- The Artificial Intelligence Infrastructure Workshop
- Chinmay Arankalle Gareth Dwyer Bas Geerdink Kunal Gera Kevin Liao Anand N.S.
- 612字
- 2021-06-11 18:35:22
Storage Requirements
It's crucial to keep track of the requirements of your solution in all phases of the project. Since most projects follow the agile methodology, it's not an option to just define the requirements at the start of the project and then "get to work."
The agile methodology requires team members to continuously reflect on the initial plan and requirements provided in the Deming cycle, as shown in the following figure:
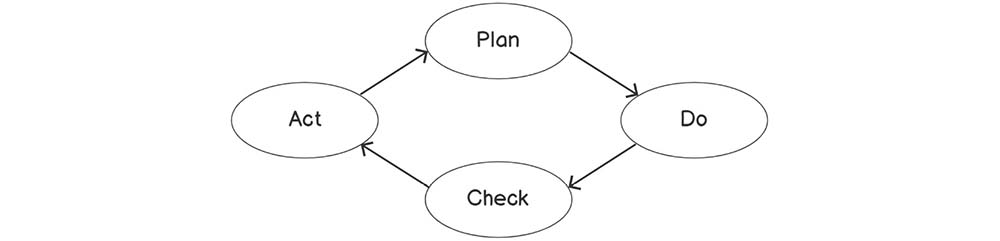
Figure 2.1: The Deming cycle
A list of requirements can be pided into functional and non-functional requirements. The functional requirements contain the user stories that explain how to interact with the system; these are not in the scope of this book since they are less technical and more concerned with UX design and customer journeys. The non-functional (or technical) requirements contain descriptions of the required workings of the system. The non-functional architecture requirements for an AI storage solution describe the technical aspects and have an impact on technology choices and their way of working. The major requirements of an AI system are as follows:
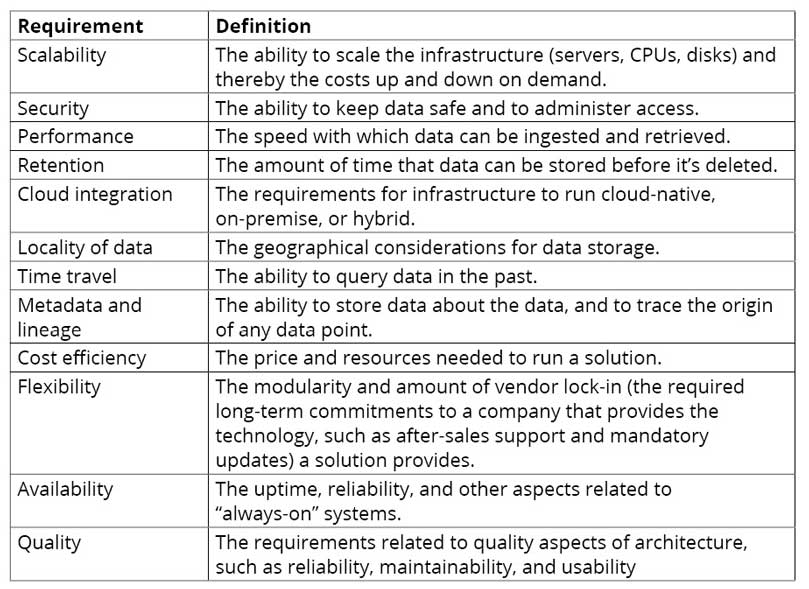
Figure 2.2: Requirements for AI systems
Since this a very extensive list and some requirements are more important for a certain architectural layer than others, we will list the most important requirements per architecture layer. Before we start with that deep pe, we'll give a brief overview of the architecture of an AI system or data lake.
Throughout this chapter, we'll provide you with an example of a use case that helps translate the abstract concepts in the requirements for data storage to real-world, hands-on content. Although the sample is fictional, it's built on some common projects that we came across in real life. Therefore, the situation, target architecture, and requirements are quite realistic for an AI project.
A bank in the UK (let's say it's called PacktBank) wanted to upgrade its data storage systems to create a better environment for data scientists for AI-related projects. Currently, the data is spread out in various source systems, ranging from an old ERP system to on-premise Oracle databases, to a SaaS solution in the cloud. The new data environment (data lake) must be secure, accessible, high-performing, scalable, and easy to use. The target infrastructure is Amazon Web Services (AWS), but in the future, the company might switch to other cloud vendors or take a multi-cloud strategy; therefore, the software components should be vendor-agnostic if possible.
The Three Stages of Digital Data
It's important to realize that data storage comes in three stages:
- At rest: Data that is stored on a disk or in memory for long-term storage; for example, data on a hard disk or data in a database.
- In motion: Data that is transferred across a network from one system to another. Sometimes, this is also called in transit; for example, HTTP traffic on the internet, or data that comes from a database and is "on its way" to an application.
- In use: Data that is loaded in the RAM of an application for short-term usage. This data is only available in the context of the software that is loaded. It can be seen as a cache that is temporarily needed by the software that performs tasks on the data. The data is usually a copy of data at rest; for example, a piece of customer information (let's say, a changed home address) that has been pushed from a website to the server where an API processes the update.
These stages are important to keep in mind when reasoning about technology, security, scalability, and so on. We'll bring them up in this book in several places, so make sure that you understand the differences.
- ATmega16單片機項目驅動教程
- Mastering Delphi Programming:A Complete Reference Guide
- Learning Game Physics with Bullet Physics and OpenGL
- Large Scale Machine Learning with Python
- Apple Motion 5 Cookbook
- Visual Media Processing Using Matlab Beginner's Guide
- STM32嵌入式技術應用開發全案例實踐
- 筆記本電腦維修300問
- Creating Flat Design Websites
- 單片機原理與技能訓練
- 可編程邏輯器件項目開發設計
- 微服務實戰(Dubbox +Spring Boot+Docker)
- 計算機組裝、維護與維修項目教程
- Advanced Machine Learning with R
- 基于S5PV210處理器的嵌入式開發完全攻略