- Hadoop 2.x Administration Cookbook
- Gurmukh Singh
- 247字
- 2021-07-09 20:10:28
HDFS balancer
In a long-running cluster, there might be unequal distribution of data across Datanodes. This could be due to failures of nodes or the addition of nodes to the cluster.
To make sure that the data is equally distributed across Datanodes, it is important to use Hadoop balancer to redistribute the blocks.
Getting ready
For this recipe, you will again use the same node on which we have already configured Namenode.
All operations will be done by user hadoop.
How to do it...
- Log in the nn1.cluster1.com node and change to user
hadoop. - Execute the balancer command as shown in the following screenshot:
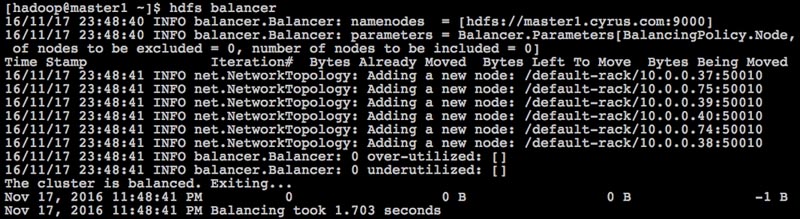
- By default, the balancer threshold is set to 10%, but we can change it, as shown in the following screenshot:
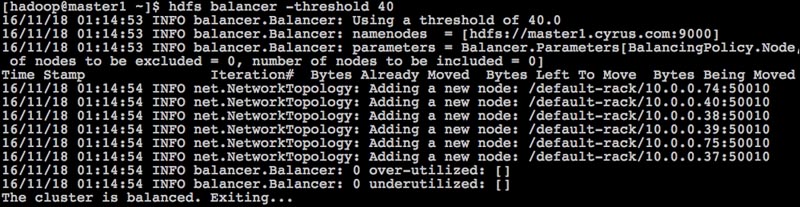
How it works...
The balancer threshold defines the percentage of cluster disk space utilized, compared to the nodes in the cluster. For example, let's say we have 10 Datanodes in the cluster, with each having 100 GB of disk storage totaling to about 1 TB.
So, when we say the threshold is 5%, it means that if any Datanode's disk in the cluster is utilized for more than 50 GB (5% of total cluster capacity), the balancer will try to balance the node by moving the blocks to other nodes. It is not always possible to balance the cluster, especially when the cluster is running near maximum disk utilization.