- 量子機器學習及區塊鏈技術導論
- 楊毅等編著
- 882字
- 2022-05-05 20:15:11
2.2.2 決策樹算法
決策樹也是一種常見的機器學習方法,該方法先劃分數據再進行對比,以盡快結束判斷的過程。仍然以上述的電影數據為例:首先計算以不同方式劃分的數據,得到不同的信息增益;再以熵(Entropy)為單位進行對比。在信息論中,熵是每個研究對象中包含的信息平均量,是衡量信息量的指標之一。
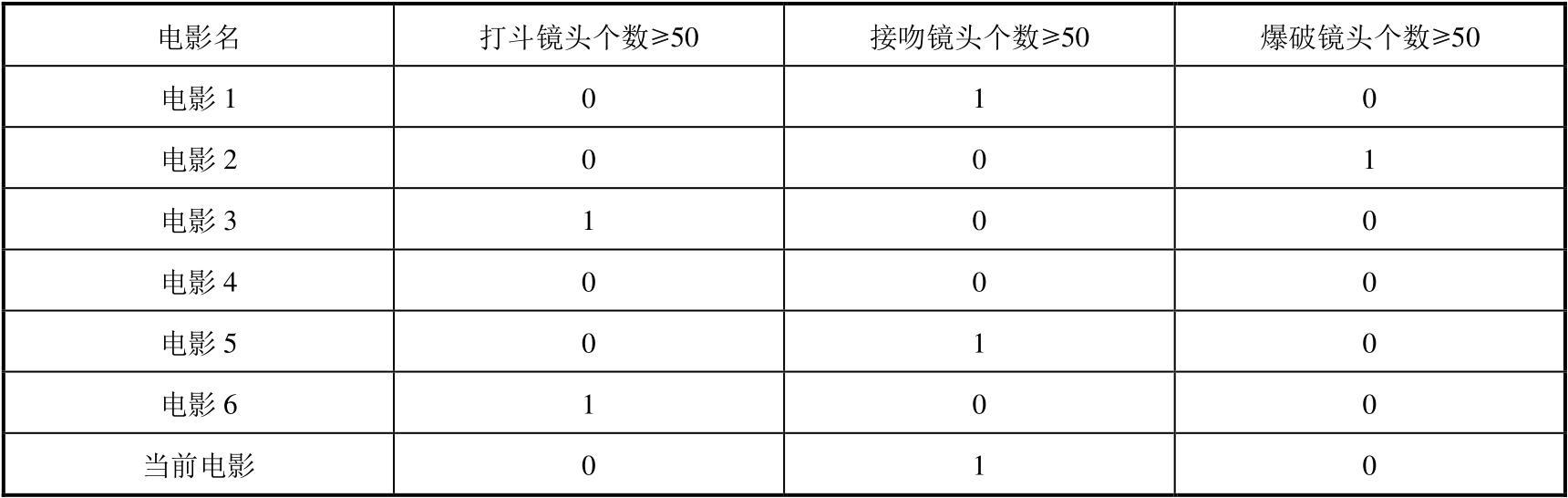
按某類鏡頭個數是否大于或等于50來劃分數據所獲得的信息如表2.2所示。
表2.2 按某類鏡頭是否大于或等于50來劃分數據所獲得的信息
決策樹算法的步驟如下:
(1)計算全體數據集的熵。全體數據集的熵計算公式為:
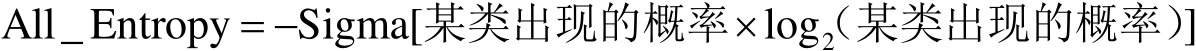
式中,Sigma表示對括號內的內容求和。
在本例中,一共有4類電影,每類出現的概率分別是2/6、1/6、2/6和1/6,全體數據集的熵為:
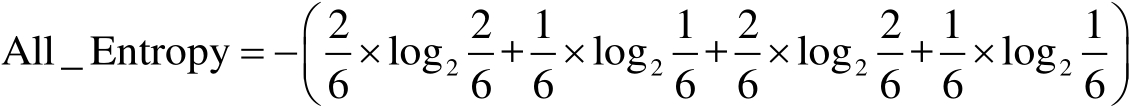
(2)指定分類方式,劃分數據集。按照打斗鏡頭個數≥50、接吻鏡頭≥50和爆破鏡頭個數≥50的界限,劃分數據集。以打斗鏡頭為例,其中正例(打斗鏡頭個數≥50的電影)共計2個、負例(打斗鏡頭個數<50的電影)共計4個,得到打斗鏡頭的熵為:
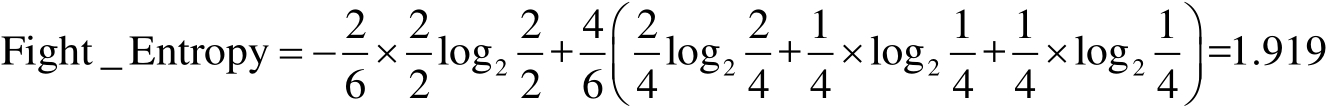
按照同樣的方法,可得到接吻鏡頭的熵和爆破鏡頭的熵分別為1.919和1.216。
(3)計算信息增益。用3種方式劃分數據集得到的熵減去總熵,差值越大越好。可知用打斗鏡頭個數≥50的熵為1.919-1=0.919,接吻鏡頭個數≥50的熵也是0.919),都好于爆破鏡頭個數≥50的熵。
(4)構建決策樹。分別根據打斗鏡頭個數、接吻鏡頭個數和爆破鏡頭個數對6部老電影進行3次劃分,得到的決策樹如圖2.3所示。
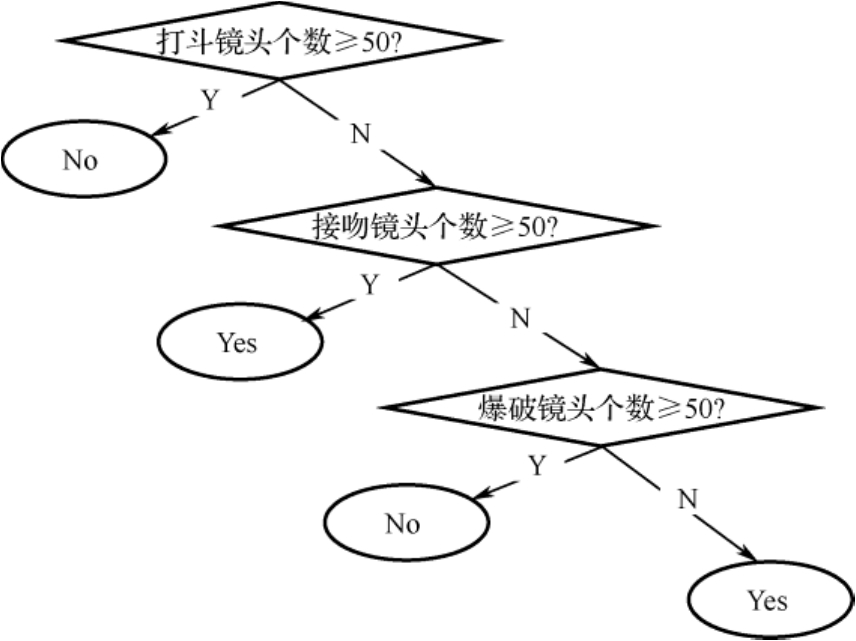
圖2.3 決策樹
(5)裁剪決策樹。如果決策樹上的節點只能增加少許信息,則可以與其他節點合并或者刪除該節點。例如,在圖2.3中,爆破鏡頭個數≥50的節點并未被觸發過,因此可以刪除該節點。
(6)測試效果。構建好決策樹后,用新電影的信息測試決策樹:新電影的打斗鏡頭個數為8,繼續判斷一次,接吻鏡頭個數為92,直接判斷為愛情片,正確率為100%。
決策樹算法旨在以最快的速度、正確地結束判斷過程。與K近鄰算法的不同之處在于,決策樹算法的已知特征都是以0和1的形式存在的,也就是說,對于三種鏡頭,需要按照其個數大于或等于50,以及小于50來進行劃分,個數大于或等于50就是1,個數小于50就是0。決策樹算法的缺點是難以準確預測連續性的字段,需要對數據進行很多預處理。