- Intelligent Projects Using Python
- Santanu Pattanayak
- 415字
- 2021-07-02 14:10:48
Formulating the loss function
The data for this use case has five classes, pertaining to no diabetic retinopathy, mild diabetic retinopathy, moderate diabetic retinopathy, severe diabetic retinopathy, and proliferative diabetic retinopathy. Hence, we can treat this as a categorical classification problem. For our categorical classification problem, the output labels need to be one-hot encoded, as shown here:
- No diabetic retinopathy: [1 0 0 0 0]T
- Mild diabetic retinopathy: [0 1 0 0 0]T
- Moderate diabetic retinopathy: [0 0 1 0 0]T
- Severe diabetic retinopathy: [0 0 0 1 0]T
- Proliferative diabetic retinopathy: [0 0 0 0 1]T
Softmax would be the best activation function for presenting the probability of the different classes in the output layer, while the sum of the categorical cross-entropy loss of each of the data points would be the best loss to optimize. For a single data point with the output label vector y and the predicted probability of p, the cross-entropy loss is given by the following equation:
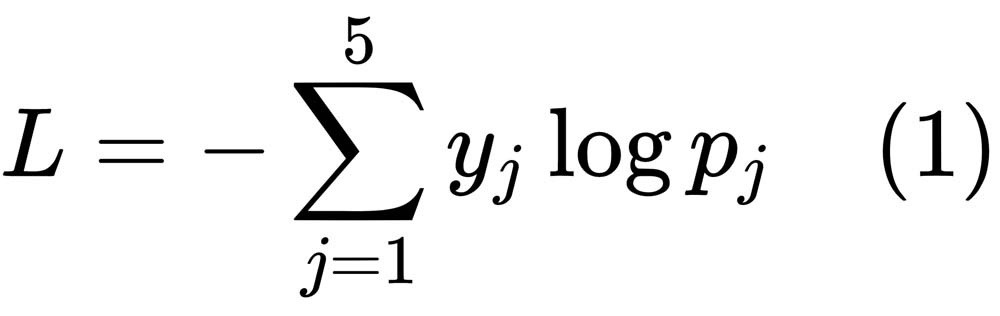
Here, 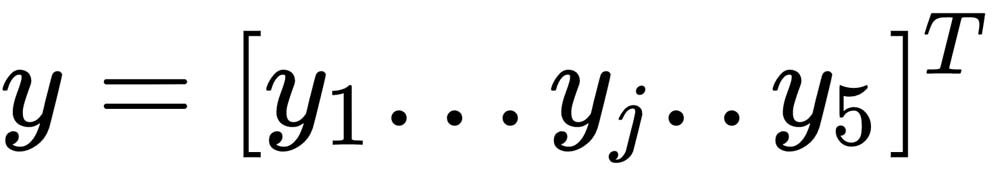 and
and 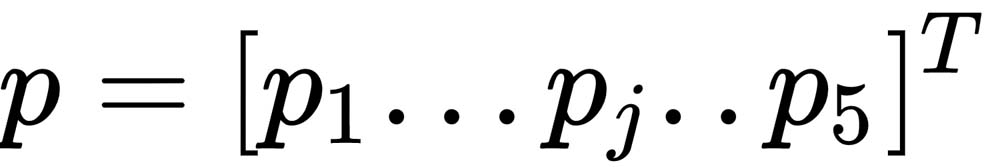 .
.
Similarly, the average loss over M training data points can be represented as follows:
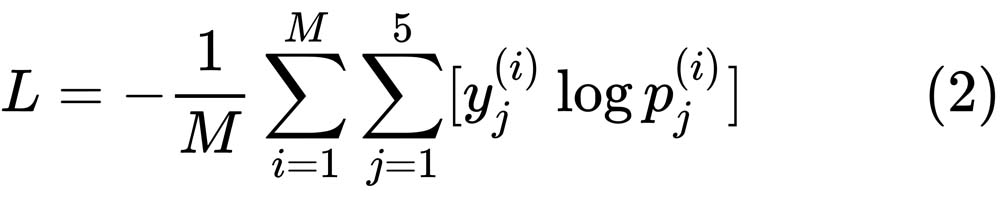
During the training process, the gradients of a mini batch are based on the average log loss given by (2), where M is the chosen batch size. For the validation log loss that we will monitor in conjunction with the validation accuracy, M is the number of validation set data points. Since we will be doing K-fold cross-validation in each fold, we will have a different validation dataset in each fold.
Now that we have defined the training methodology, the loss function, and the validation metric, let's proceed to the data exploration and modeling.
Note that the classifications in the output classes are of an ordinal nature, since the severity increases from class to class. For this reason, regression might come in handy. We will try our luck with regression in place of categorical classification, as well, to see how it fares. One of the challenges with regression is to convert the raw scores to classes. We would use a simple scheme and hash the scores to its nearest integer severity class.