- Apache Karaf Cookbook
- Achim Nierbeck Jamie Goodyear Johan Edstrom Heath Kesler
- 696字
- 2021-09-03 09:55:08
Setting up Apache Karaf for high availability
To help provide higher service availability, Karaf provides the option to set up a secondary instance of Apache Karaf to failover upon in case of an operating environment error. In this recipe, we'll configure a Master/Slave failover deployment and briefly discuss how you can expand the recipe to multiple hosts.
Getting ready
The ingredients of this recipe include the Apache Karaf distribution kit, access to JDK, and a source code editor. The sample configuration for this recipe is available at https://github.com/jgoodyear/ApacheKarafCookbook/tree/master/chapter1/chapter1-recipe8.
How to do it…
- The first step is editing the system properties file. To enable a Master/Slave failover, we edit the
etc/system.propertiesfile of two or more Karaf instances to include the following Karaf locking configuration:## ## Sample lock configuration ## karaf.lock=true karaf.lock.class=org.apache.karaf.main.lock.SimpleFileLock # specify path to lock directory karaf.lock.dir=[PathToLockFileDirectory] karaf.lock.delay=10
The previous configuration sample contains the essential entries for a file-based locking mechanism, that is, two or more Karaf instances attempt to gain exclusive ownership of a file over a shared filesystem.
- The next step is providing locking resources. If using a shared locking file approach is suitable to your deployment, then all you must do at this time is mount the filesystem on each machine that'll host Karaf instances in the Master/Slave deployment.
Tip
If you plan to use the shared file lock, consider using an NFSv4 filesystem, as it implements flock correctly.
Each Karaf instance will include the same lock directory location on a shared filesystem common to each Karaf installation. If a shared filesystem is not practical between systems, then a JDBC locking mechanism can be used. This is described in the following code:
karaf.lock=true karaf.lock.class=org.apache.karaf.main.DefaultJDBCLock karaf.lock.delay=10 karaf.lock.jdbc.url=jdbc:derby://dbserver:1527/sample karaf.lock.jdbc.driver=org.apache.derby.jdbc.ClientDriver karaf.lock.jdbc.user=user karaf.lock.jdbc.password=password karaf.lock.jdbc.table=KARAF_LOCK karaf.lock.jdbc.clustername=karaf karaf.lock.jdbc.timeout=30
The JDBC configuration is similar to the SimpleFileLock configuration. However, it is expanded to contain the JDBC
url,driver,timeout,user, andpasswordoptions. Two additional JDBC options are included to allow for multiple Master/Slave Karaf deployments to use a single database. These are the JDBCtableandclusternameoptions. The JDBCtableproperty sets the database table to use for the lock, and the JDBCclusternameproperty specifies which pairing group a Karaf instance belongs to (for example, hosts A and B belong to a cluster prod group, and hosts C and D belong to a cluster dev group).When using the JDBC locking mechanism, you'll have to provide the relevant JDBC driver JAR file to Karaf's
lib/extfolder. For specific database configurations, consult Karaf's user manual (http://karaf.apache.org/manual/latest/index.html). - The final step is verifying the lock behavior. Once you have configured each Karaf instance to be a participant of the Master/Slave deployment and ensured that any locking resources have been made available (mounted filesystems or database drivers/connectivity), you must now validate that it is all working as desired. The general test to perform is to start one instance of Karaf, allow it to gain the lock (you'll see this recorded in the logfile), and then start all additional instances. Only the first instance should be fully booted; the others should be trying to gain the lock. Stopping this first instance should result in another instance becoming the Master. This verification step is vital. Most Master/Slave deployment failures occur due to misconfigurations or shared resource permissions.
How it works…
Each instance of Apache Karaf contains a copy of the locking configuration in its etc/system.properties file. This is described in the following figure:
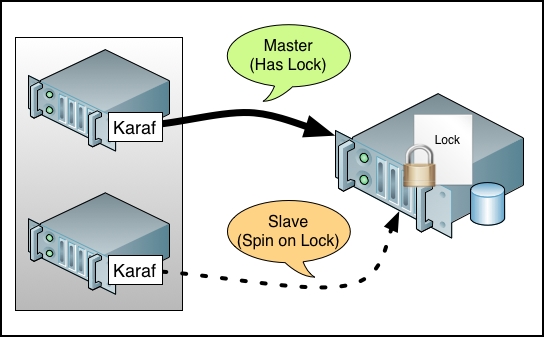
In the case of a SimpleFileLock configuration, Karaf attempts to utilize an exclusive lock upon a file to manage which Karaf instance will operate as a live (Master) container. The other instances in the set will try gaining lock file access for karaf.lock.delay seconds each. This can be easily simulated on a single host machine with two Karaf installations both configured to use the same locking file. If the lock file is located on a shared NFSv4 filesystem, then multiple servers may be able to use this configuration. However, a JDBC-based lock is the most often used in multihost architectures.
There's more…
Karaf failover describes an active/passive approach to high availability. There is also a similar concept that provides active/active architecture via Apache Karaf Cellar.
- Python快樂編程:人工智能深度學(xué)習(xí)基礎(chǔ)
- Mastering Zabbix(Second Edition)
- Kubernetes實(shí)戰(zhàn)
- 造個小程序:與微信一起干件正經(jīng)事兒
- 控糖控脂健康餐
- JavaScript Unlocked
- Python 3網(wǎng)絡(luò)爬蟲實(shí)戰(zhàn)
- Kotlin Standard Library Cookbook
- ArcGIS By Example
- JavaScript 程序設(shè)計案例教程
- Microsoft Azure Storage Essentials
- Java零基礎(chǔ)實(shí)戰(zhàn)
- 實(shí)驗(yàn)編程:PsychoPy從入門到精通
- C Primer Plus(第6版)中文版【最新修訂版】
- Java Web動態(tài)網(wǎng)站開發(fā)(第2版·微課版)