- Julia機器學習核心編程:人人可用的高性能科學計算
- 朱紅慶
- 1149字
- 2020-07-28 11:01:31
1.4 Julia在數據科學中的重要性
在過去的十年中,“大數據”已經成為一個流行詞。數據科學也漸漸走進人們的視野中,在數據科學領域進行研究的人被稱為數據科學家,他們獲取原始數據并對其進行分析,充分挖掘蘊藏在散亂數據中的價值。要做到這一點,數據科學家需要獨特的技能組合,即牢固的數學和算法基礎,并且對人類行為有良好的理解,從而具有從數據中挖掘出價值,并置于合適位置的能力。
數據科學家掌握的技能各不相同,但一般來說,他們都很擅長編程,并且具有很強的數學背景,尤其是統計學、機器學習和大數據知識,同時深入了解其正在工作的領域。Julia是專門為科學和數值計算而設計的。隨著大數據的出現和火爆,需要有一種可以高效處理大量數據的語言。雖然我們有Spark和MapReduce(Hadoop)作為處理引擎,并通過Python、Scala和Java來使用它們,但Julia與Intel的高性能分析工具包是其更好的替代。值得注意的是,Julia擅長并行計算,而且比Spark/Hadoop更容易編寫原型。
Julia的一個重要特點就是它解決了雙語問題。通常,在使用Python和R時,執行大部分繁重計算工作的代碼都是用C/C++編寫的,然后在Python或R中調用它們。但在Julia中不需要這樣做,因為它的性能可以與C/C++媲美。因此,所有的代碼包括任務繁重的計算部分,都可以使用原生的Julia語言來進行編寫。
下面簡單說說性能基準測試的情況。
上面提到了Julia優秀的運行速度,這個特點也讓Julia與傳統的動態語言區別開來,速度快是它的特長。那么Julia到底有多快呢?我們在具有1TB、1067MHz DDR3 RAM的Intel(R) Xeon(R) CPU E7-8850 2.00GHz CPU的單核(串行執行)上對Julia與其他語言進行性能基準測試,結果如表1-1所示。
表1-1 性能基準測試結果
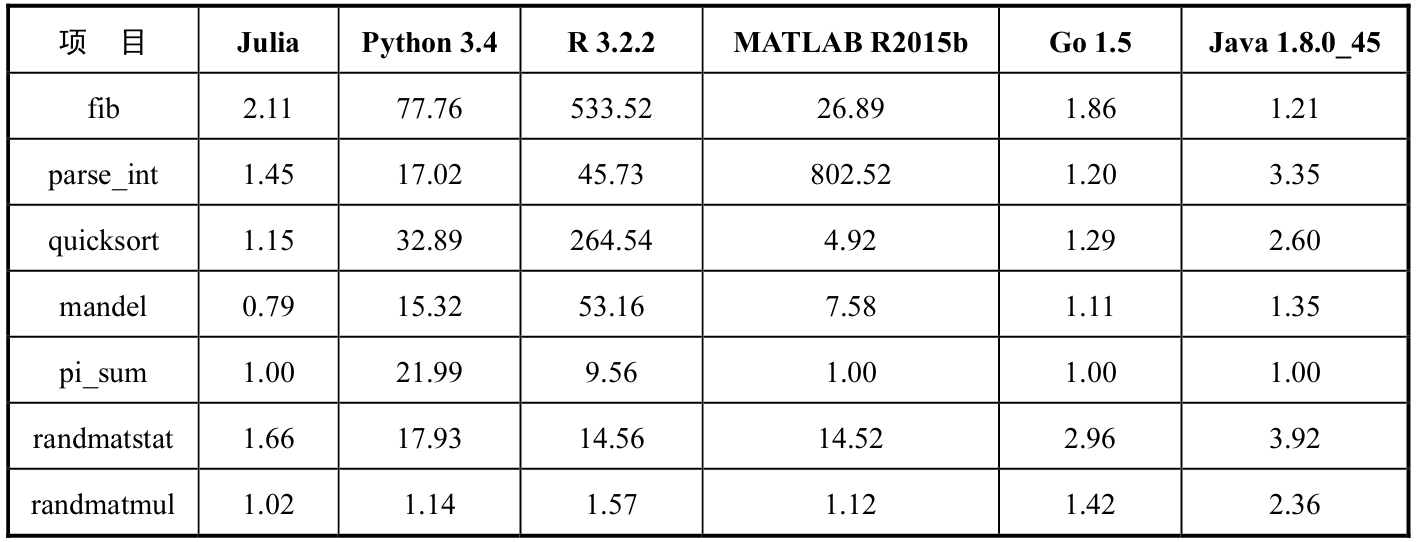
這些基準測試是相對C而言的(數值越小越好,此處將C語言的性能數值設為基準參照值,即1.0)。雖然基準測試會有一定的誤差,但仍然可以看出Julia的性能非常優秀。
從表1-1可以看出,在基準測試中Julia和Python的性能差異很大。但是在某些項目上二者的性能差異不大,原因是一些可用于Python的數值計算包是用C語言編寫的,這里它的表現幾乎等同于Julia。
R是專門為統計人員設計的,它有大量免費的統計和數值計算包。R曾經是數據科學家的首選語言(現在首選Python)。但R有一個致命的缺點,就是它是單線程的,比Julia慢得多。
MATLAB不是免費產品,你需要購買付費許可證(學生可以獲得折扣),統計學家和學者通常使用它來處理某些特定用例。表1-1所示的這些基準測試項目在MATLAB上運行要慢得多。
Go是從頭開始設計的,用于系統編程。Go由谷歌創建,其源代碼可以在GitHub上獲得,同時谷歌正在不斷積極地開發和更新Go語言。Go在表1-1所示的這些基準測試項目中的表現非常出色,但很可惜的是它并非專為數字和科學計算而設計,所以在使用時沒有Julia友好。
Java的表現非常優秀,它甚至在一些基準測試項目中擊敗了Julia。但Java是一種靜態語言,我們需要考慮與之相關的開發時間。相比于Java,Julia的設計使其可用于快速原型開發,這些優點使得Julia在眾多語言中顯得獨一無二。