- 智能制造系統及關鍵使能技術
- 唐敦兵等主編
- 4357字
- 2022-05-06 17:04:57
3.4 大數據與智能制造的關系
3.4.1 制造大數據處理架構
3.4.1.1 Hadoop分布式大數據處理架構
Hadoop分布式大數據處理系統在運行過程中主要是由一個主控節點和若干個從節點組成的,主控節點主要集成在集群主控節點里面,而從節點則由本地Linux文件系統、DataNode等組成。Hadoop平臺的基本組成與生態系統如圖3-8所示。其中,整個并行計算集群的運行主要是由主節點負責的,同時適配各個子節點當前的進程情況,以降低計算過程中消耗的數據傳輸資源。計算集群中的各個子節點兼備儲存和計算的能力,目的是盡可能地實現在大數據背景下的本地化計算與操作,用以提高系統的計算和處理性能。Hadoop系統設計了實時信息回傳的心跳機制,以此來應對可能出現的故障,主要的原理是主節點會定時向各個子節點發送命令信息,在運行正常的情況下,子節點在接收到命令消息后會向主節點進行信息反饋,當主節點長時間沒有接收到子節點的反饋信息時,該子節點將會被系統判定為失效。
Hadoop分布式大數據處理系統在應用與解決數據存儲及分布式計算算法方面有明顯的優勢,包括分布式存儲系統HDFS、數據倉庫Hive、非關系型數據庫HBase及并行化分布式算法架構MapReduce等。
1)分布式存儲系統HDFS
分布式存儲系統HDFS是Hadoop的分布式文件系統實例化的體現,該系統設計的主要思想就是將一個待處理的數據集合按照一定的規則進行合理分解,分解成不同的數據塊,然后將數據塊分別存儲到分布式的節點中,在數據的讀取和存儲時完成一次存儲和調取。分布式存儲系統HDFS可以很好地適應大規模用戶對存儲的數據進行并發操作和訪問的特性,為大數據系統處理提供了數據存儲端的技術支持。
分布式存儲系統HDFS具體的運行框架與結構如圖3-9所示。首先對事先獲取的處理過的數據傳入系統(此處表示虛擬制造資源)按照要求進行拆分,獲得大小相仿的數據塊,這些數據塊在Hadoop系統中會準確存儲到不同的數據節點中,通過心跳機制向主節點實時反饋數據塊的狀態信息。如果出現節點或者數據的缺失,可以通過冗余備份機制,調用主節點在Hadoop下預先備份的數據塊進行數據恢復,從而使計算集群正常運行。面對數據的讀取和訪問,主節點先對多個數據節點進行訪問,確定數據節點的數據情況,在正常的情況下,用戶通過用戶端對系統數據進行訪問,在定位到相應的數據節點以后,借助Hadoop中的功能模塊對數據進行處理,并向用戶進行展示。
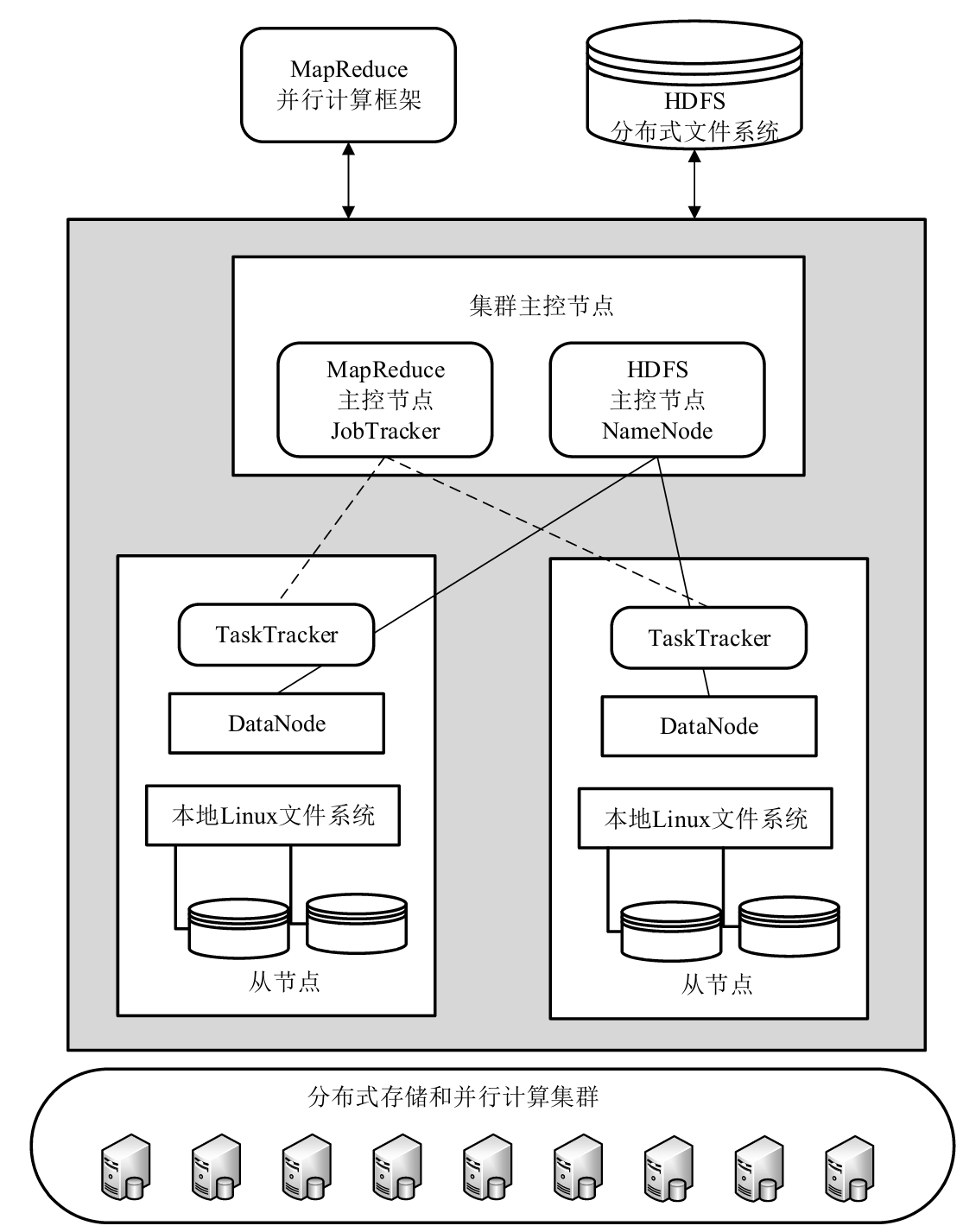
圖3-8 Hadoop平臺的基本組成與生態系統
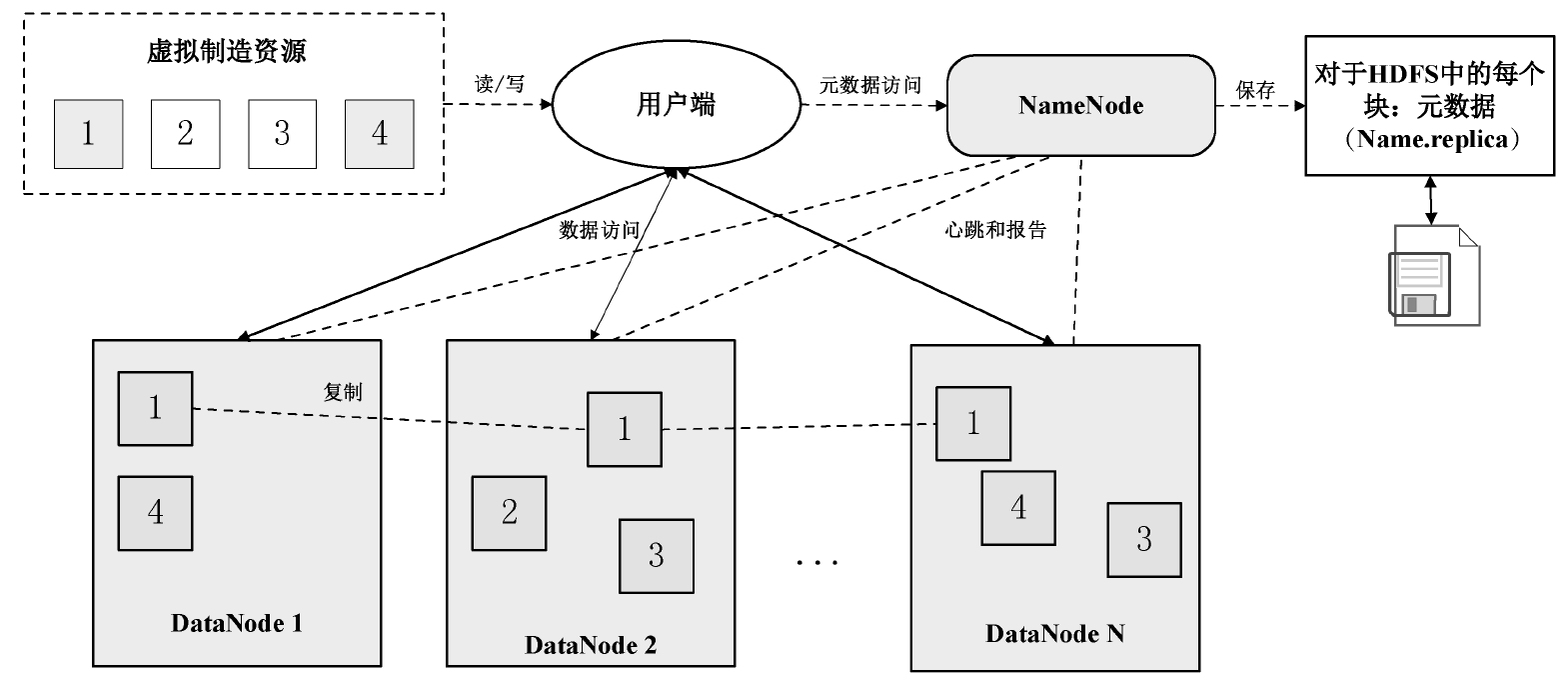
圖3-9 分布式存儲系統HDFS具體的運行框架與結構
2)數據倉庫Hive
數據倉庫Hive是大規模留存數據的數據存儲容器,主要是寫入Hadoop系統的HDFS之中,針對結構化的數據進行寫入和讀取訪問。以HQL語句進行數據庫數據的獲取和寫入,HQL語句和SQL語句在語法上有很多相似之處,方便用戶快速上手,HQL語句可以實現類SQL語句的查詢,同時可以將SQL語句映射成MapReduce中的任務來執行,使得MapReduce算法在底線中進行數據操作更加簡單。Hive支持JDBC與ODBC接口,這樣相應降低了應用的開發難度和成本。
數據倉庫Hive的基本運行架構如圖3-10所示,其根本是Hadoop中的并行化算法MapReduce。數據庫服務端和決策控制端組件構成了Hive中的功能組件。前者可以分成三大事件架構:MetaStore、Driver及Thrift。其中,Hive組件的驅動器就是Drive組件,通過調用Hadoop中并行化計算算法MapReduce分析、編譯和操作HQL語句。而數據倉庫Hive中的MetaStore是單位數據管控組件,能區分開存儲端數據和表格信息數據,可以將兩個數據塊存入兩個分區或者將數據塊存到其他的關系型數據庫,消除數據之間的關聯。為了增加數據倉庫Hive的延展性加入了Thrift組件,以滿足在一個通用編程調用接口的基礎上,實現不同編程語言對數據倉庫Hive數據的訪問和查詢。
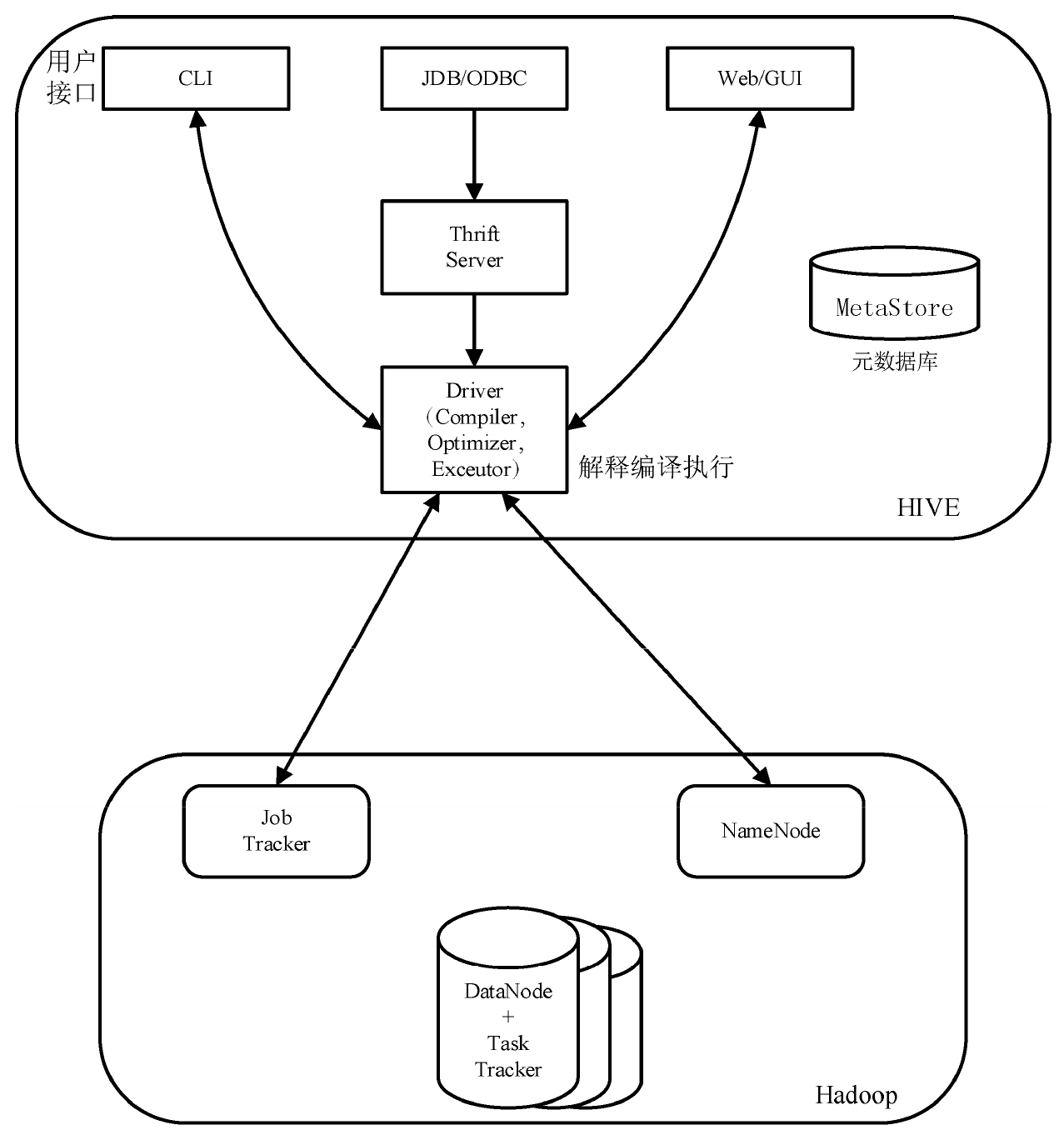
圖3-10 數據倉庫Hive的基本運行架構
對于HBase來說,由于將HDFS作為其底層數據存入的最小單位,也就具有了可以分布式寫入和讀取的功能。同時,HBase可以實時調用HDFS中的功能,使得其在運行過程中可以保障數據的穩定性和完整性。而對MapReduce而言,它是一種分布式并行化的編程與計算模式,引入了Hadoop,極大地簡化了并行計算程序的開發難度。
總而言之,Hadoop分布式大數據處理架構在面對大規模數據的讀取、寫入及分布式計算時具有明顯的優勢。但是,由于Hadoop的處理框架是基于硬盤計算的,難以適應大規模迭代過程算法的場景,因而在大規模數據集的處理中只采用Hadoop中數據存儲部分的功能模塊,計算部分將采用基于內存計算的Spark分布式數據處理架構。
3.4.1.2 Spark分布式數據處理架構
開發一個完整的生態圈就是Spark開發的源頭,Spark生態圈使得一個框架可以完成大數據計算的大部分計算分析工作,如圖3-11所示。由于主要的算力占用是在Spark計算過程中產生的,這也就減輕了硬盤的數據傳輸負載壓力,對于會產生大規模迭代過程的計算算法有明顯的優勢,同時該生態圈還兼顧了數據篩選獲取、流計算和圖計算等多種計算范式,因而和基于硬盤計算的MapReduce相比較,Spark在海量、迭代計算及基于Hive的SQL查詢上能夠給性能提升帶來本質上的變化。
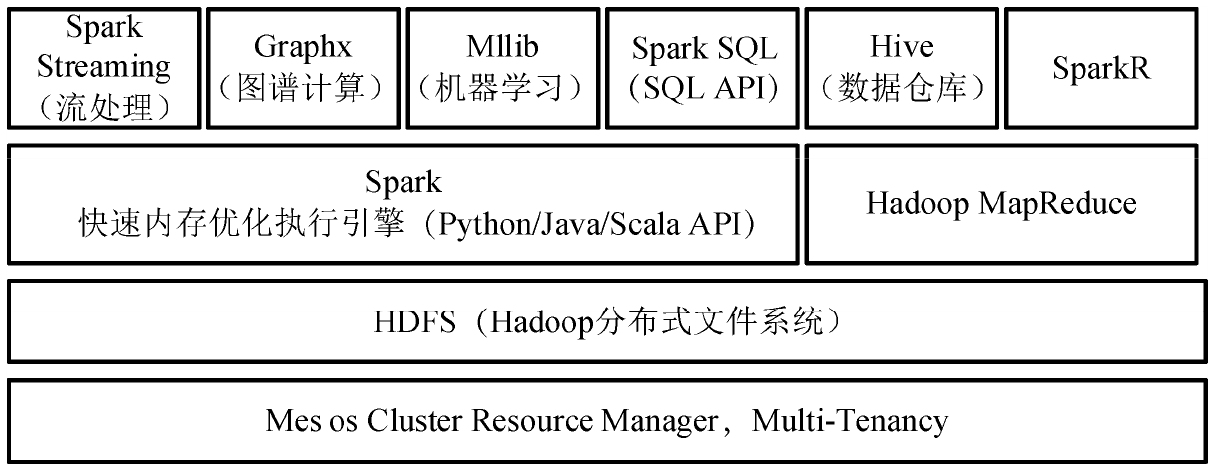
圖3-11 Spark生態圈
對Hadoop而言,其并行計算框架MapReduce可以由Spark進行補充,同時可以融合分布式存儲系統HDFS與數據倉庫Hive等分層存儲介質,在加入Hadoop體系后,Spark在計算消耗和拓展性方面會得到較大的提升。與Hadoop相比較,Spark在內存布局、執行策略和中間結果輸出、數據格式和任務調度的開銷方面有明顯的優勢。
1)Spark工作機
Spark工作機的集群運行框架如圖3-12所示。Driver程序就是用戶直接進行的操作程序,每個Driver程序需要與集群中的Spark Content對象進行匹配,從Driver程序開始,借助集群管理器,調用工作節點執行分布式彈性數據集(Resilient Distributed Dataset,RDD)操作。分配系統資源主要由Spark Content進行控制,將獲取到的用戶任務進行分配。每一個工作節點對應著一個用戶任務,是任務的主要完成者,在得到任務時先創建相應的Task執行器,并將任務的執行過程反饋給集群管理器。在集群管理器中完成后續的計算資源合理劃分及綜合管控,實現并行式分布計算。
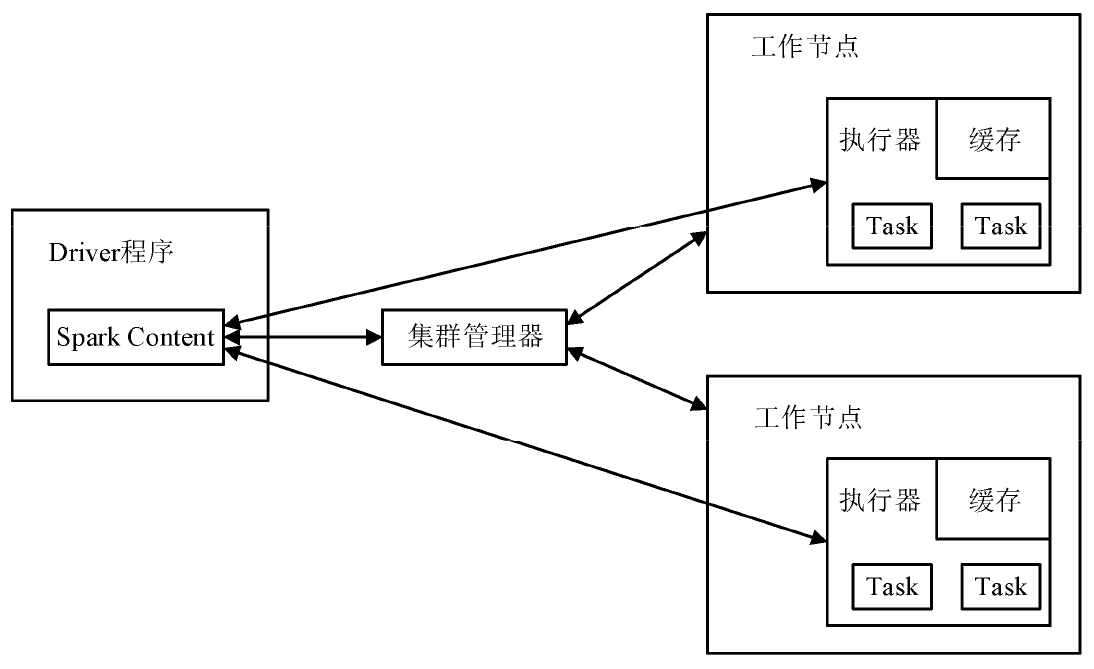
圖3-12 Spark工作機的集群運行框架
MapReduce模型是Hadoop并行化的計算核心,而Spark在并行化中的計算核心是RDD,RDD是Spark計算框架下各類計算的基礎。Spark集群調用RDD進行迭代計算的過程,主要是在各個分區中將相應的RDD通過計算進行轉化。RDD計算模型如圖3-13所示。RDD有著和HDFS相似的對數據集的劃分,也就意味著RDD中也有不同的區。其數據分區是計算過程中的主體與最小計算單元,拆分得到的區的數量與Spark集群的應用程度有著密切的聯系。
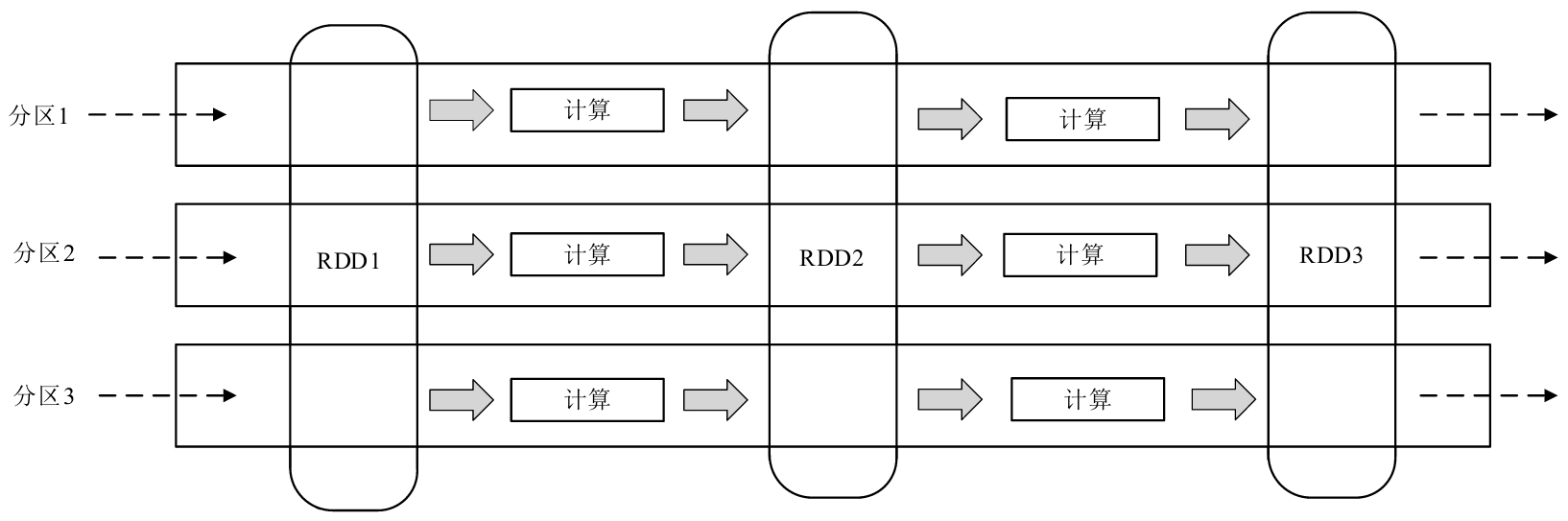
圖3-13 RDD計算模型
2)Spark Streaming數據流處理
Spark Streaming是Spark核心接口的一個對外應用,其特性是傳輸數據規模大、抗干擾能力強,同時也是一個實時數據流處理系統。Spark Streaming數據流處理模式如圖3-14所示。Spark Streaming支持Kafka、Flume、HDFS/S3及Twitter等數據源,獲取數據后可以使用Map、Reduce和Windows等高級函數進行復雜算法的處理,可以在文件系統、數據庫等存儲介質儲存處理結果。
Spark Streaming可以將傳輸進來的數據流進行拆分,將得到的數據段分別進行處理,拆分的主要依據是時間窗口和滑動窗口的值。利用Spark Streaming對數據流進行分段處理如圖3-15所示。

圖3-14 Spark Streaming數據流處理模式
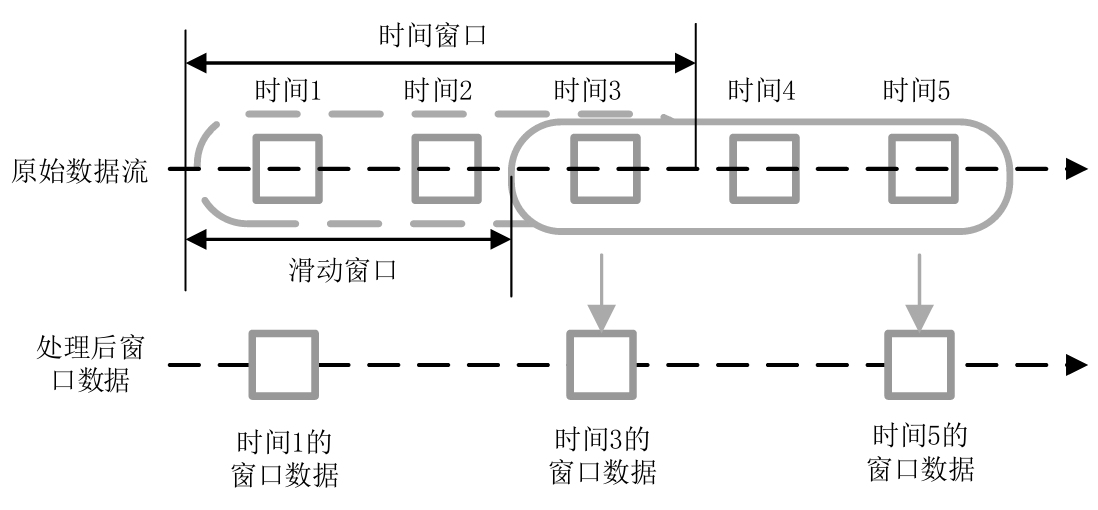
圖3-15 利用Spark Streaming對數據流進行分段處理
3)Spark SQL
Spark SQL是一款利用Spark集群進行結構化數據操作的控件。該控件兼容了HiveQL,甚至可以通過JDBC與ODBC接口來連接Spark SQL。Spark SQL的具體架構如圖3-16所示。基于Spark SQL使用Hive本身提供的元數據倉庫(MetaStore)、用戶自定義函數(UDF)、HiveQL及序列化和反序列化工具(SerDes),使得不同數據之間的融合性、運算性能及架構延展性得以提升,這是其他結構化數據操作工具所不具備的優勢。
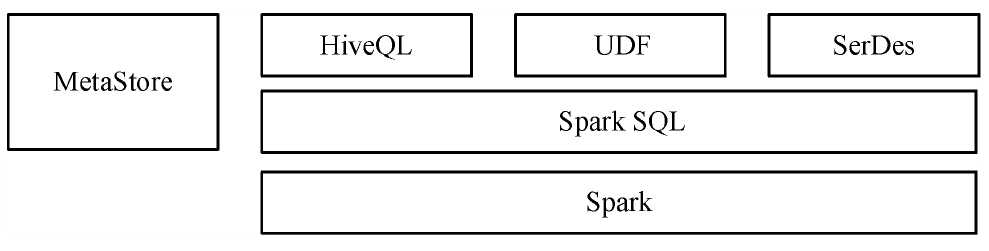
圖3-16 Spark SQL的具體架構
4)Spark MLlib
MLib是Spark機器學習庫,使機器學習的可理解性和可伸縮性更好。其中提供了大量常用機器學習算法,包括分類、聚類、回歸和降維等,在Spark集群中使用MLlib非常便捷,只需直接調用相應的API使用即可。Spark MLlib算法分類如表3-1所示。
表3-1 Spark MLlib算法分類

3.4.2 制造車間大數據處理系統
3.4.2.1 系統總體設計
可以將制造車間大數據處理系統劃分為批處理層、速度層與服務層三層架構,針對各個架構分別進行開發實現。制造車間大數據處理系統開發原理圖如圖3-17所示。速度層包含的流式處理系統可以進行在線計算得到流式計算結果,而批處理層中的全量數據存儲平臺可以進行重復計算得到批量計算結果,這兩個層是可以同時并發進行計算任務的,這樣會縮短制造車間任務數據的處理和分析時間。服務層中的制造數據傳輸系統將獲取到的底層制造車間的制造加工數據傳輸到制造車間大數據處理系統之中。然后系統會將數據分配到批處理層和速度層分別進行批量計算和流式計算,得到的計算結果會傳回到服務層分別以批處理視圖和流處理視圖的形式進行呈現。最后將兩者進行數據融合,由統一接口向外界系統進行傳輸和展現,如制造大數據實時可視化系統等其他系統。
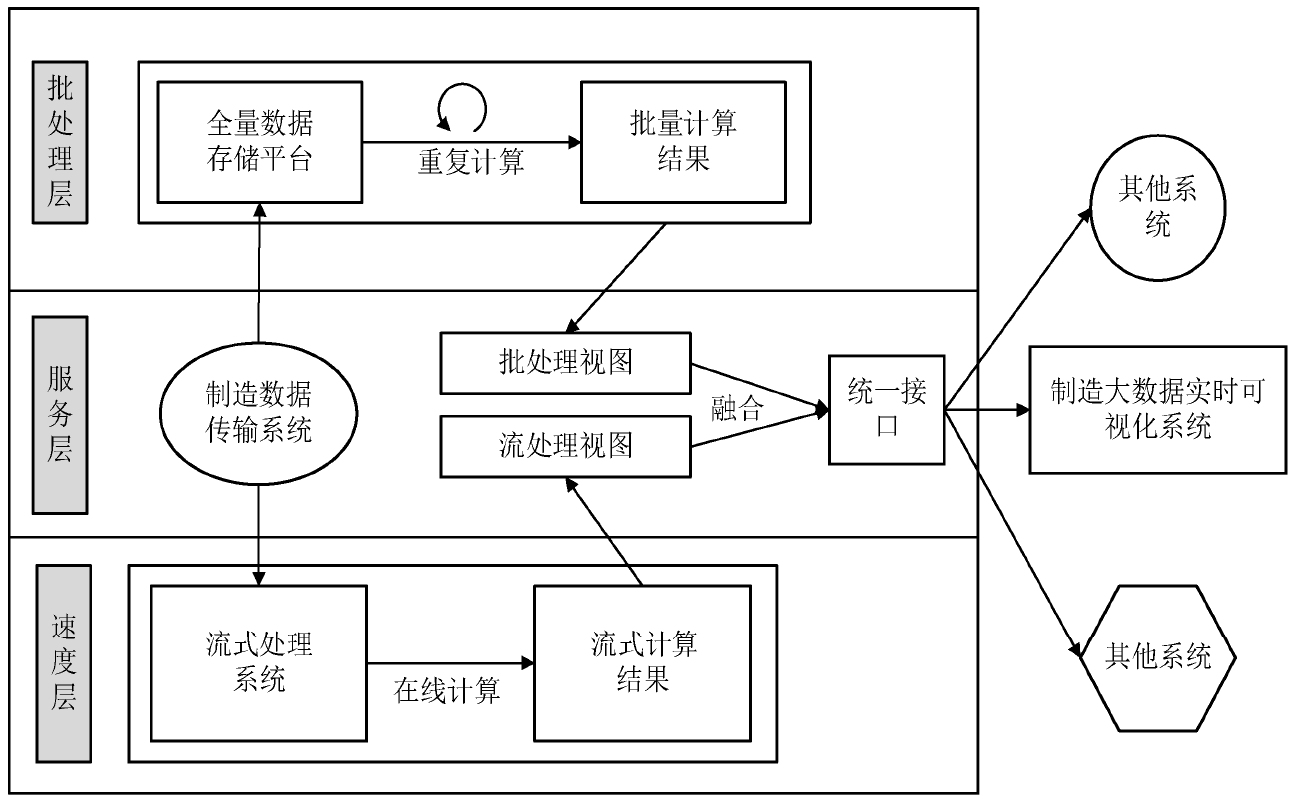
圖3-17 制造車間大數據處理系統開發原理圖
3.4.2.2 速度層的設計
速度層的主要任務是完成流式計算,因此處于該層的組件應具備基于時間窗口的數據處理功能。Apache Spark(簡稱Spark)中的Spark Streaming模塊正是為此開發的。此層是在Spark Streaming的Structred Streaming(結構化流)接口的基礎上進行開發的。以設備報警數統計為例,其速度層實現原理圖如圖3-18所示,計算不間斷進行,并以5秒的時間窗口為單位執行一次算法。算法以每臺設備的身份ID值作為數據流所對應的鍵值將設備報警數記錄下來,同時實時計算輸入的數據流并輸出結果。數據流的讀取使用Spark Streaming的readStream()函數,該函數返回不間斷數據流,隨后在該數據流上初始化window對象,對象中包含時間窗口的長度、滑動窗口的大小等必要參數,最后對流調用star()方法開始執行。
3.4.2.3 批處理層的設計
相對于速度層的設計,批處理層的實現難度更大,主要原因是需要在批處理任務開始之前,將底層制造車間傳輸的制造加工數據處理成數據塊寫入不同的數據節點上。Apache Hadoop(簡稱Hadoop)目前應用場景十分的普遍,它能夠同時提供滿足要求的大數據文件存儲系統HDFS與分布式計算資源調度器YARN(對于Hadoop 1則是MapReduce框架),因此使用Hadoop作為批處理層的主要組件。批處理層實現原理圖如圖3-19所示。
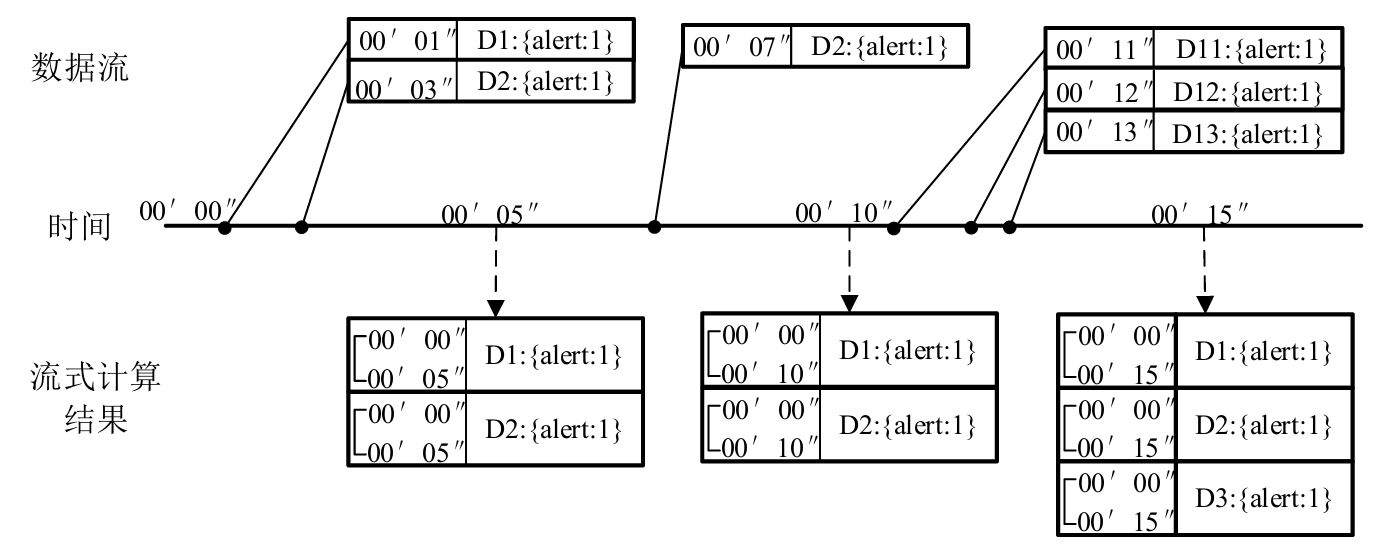
圖3-18 設備報警數統計的速度層實現原理圖
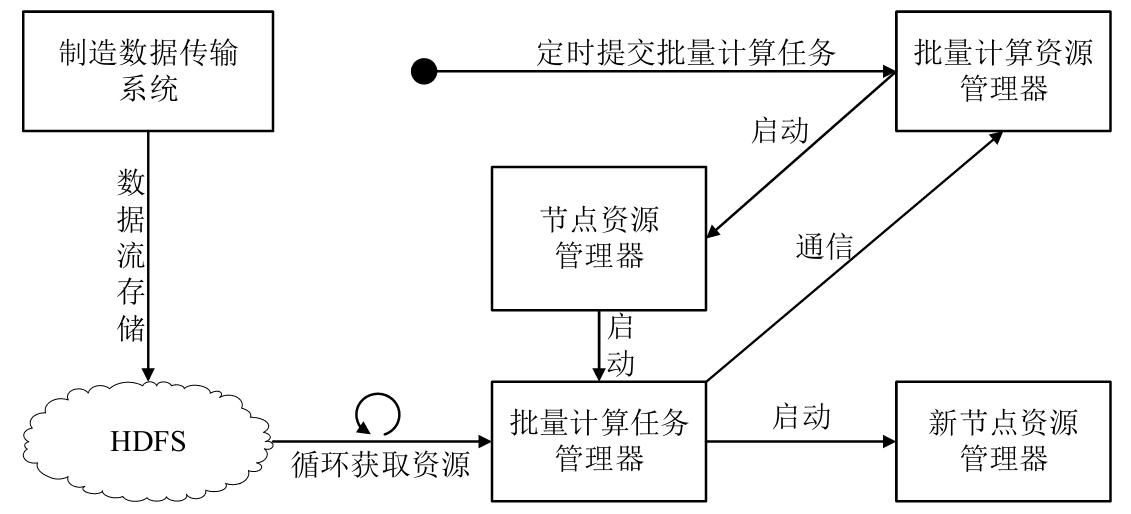
圖3-19 批處理層實現原理圖
由圖可以看出,制造數據傳輸系統將獲取到的制造加工數據傳輸到HDFS。此時,由于將要進行的批量計算會占用大量的算力資源,所以在進行批量計算之前,需要評估將要占用的算力資源,然后批量計算任務管理器循環獲取資源,而批量計算任務管理器將會向批量計算資源管理器發送消息,從而啟動新節點資源管理器,分配出足夠的算力資源供給將要進行的批量計算任務。
3.4.2.4 服務層的設計
服務層是所設計的系統與外界交互的主要平臺,也是向外界提供制造車間大數據處理系統服務的窗口,采用Apache HBase(簡稱HBase)來實現。HBase是一款基于列族的NoSQL數據庫,具有在隨機性讀取的情況下還能夠保持高性能運行的特點,同時面對數據量的動態變化可以自主地進行空間劃分的操作,從而保證較高的調用獲取性能,極為適合作為所設計系統服務層的應用組件。HBase表的列族內容主要是基于數據點計算指標進行設計的,設計的同時需要考慮內容的組成部分,一般是批量計算和流式計算的結果。每次的計算結果都由一條單獨的記錄進行存儲,當在前述兩種計算模式下仍然有一部分的任務結果還沒有完成,那么本次的記錄會將上一次的計算結果作為內容進行存儲。在考慮讀取調用效率和系統中模式共存性的基礎上進行表格的設計,這樣的設計策略也是符合制造大數據處理系統要求的。