- Python Web Scraping Cookbook
- Michael Heydt
- 195字
- 2021-06-30 18:44:06
How to do it
We won't parse the data in the planets.html file, but simply retrieve it from the local web server using requests:
- The following code, (found in 03/S3.py), reads the planets web page and stores it in S3:
import requests
import boto3
data = requests.get("http://localhost:8080/planets.html").text
# create S3 client, use environment variables for keys
s3 = boto3.client('s3')
# the bucket
bucket_name = "planets-content"
# create bucket, set
s3.create_bucket(Bucket=bucket_name, ACL='public-read')
s3.put_object(Bucket=bucket_name, Key='planet.html',
Body=data, ACL="public-read")
- This app will give you output similar to the following, which is S3 info telling you various facts about the new item.
{'ETag': '"3ada9dcd8933470221936534abbf7f3e"', 'ResponseMetadata': {'HTTPHeaders': {'content-length': '0', 'date': 'Sun, 27 Aug 2017 19:25:54 GMT', 'etag': '"3ada9dcd8933470221936534abbf7f3e"', 'server': 'AmazonS3', 'x-amz-id-2': '57BkfScql637op1dIXqJ7TeTmMyjVPk07cAMNVqE7C8jKsb7nRO+0GSbkkLWUBWh81k+q2nMQnE=', 'x-amz-request-id': 'D8446EDC6CBA4416'}, 'HTTPStatusCode': 200, 'HostId': '57BkfScql637op1dIXqJ7TeTmMyjVPk07cAMNVqE7C8jKsb7nRO+0GSbkkLWUBWh81k+q2nMQnE=', 'RequestId': 'D8446EDC6CBA4416', 'RetryAttempts': 0}}
- This output shows us that the object was successfully created in the bucket. At this point, you can navigate to the S3 console and see your bucket:
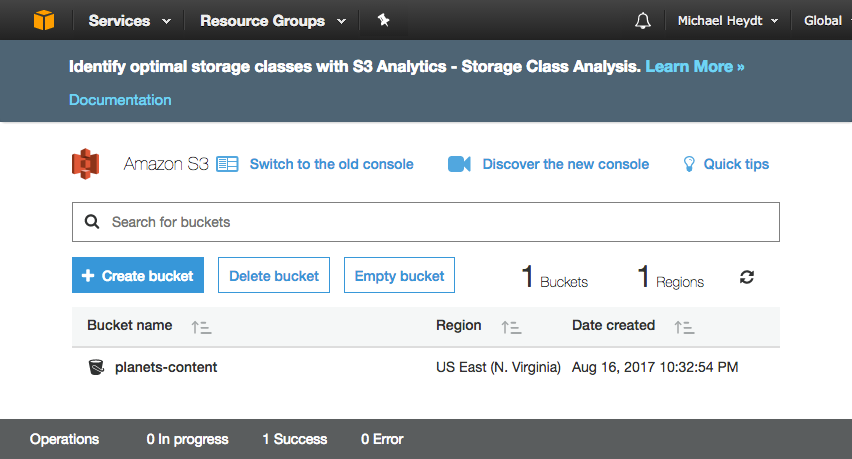
The Bucket in S3
- Inside the bucket you will see the planet.html file:
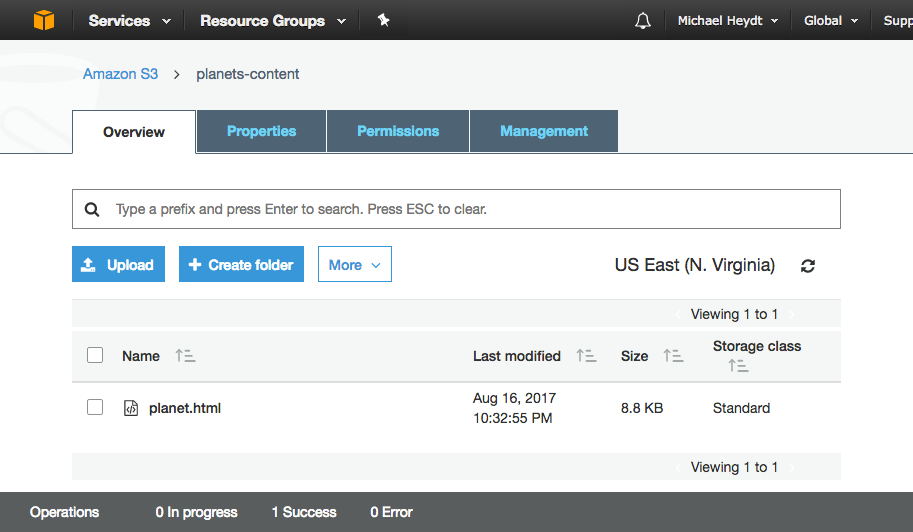
The File in the Bucket
- By clicking on the file you can see the property and URL to the file within S3:
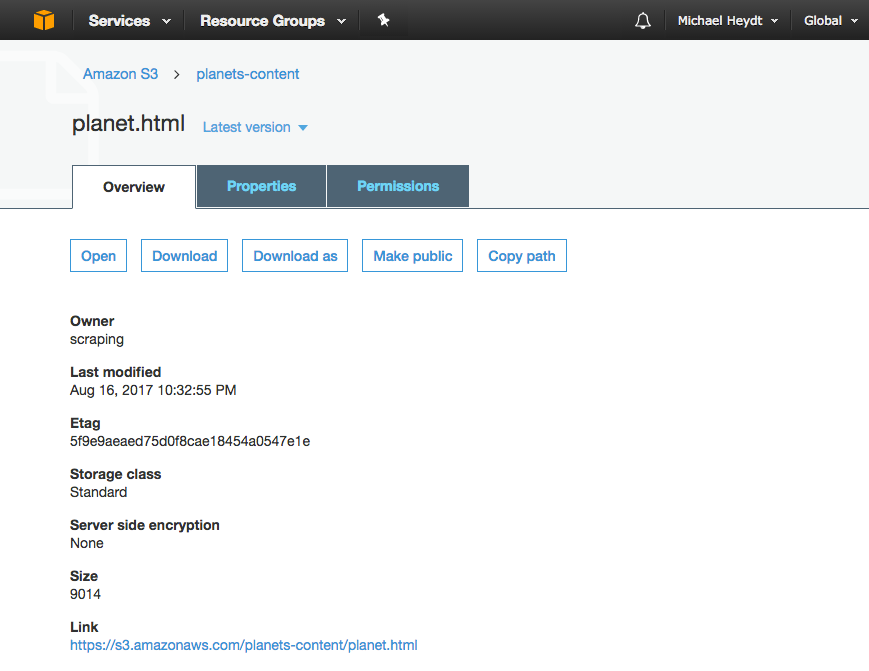
The Properties of the File in S3
推薦閱讀
- 物聯(lián)網(wǎng)工程規(guī)劃技術(shù)
- GPS/GNSS原理與應(yīng)用(第3版)
- Web Application Development with R Using Shiny
- 無人機(jī)通信
- C/C++串口通信:典型應(yīng)用實(shí)例編程實(shí)踐
- 6G新技術(shù) 新網(wǎng)絡(luò) 新通信
- Working with Legacy Systems
- 光纖通信系統(tǒng)與網(wǎng)絡(luò)(修訂版)
- 物聯(lián)網(wǎng)與智能家居
- 物聯(lián)網(wǎng)工程概論
- Implementing NetScaler VPX?
- 移動(dòng)物聯(lián)網(wǎng):商業(yè)模式+案例分析+應(yīng)用實(shí)戰(zhàn)
- 一本書讀懂TCP/IP
- Guide to NoSQL with Azure Cosmos DB
- 數(shù)字王國(guó)里的虛擬人:技術(shù)、商業(yè)與法律解讀