- Intelligent Projects Using Python
- Santanu Pattanayak
- 468字
- 2021-07-02 14:10:47
Introduction to transfer learning
In a traditional machine learning paradigm (see Figure 2.1), every use case or task is modeled independently, based on the data at hand. In transfer learning, we use the knowledge gained from a particular task (in the form of architecture and model parameters) to solve a different (but related) task, as illustrated in the following diagram:
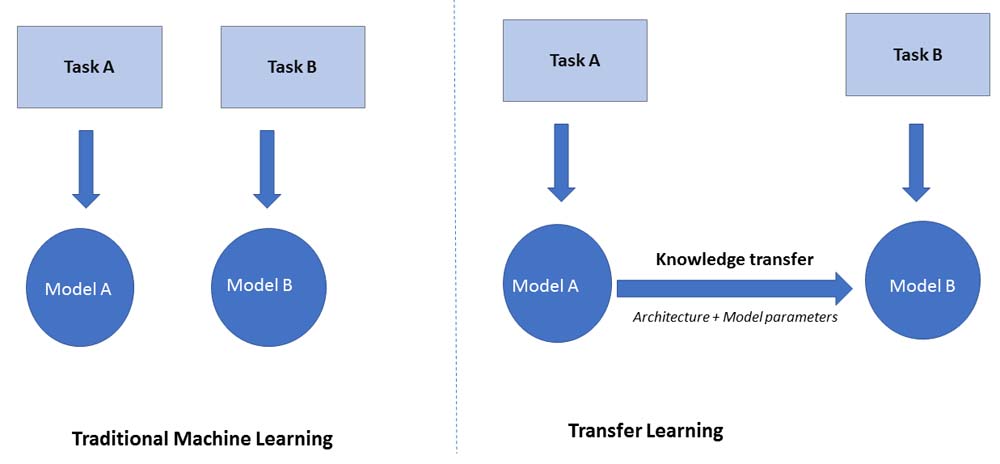
Andrew Ng, in his 2016 NIPS tutorial, stated that transfer learning would be the next big driver of machine learning's commercial success (after supervised learning); this statement grows truer with each passing day. Transfer learning is now used extensively in problems that need to be solved with artificial neural networks. The big question, therefore, is why this is the case.
Training an artificial neural network from scratch is a difficult task, primarily due to the following two reasons:
- The cost surface of an artificial neural network is non-convex; hence, it requires a good set of initial weights for a reasonable convergence.
- Artificial neural networks have a lot of parameters, and thus, they require a lot of data to train. Unfortunately, for a lot of projects, the specific data available for training a neural network is insufficient, whereas the problem that the project aims to solve is complex enough to require a neural network solution.
In both cases, transfer learning comes to the rescue. If we use pre-trained models that are trained on a huge corpora of labeled data, such as ImageNet or CIFAR, problems involving transfer learning will have a good set of initial weights to start the training; those weights can then be fine-tuned, based on the data at hand. Similarly, to avoid training a complex model on a smaller amount of data, we may want to extract the complex features from a pre-trained neural network, and then use those features to train a relatively simple model, such as an SVM or a logistic regression model. To provide an example, if we are working on an image classification problem and we already have a pre-trained model—say, a VGG16 network on 1,000 classes of ImageNet—we can pass the training data through the weights of VGG16 and extract the features from the last pooling layer. If we have m training data points, we can use the equation 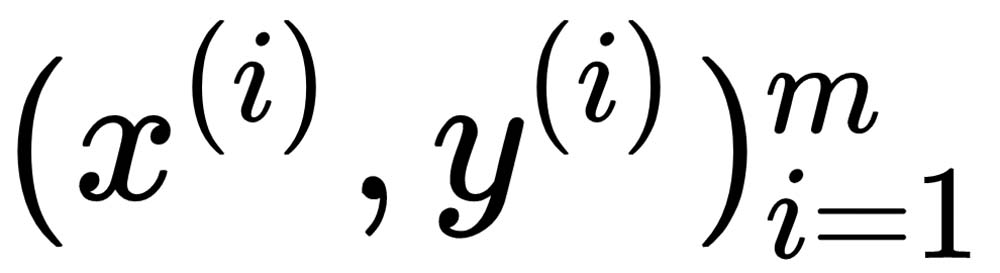 , where x is the feature vector and y is the output class. We can then derive complex features, such as vector h, from the pre-trained VGG16 network, as follows:
, where x is the feature vector and y is the output class. We can then derive complex features, such as vector h, from the pre-trained VGG16 network, as follows:
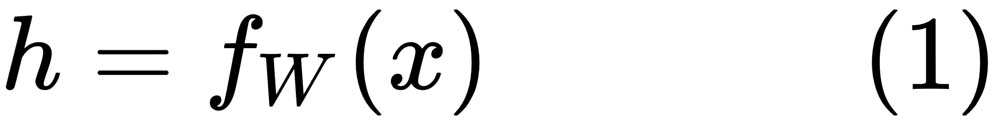
Here, W is the set of weights of the pre-trained VGG16 network, up to the last pooling layer.
We can then use the transformed set of training data points, 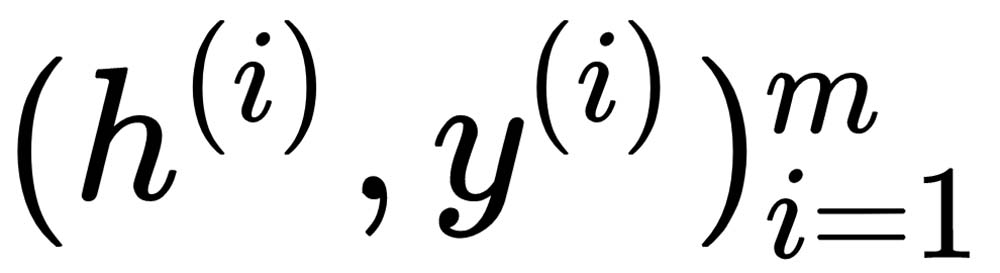 , to build a relatively simple model.
, to build a relatively simple model.
- 圖解西門子S7-200系列PLC入門
- Istio入門與實戰(zhàn)
- 電腦軟硬件維修大全(實例精華版)
- 精選單片機(jī)設(shè)計與制作30例(第2版)
- 嵌入式系統(tǒng)設(shè)計教程
- micro:bit魔法修煉之Mpython初體驗
- 電腦軟硬件維修從入門到精通
- 計算機(jī)組裝與維修技術(shù)
- CC2530單片機(jī)技術(shù)與應(yīng)用
- 單片機(jī)系統(tǒng)設(shè)計與開發(fā)教程
- 固態(tài)存儲:原理、架構(gòu)與數(shù)據(jù)安全
- 筆記本電腦維修實踐教程
- 單片機(jī)技術(shù)及應(yīng)用
- 單片微機(jī)原理及應(yīng)用
- 單片機(jī)原理與技能訓(xùn)練