- R High Performance Programming
- Aloysius Lim William Tjhi
- 560字
- 2021-08-06 19:17:05
Three constraints on computing performance – CPU, RAM, and disk I/O
First, let's see how R programs are executed in a computer. This is a very simplified version of what actually happens, but it suffices for us to understand the performance limitations of R. The following figure illustrates the steps required to execute an R program.
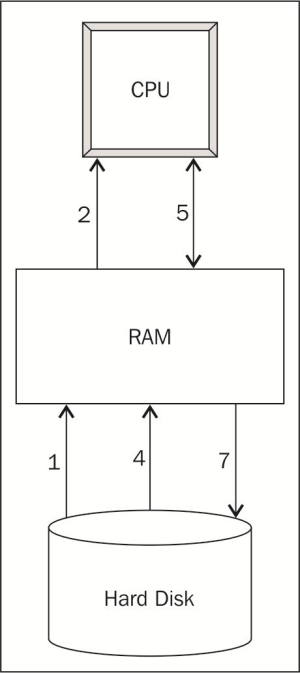
Steps to execute an R program
Take for example, this simple R program, which loads some data from a CSV file, computes the column sums, and writes the results into another CSV file:
data <- read.csv("mydata.csv")
totals <- colSums(data)
write.csv(totals, "totals.csv")
We use the numbering to understand the preceding diagram:
- When we load and run an R program, the R code is first loaded into RAM.
- The R interpreter then translates the R code into machine code and loads the machine code into the CPU.
- The CPU executes the program.
- The program loads the data to be processed from the hard disk into RAM (
read.csv()in the example). - The data is loaded in small chunks into the CPU for processing.
- The CPU processes the data one chunk at a time, and exchanges chunks of data with RAM until all the data has been processed (in the example, the CPU executes the instructions of the
colSums()function to compute the column sums on the data set). - Sometimes, the processed data is stored back onto the hard drive (
write.csv()in the example).
From this depiction of the computing process, we can see a few places where performance bottlenecks can occur:
- The speed and performance of the CPU determines how quickly computing instructions, such as
colSums()in the example, are executed. This includes the interpretation of the R code into the machine code and the actual execution of the machine code to process the data. - The size of RAM available on the computer limits the amount of data that can be processed at any given time. In this example, if the
mydata.csvfile contains more data than can be held in the RAM, the call toread.csv()will fail. - The speed at which the data can be read from or written to the hard disk (
read.csv()andwrite.csv()in the example), that is, the speed of the disk input/output (I/O) affects how quickly the data can be loaded into the memory and stored back onto the hard disk.
Sometimes, you might encounter these limiting factors one at a time. For example, when a dataset is small enough to be quickly read from the disk and fully stored in the RAM, but the computations performed on it are complex, then only the CPU constraint is encountered. At other times, you might find them occurring together in various combinations. For example, when a dataset is very large, it takes a long time to load it from the disk, only one small chunk of it can be loaded at any given time into the memory, and it takes a long time to perform any computations on it. In either case, these are the symptoms of performance problems. In order to diagnose the problems and find solutions for them, we need to look at what is happening behind the scenes that might be causing these constraints to occur.
Let's now take a look at how R is designed and how it works, and see what the implications are for its performance.
- ASP.NET Core:Cloud-ready,Enterprise Web Application Development
- Unreal Engine Physics Essentials
- Spring Cloud Alibaba微服務(wù)架構(gòu)設(shè)計(jì)與開(kāi)發(fā)實(shí)戰(zhàn)
- Visual Basic 6.0程序設(shè)計(jì)計(jì)算機(jī)組裝與維修
- Mastering OpenCV Android Application Programming
- Django開(kāi)發(fā)從入門(mén)到實(shí)踐
- 營(yíng)銷(xiāo)數(shù)據(jù)科學(xué):用R和Python進(jìn)行預(yù)測(cè)分析的建模技術(shù)
- Building Mobile Applications Using Kendo UI Mobile and ASP.NET Web API
- 軟件架構(gòu):Python語(yǔ)言實(shí)現(xiàn)
- Getting Started with React Native
- Developing SSRS Reports for Dynamics AX
- Kubernetes進(jìn)階實(shí)戰(zhàn)
- C語(yǔ)言程序設(shè)計(jì)與應(yīng)用(第2版)
- Maker基地嘉年華:玩轉(zhuǎn)樂(lè)動(dòng)魔盒學(xué)Scratch
- 計(jì)算機(jī)應(yīng)用基礎(chǔ)(第二版)