- Python機(jī)器學(xué)習(xí)技術(shù):模型關(guān)系管理
- 丁亞軍
- 2087字
- 2023-04-25 10:15:54
1.1 數(shù)據(jù)源
數(shù)據(jù)源可以分為結(jié)構(gòu)化數(shù)據(jù)與非結(jié)構(gòu)化數(shù)據(jù)兩種基本形式,結(jié)構(gòu)化數(shù)據(jù)表現(xiàn)為數(shù)值,其形狀為行大于列(長數(shù)據(jù)[1]),涉及低維問題;半結(jié)構(gòu)化數(shù)據(jù)表現(xiàn)為圖像與自然語言,其形狀為列大于行(寬數(shù)據(jù)②),涉及高維問題。機(jī)器學(xué)習(xí)如何充分利用不同形狀的數(shù)據(jù)達(dá)到分析的目的是本節(jié)的重點(diǎn)。
1.1.1 數(shù)值:單元格
對于大數(shù)據(jù)而言,數(shù)據(jù)往往存儲于數(shù)據(jù)庫,一行表示一條觀測值的所有信息是經(jīng)典數(shù)據(jù)格式,幾乎可以應(yīng)用于所有的數(shù)據(jù)分析領(lǐng)域。然而,觀測值在不同場景下的含義不盡相同,可以表示客戶的喜好行為,也可以表示一筆訂單、一次物流等。
單元格示意如圖1-1-1所示,從列的角度可以觀察到群體特征,并使用數(shù)據(jù)分布來描述群體信息。從行的角度只能觀察到一個人的信息,觀察不到群體特征,如客戶003的年齡是52歲。可見,單元格同時具有行、列信息,這就是數(shù)據(jù)框(Dataframe),進(jìn)而可以展開相關(guān)分析(列間)與距離分析(行間),這也是構(gòu)建模型的基礎(chǔ)。
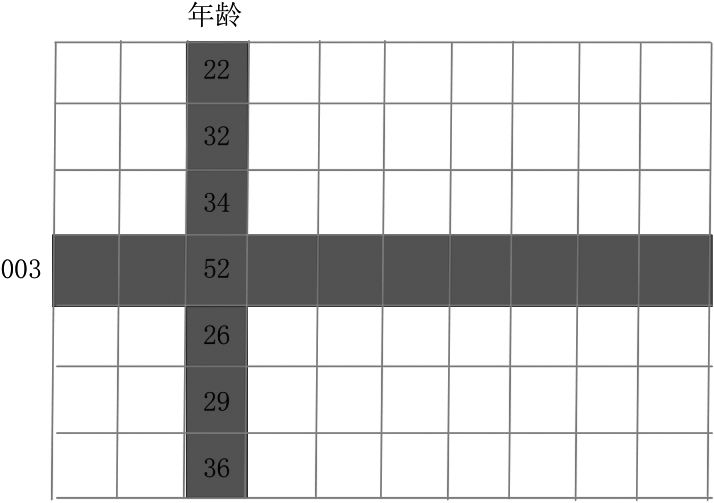
圖1-1-1 單元格示意
1.1.2 圖像:像素點(diǎn)
圖像分析中將視頻、圖片視為同一種圖像類型,并以像素為分析的基礎(chǔ)單元。對于機(jī)器學(xué)習(xí)而言,需要將像素平鋪成一行,即一行表示一張圖片,一列表示圖片中的每個像素點(diǎn),如圖1-1-2(a)所示,照片由3個維度(3968×2976×3)組成,數(shù)值3表示RGB的3個通道。
圖像分析的重點(diǎn)在于圖像梯度[2],對于計算機(jī)而言,顏色對梯度的影響往往是相對的,所以通常轉(zhuǎn)化為單通道,即灰色[見圖1-1-2(b)]。因為不同圖像的尺寸不同,所以需要將圖像約束為相同的尺寸[見圖1-1-2(c)],否則平鋪后的數(shù)據(jù)維度會參差不齊,存在大量缺失。此外,還需要考慮圖像尺寸,尺寸太大會增加運(yùn)算量,太小則容易出現(xiàn)馬賽克,模糊不清[見圖1-1-2(d)]。

圖1-1-2 圖片像素
圖像數(shù)據(jù)的平鋪過程如圖1-1-3所示,圖1-1-3(a)~圖1-1-3(d)分別對應(yīng)圖1-1-2(a)~圖1-1-2(d)。可見,一張圖片構(gòu)成了圖像數(shù)據(jù)的行信息,第一個像素點(diǎn)對應(yīng)第一個維度,即通常意義上的自變量。當(dāng)前圖片共有100個像素點(diǎn)(10×10),則對應(yīng)100個維度,因此圖像數(shù)據(jù)是典型的高維數(shù)據(jù),維度達(dá)到百萬級,甚至千萬級都很正常。
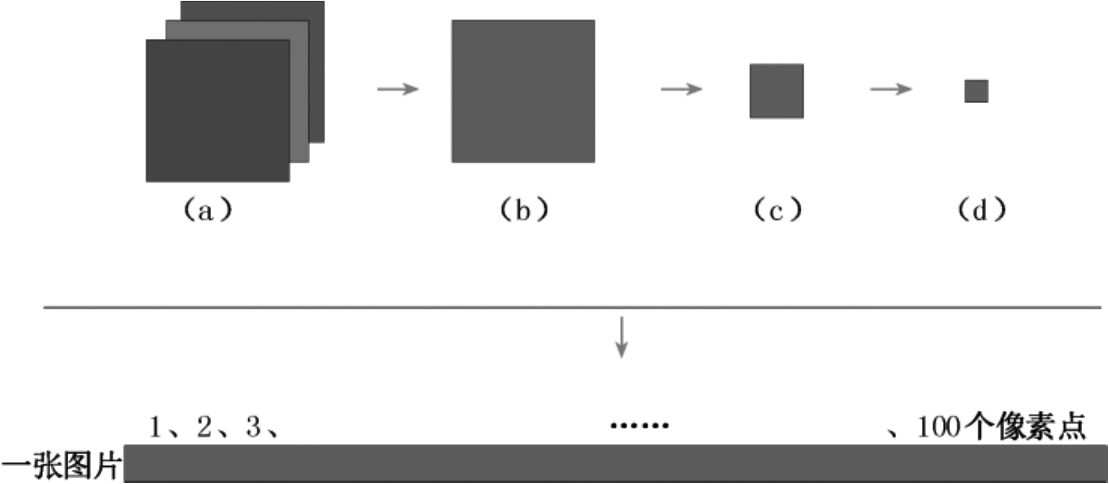
圖1-1-3 圖像數(shù)據(jù)的平鋪過程
1.1.3 文本:詞向量
1.文本編碼
文本編碼首先將文本轉(zhuǎn)化為數(shù)值,然后基于一定規(guī)則轉(zhuǎn)化為數(shù)據(jù)向量。以數(shù)據(jù)向量的方式出現(xiàn)便于模型使用,適用于機(jī)器學(xué)習(xí)和深度學(xué)習(xí)。
假設(shè)文本數(shù)據(jù)是“我愛工作同樣也愛家庭”。
文本編碼需要文本分詞技術(shù),通過分詞賦予文本數(shù)值含義,分詞后的文本中,0表示“我”、1表示“愛”、2表示“工”、……、8表示“庭”[3],數(shù)據(jù)編碼后的形式為0我1愛2工3作4同5樣6也1愛7家8庭,其中,“愛”是重復(fù)的,也用數(shù)值1來表示。此外,將文本中某個詞作為y的取值,其上下文對應(yīng)的詞作為x的取值,得到如下編碼形式:

可見,單詞的上下文構(gòu)成了預(yù)測因素,當(dāng)前值是被預(yù)測的對象。
以上是機(jī)器學(xué)習(xí)中常用的編碼形式,獨(dú)熱編碼也可以用于機(jī)器學(xué)習(xí),但常用于深度學(xué)習(xí)。
2.文本獨(dú)熱編碼
數(shù)據(jù)向量x和y可以作為數(shù)據(jù)源(y表示因變量,x表示自變量,下同),但這種數(shù)據(jù)格式更適用于機(jī)器學(xué)習(xí),而深度學(xué)習(xí)經(jīng)常需要對x和y進(jìn)行獨(dú)熱編碼(或啞變量中的GLM變換),其編碼形式如下:

轉(zhuǎn)化為獨(dú)熱編碼后,x的行 對應(yīng)
對應(yīng) 和
和 ,某個詞作為目標(biāo)后,同樣也將該詞上下文對應(yīng)的詞作為自變量x,因此需要2行x對應(yīng)1行y。若某個目標(biāo)詞對應(yīng)上下文6個詞(一側(cè)3個詞),則需要增加6行x與1行y,以此類推。
,某個詞作為目標(biāo)后,同樣也將該詞上下文對應(yīng)的詞作為自變量x,因此需要2行x對應(yīng)1行y。若某個目標(biāo)詞對應(yīng)上下文6個詞(一側(cè)3個詞),則需要增加6行x與1行y,以此類推。
若文本數(shù)據(jù)“我愛工作同樣也愛家庭”對應(yīng)y的取值為0,并且第二行文本“我愛足球運(yùn)動”對應(yīng)y的取值為1,則可以得到如下編碼:0我1愛2工3作4同5樣6也1愛7家8庭、0我1愛9足10球11運(yùn)12動,數(shù)值編碼可以順延下去,其數(shù)據(jù)向量的形式:
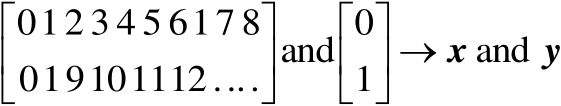
可見,x的維度是(2,10),y的維度是(2,1),盡管x的第二行數(shù)據(jù)不可避免地存在缺失值,但當(dāng)文本序列比較長時,一般不影響文本分析。
3.軟件包與代碼
統(tǒng)計學(xué)習(xí)和機(jī)器學(xué)習(xí)軟件包(如Statsmodels和Sklearn)主要以數(shù)值為分析對象,很少有非結(jié)構(gòu)化數(shù)據(jù)的直接導(dǎo)入接口,一般需要用戶手動轉(zhuǎn)換,而深度學(xué)習(xí)軟件包,如Keras、Tensorflow、Torch等,則提供了各類非結(jié)構(gòu)化數(shù)據(jù)的豐富接口。
知識拓展 (重要性★★☆☆☆)
半結(jié)構(gòu)化數(shù)據(jù)
區(qū)別結(jié)構(gòu)化數(shù)據(jù)和非結(jié)構(gòu)化數(shù)據(jù)的一個非正式的定義是數(shù)據(jù)的列是否存在意義。例如,結(jié)構(gòu)化數(shù)據(jù)中,年齡是有意義的,但非結(jié)構(gòu)化數(shù)據(jù)中,圖像像素對應(yīng)的列卻很難賦予實際意義。
某個案庫系統(tǒng)中,如果要求機(jī)臺工人在機(jī)油欄中記錄經(jīng)驗,那么機(jī)油是列標(biāo)簽,具有結(jié)構(gòu)化數(shù)據(jù)的特征。如果發(fā)生機(jī)械震動問題,那么在震動欄中記錄的所致問題是結(jié)構(gòu)化數(shù)據(jù)。但是如果發(fā)生一個全新事件,可能無法編碼或無法及時命名,那么此時的數(shù)據(jù)是非結(jié)構(gòu)化的。如果數(shù)據(jù)同時具有結(jié)構(gòu)化和非結(jié)構(gòu)化的特征,那么可以視為半結(jié)構(gòu)化數(shù)據(jù)。半結(jié)構(gòu)化數(shù)據(jù)包括報表、賬單、郵件、掃描文件等。
如果將統(tǒng)計學(xué)習(xí)視為結(jié)構(gòu)化小數(shù)據(jù)的顛覆性算法,那么機(jī)器學(xué)習(xí)就是結(jié)構(gòu)化大數(shù)據(jù)的顛覆性算法,深度學(xué)習(xí)是非結(jié)構(gòu)化數(shù)據(jù)的顛覆性算法。但半結(jié)構(gòu)化數(shù)據(jù)的算法中,盡管已有可加模型、強(qiáng)集成學(xué)習(xí)模型、混合專家模型,但仍未出現(xiàn)可以稱為顛覆性算法的技術(shù)。
不過無需多慮,如果非結(jié)構(gòu)化數(shù)據(jù)已經(jīng)大到足以產(chǎn)生巨量價值,那么數(shù)據(jù)科學(xué)家們必將蜂擁而至,這個領(lǐng)域的百花齊放之日也將加速到來。
- 單片機(jī)應(yīng)用技術(shù)
- 精通Linux(第2版)
- Java EE 7 Performance Tuning and Optimization
- Mastering Android Game Development
- Natural Language Processing with Java and LingPipe Cookbook
- Java語言程序設(shè)計教程
- FPGA嵌入式項目開發(fā)實戰(zhàn)
- Managing Microsoft Hybrid Clouds
- RocketMQ實戰(zhàn)與原理解析
- 邊玩邊學(xué)Scratch3.0少兒趣味編程
- Building Business Websites with Squarespace 7(Second Edition)
- INSTANT JQuery Flot Visual Data Analysis
- 安卓工程師教你玩轉(zhuǎn)Android
- SFML Game Development
- Java Web開發(fā)基礎(chǔ)與案例教程