- Hands-On Deep Learning for Games
- Micheal Lanham
- 482字
- 2021-06-24 15:48:00
Training a GAN
Training a GAN requires a fair bit more attention to detail and an understanding of more advanced optimization techniques. We will walk through each section of this function in detail in order to understand the intricacies of training. Let's open up Chapter_3_1.py and look at the train function and follow these steps:
- At the start of the train function, you will see the following code:
def train(self, epochs, batch_size=128, save_interval=50):
(X_train, _), (_, _) = mnist.load_data()
X_train = X_train / 127.5 - 1.
X_train = np.expand_dims(X_train, axis=3)
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
- The data is first loaded from the MNIST training set and then rescaled to the range of -1 to 1. We do this in order to better center that data around 0 and to accommodate our activation function, tanh. If you go back to the generator function, you will see that the bottom activation is tanh.
- Next, we build a for loop to iterate through the epochs like so:
for epoch in range(epochs):
- Then we randomly select half of the real training images, using this code:
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
- After that, we sample noise and generate a set of forged images with the following code:
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
gen_imgs = self.generator.predict(noise)
- Now, half of the images are real and the other half are faked by our generator.
- Next, the discriminator is trained against the images generating a loss for incorrectly predicted fakes and correctly identified real images as shown:
d_loss_real = self.discriminator.train_on_batch(imgs, valid)
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
- Remember, this block of code is running across a set or batch. This is why we use the numpy np.add function to add the d_loss_real, and d_loss_fake. numpy is a library we will often use to work on sets or tensors of data.
- Finally, we train the generator using the following code:
g_loss = self.combined.train_on_batch(noise, valid)
print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
if epoch % save_interval == 0:
self.save_imgs(epoch)
- Note how the g_loss is calculated based on training the combined model. As you may recall, the combined model takes the input from real and fake images and backpropagates the training back through the entire model. This allows us to train both the generator and discriminator together as a combined model. An example of how this looks is shown next, but just note that the image sizes are a little different than ours:
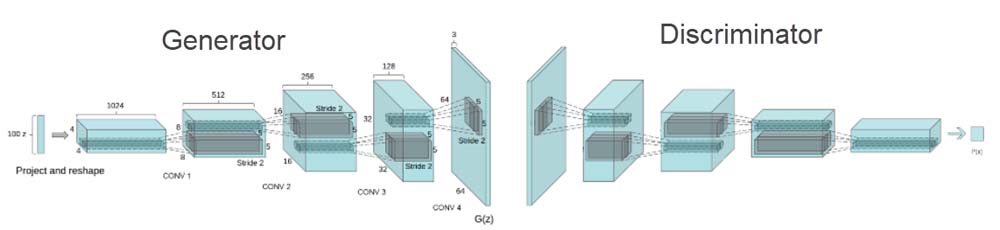
Layer architecture diagram of DCGAN
Now that we have a better understanding of the architecture, we need to go back and understand some details about the new layer types and the optimization of the combined model. We will look at how we can optimize a joined model such as our GAN in the next section.