- Hands-On Unsupervised Learning with Python
- Giuseppe Bonaccorso
- 388字
- 2021-07-02 12:32:06
Adjusted Mutual Information (AMI) score
The main goal is of this score is to evaluate the level of agreement between Ytrue and Ypred without taking into account the permutations. Such an objective can be measured by employing the information theory concept of Mutual Information (MI); in our case, it's defined as:
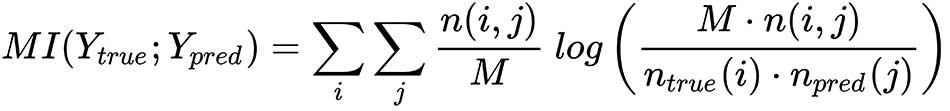
The functions are the same as previously defined. When MI → 0, n(i, j) → ntrue(i)npred(j), whose terms are proportional respectively to p(i, j) and ptrue(i)ppred(j). Hence, this condition is equivalent to saying that Ytrue and Ypred are statistically independent and there's no agreement. On the other side, with some simple manipulations, we can rewrite MI as:
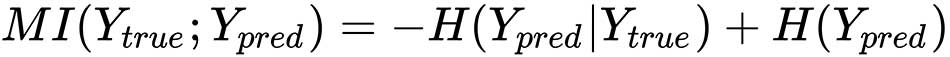
Hence, as H(Ypred|Ytrue) ≤ H(Ypred), when the knowledge of the ground truth reduces the uncertainty about Ypred, it follows that H(Ypred|Ytrue) → 0 and the MI is maximized. For our purposes, it's preferable to consider a normalized version (bounded between 0 and 1) that is also adjusted for chance (that is, considering the possibility that a true assignment is due to the chance). The AMI score, whose complete derivation is non-trivial and beyond the scope of this book, is defined as:
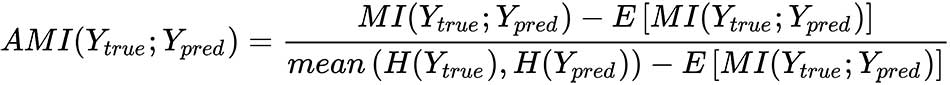
This value is equal to 0 in the case of the total absence of agreement and equal to 1 when Ytrue and Ypred completely agree (also in the presence of permutations). For the Breast Cancer Wisconsin dataset and K=2, we obtain the following:
from sklearn.metrics import adjusted_mutual_info_score
print('Adj. Mutual info: {}'.format(adjusted_mutual_info_score(kmdff['diagnosis'], kmdff['prediction'])))
The output is as follows:
Adj. Mutual info: 0.42151741598216214
The agreement is moderate and compatible with the other measure. Assuming the presence of permutations and the possibility of chance assignments, Ytrue and Ypred share a medium level of information because, as we have discussed, K-means is able to correctly assign all the samples where the probability of overlap is negligible, while it tends to consider benign many malignant samples that are on the boundary between the two clusters (conversely, it doesn't make wrong assignments for the benign samples). Without any further indication, this index suggests also checking other clustering algorithms that can manage non-convex clusters, because the lack of shared information is mainly due to the impossibility of capturing complex geometries using standard balls (in particular in the subspace where the overlap is more significant).
- Learning SQL Server Reporting Services 2012
- Linux KVM虛擬化架構實戰(zhàn)指南
- Applied Unsupervised Learning with R
- Creating Dynamic UI with Android Fragments
- 電腦常見故障現場處理
- The Applied AI and Natural Language Processing Workshop
- OUYA Game Development by Example
- Practical Machine Learning with R
- Creating Flat Design Websites
- 筆記本電腦應用技巧
- 龍芯自主可信計算及應用
- Spring Security 3.x Cookbook
- Mastering Machine Learning on AWS
- 嵌入式系統(tǒng)原理及應用:基于ARM Cortex-M4體系結構
- Angular 6 by Example