- Apache Spark Quick Start Guide
- Shrey Mehrotra Akash Grade
- 494字
- 2021-07-02 13:40:00
What is an RDD?
RDD is at the heart of every Spark application. Let's understand the meaning of each word in more detail:
- Resilient: If we look at the meaning of resilient in the dictionary, we can see that it means to be: able to
recover quickly from difficult conditions.
Spark RDD has the ability to recreate itself if something goes wrong. You must be wondering, why does it need to recreate itself? Remember how HDFS and other data stores achieve fault tolerance? Yes, these systems maintain a replica of the data on multiple machines to recover in case of failure. But, as discussed in Chapter 1, Introduction to Apache Spark, Spark is not a data store; Spark is an execution engine. It reads the data from source systems, transforms it, and loads it into the target system. If something goes wrong while performing any of the previous steps, we will lose the data. To provide the fault tolerance while processing, an RDD is made resilient: it can recompute itself. Each RDD maintains some information about its parent RDD and how it was created from its parent. This introduces us to the concept of Lineage. The information about maintaining the parent and the operation is known as lineage. Lineage can only be achieved if your data is immutable. What do I mean by that? If you lose the current state of an object and you are sure that previous state will never change, then you can always go back and use its past state with the same operations, and you will always recover the current state of the object. This is exactly what happens in the case of RDDs. If you are finding this difficult, don't worry! It will become clear when we look at how RDDs are created.
Immutability also brings another advantage: optimization. If you know something will not change, you always have the opportunity to optimize it. If you pay close attention, all of these concepts are connected, as the following diagram illustrates:
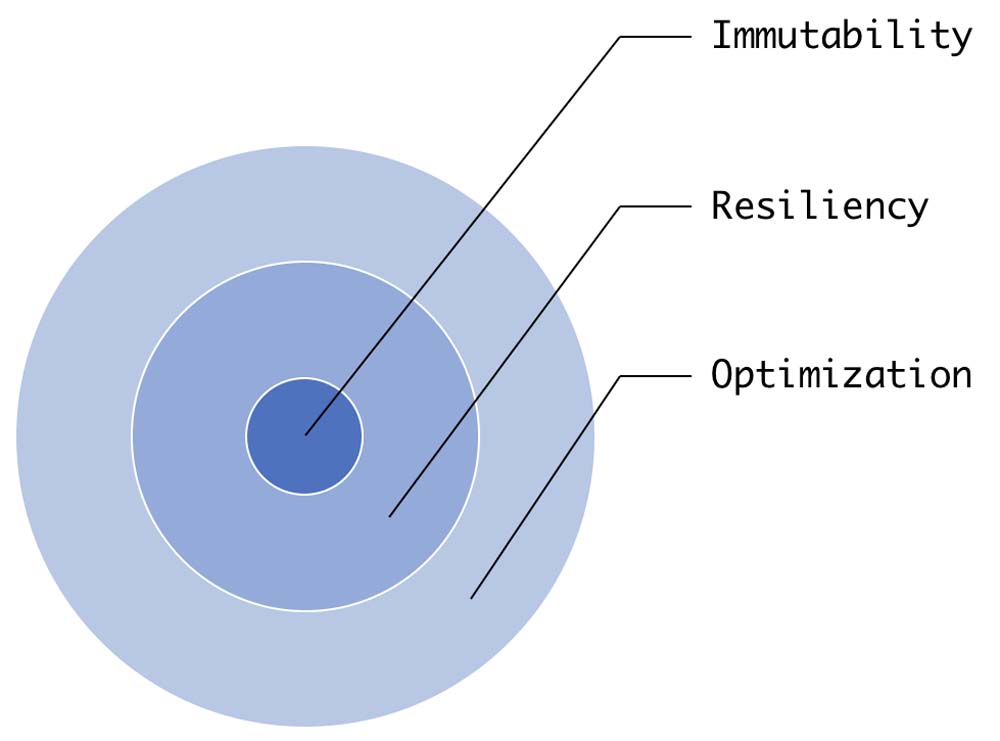
RDD
- Distributed: As mentioned in the following bullet point, a dataset is nothing but a collection of objects. An RDD can distribute its dataset across a set of machines, and each of these machines will be responsible for processing its partition of data. If you come from a Hadoop MapReduce background, you can imagine partitions as the input splits for the map phase.
- Dataset: A dataset is just a collection of objects. These objects can be a Scala, Java, or Python complex object; numbers; strings; rows of a database; and more.
Every Spark program boils down to an RDD. A Spark program written in Spark SQL, DataFrame, or dataset gets converted to an RDD at the time of execution.
The following diagram illustrates an RDD of numbers (1 to 18) having nine partitions on a cluster of three nodes:
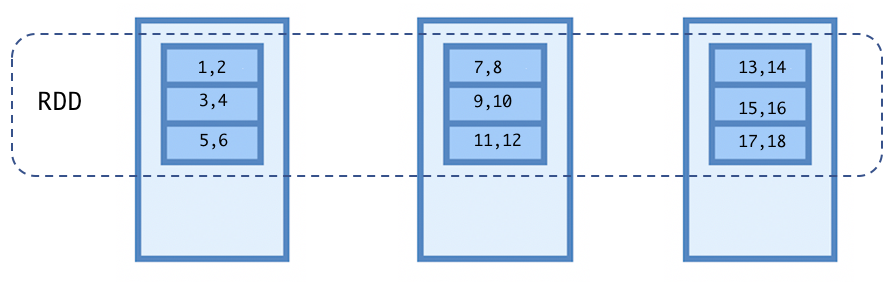
RDD
推薦閱讀
- Hands-On Intelligent Agents with OpenAI Gym
- 走入IBM小型機(jī)世界
- 數(shù)據(jù)運(yùn)營之路:掘金數(shù)據(jù)化時代
- 數(shù)控銑削(加工中心)編程與加工
- 基于ARM 32位高速嵌入式微控制器
- 自動控制理論(非自動化專業(yè))
- 分?jǐn)?shù)階系統(tǒng)分析與控制研究
- Machine Learning with Apache Spark Quick Start Guide
- Excel 2007常見技法與行業(yè)應(yīng)用實(shí)例精講
- Linux內(nèi)核精析
- 簡明學(xué)中文版Photoshop
- 3ds Max造型表現(xiàn)藝術(shù)
- 機(jī)器學(xué)習(xí)案例分析(基于Python語言)
- 自適應(yīng)學(xué)習(xí):人工智能時代的教育革命
- Flink內(nèi)核原理與實(shí)現(xiàn)