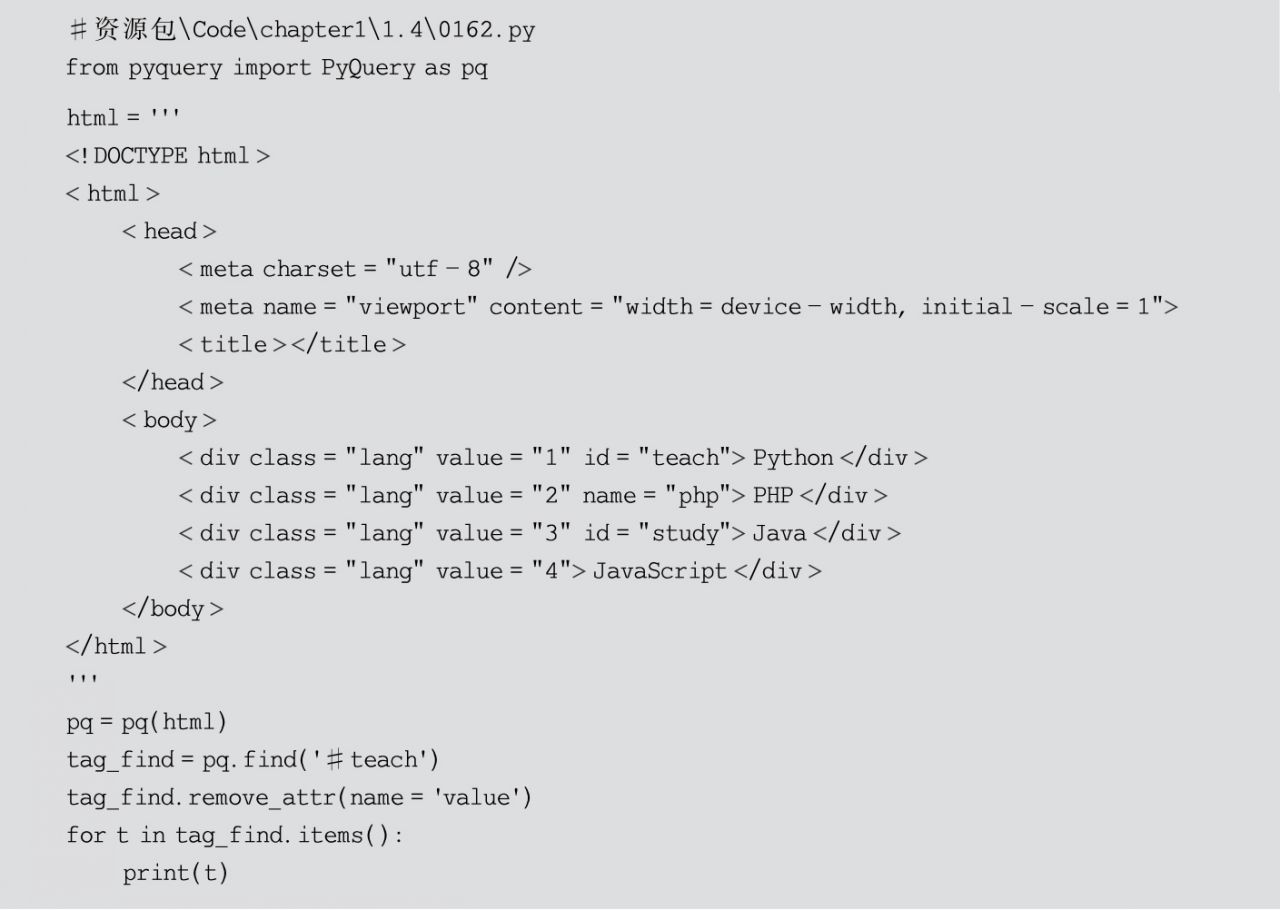
(4)刪除節點屬性,可以通過PyQuery對象的remove_attr()方法刪除節點屬性,其語法格式如下:
remove_attr(name)
其中,參數name表示屬性名稱,示例代碼如下:
(5)修改節點文本內容,可以通過PyQuery對象的text()方法或html()方法修改節點的文本內容,其語法格式分別如下:
text(value)
其中,參數value表示文本內容。
html(value)
其中,參數value表示文本內容。
示例代碼如下:

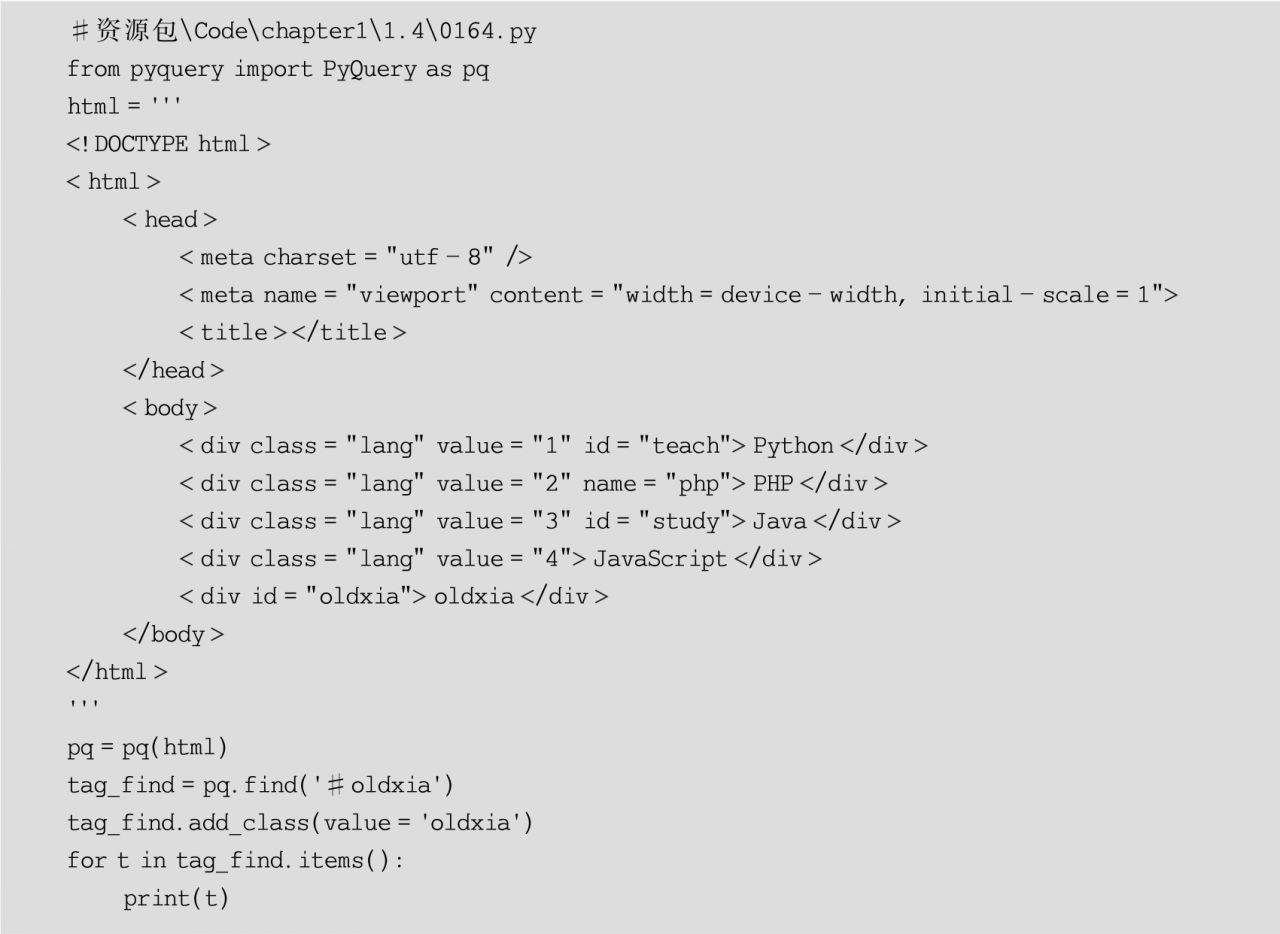
(6)添加節點樣式,可以通過PyQuery對象的add_class()方法添加節點樣式,其語法格式如下:
add_class(value)
其中,參數value表示屬性class的屬性值,示例代碼如下:
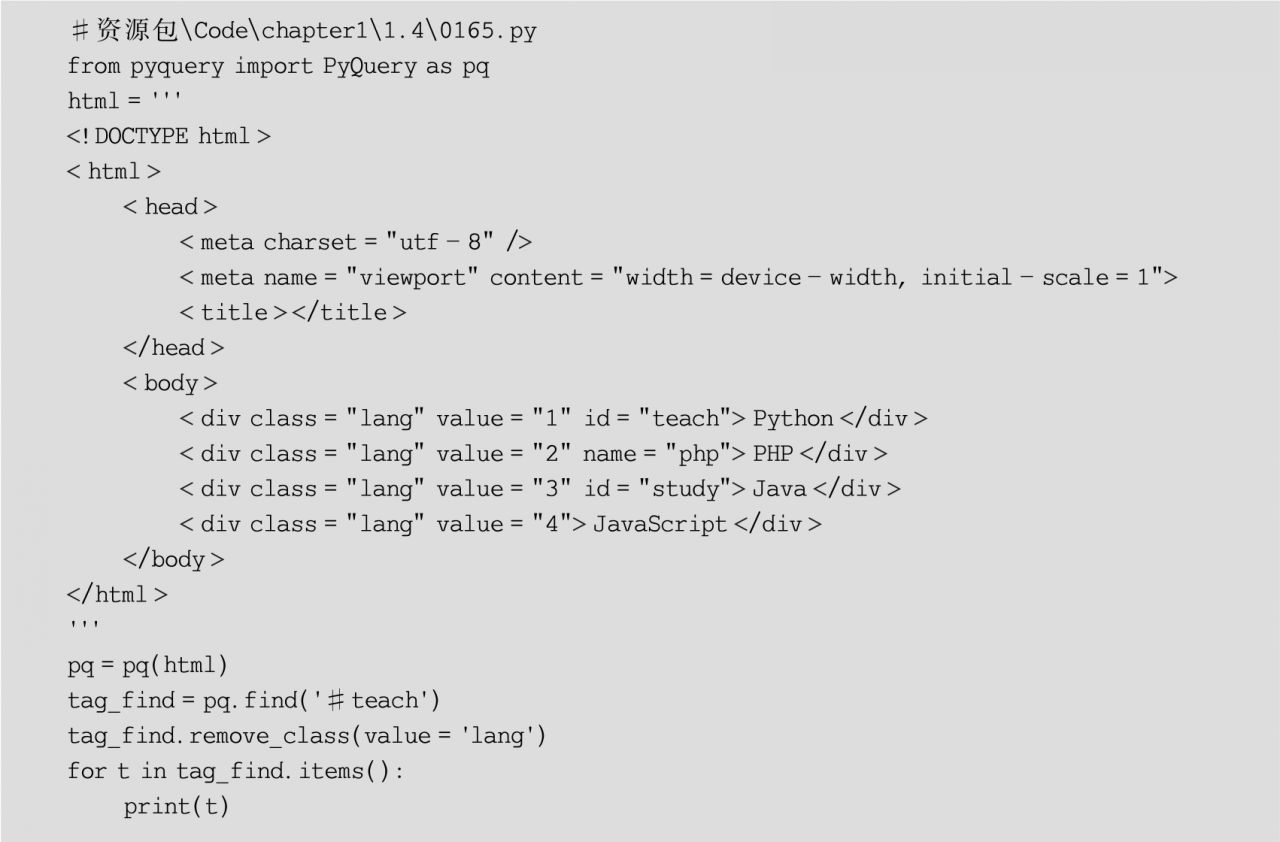
(7)刪除節點樣式,可以通過PyQuery對象的remove_class()方法刪除節點樣式,其語法格式如下:
remove_class(value)
其中,參數value表示屬性class的屬性值,示例代碼如下:
- Google Flutter Mobile Development Quick Start Guide
- Web前端開發技術:HTML、CSS、JavaScript(第3版)
- 零基礎搭建量化投資系統:以Python為工具
- C程序設計簡明教程(第二版)
- Python量化投資指南:基礎、數據與實戰
- 劍指Offer(專項突破版):數據結構與算法名企面試題精講
- Programming ArcGIS 10.1 with Python Cookbook
- BeagleBone Media Center
- NativeScript for Angular Mobile Development
- C語言程序設計實踐教程
- 精通Python設計模式(第2版)
- App Inventor 2 Essentials
- SQL Server 2008中文版項目教程(第3版)
- Simulation for Data Science with R
- 深度學習入門:基于Python的理論與實現