- C#網絡程序開發(第二版)
- 何波 傅由甲
- 4382字
- 2020-06-30 17:14:23
2.4 C#套接字與網絡流
2.4.1 Socket類
套接字是支持TCP/IP網絡通信的基本操作單元。在一個套接字既保存了本機的IP地址和端口,也保存了對方主機的IP地址和端口,同時還有雙方通信的協議信息。C#的命名空間System.Net.Sockets提供了Socket類。一個Socket實例包含一個本地或者一個遠程的套接字信息。
Socket可以像流(Stream)一樣被視為數據通道,這個通道存在于服務器和客戶端之間。數據的發送和接收均通過這個通道進行。所以在應用程序創建Socket對象后,就可以用Send/SendTo方法將數據發送到連接的Socket中,或者使用Receive/ReceiveFrom方法接收連接的Socket數據。圖2-11顯示了客戶機(Client)和服務器(Server)進行通信的一般過程。
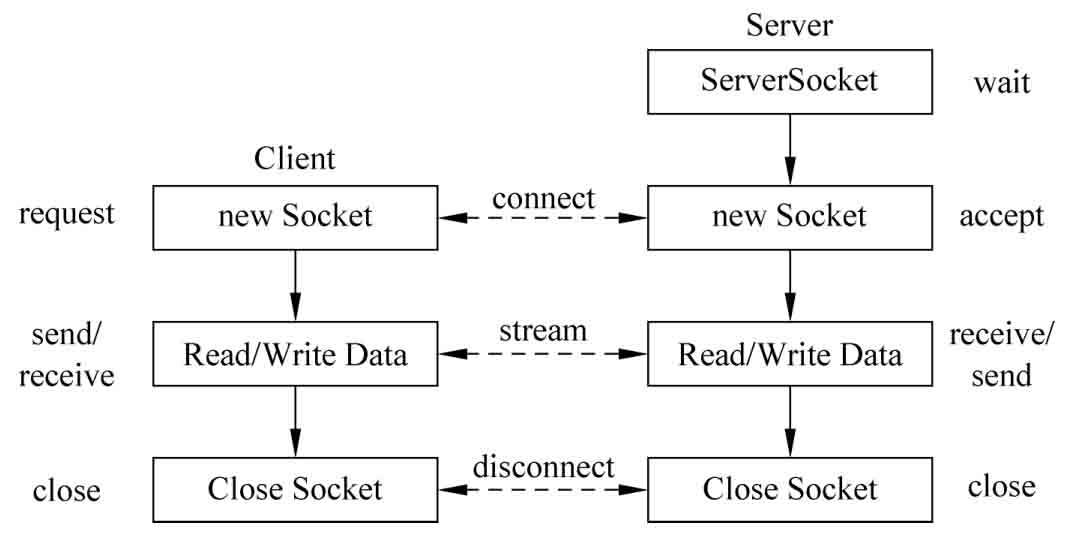
圖2-11 Socket通信模型
Socket類為網絡通信程序提供了豐富的方法和屬性。System.Net.Sockets命名空間中常用的TcpClient類、TcpListener類和UdpClient類都是以該類為基礎的。
2.4.2 套接字的類型與使用方法
1. Socket類的類型
套接字有3種不同類型:流套接字、數據報套接字和原始套接字。
(1)流套接字用來實現TCP通信,提供了面向連接的、可靠的、數據無錯且無重復的數據傳輸服務,并且發送和接收的數據的順序是相同的。
(2)數據報套接字用來實現UDP通信,提供了面向無連接的服務,它以獨立的數據報形式發送數據(數據包的長度不能大于32KB),不提供正確性檢查,也不保證各數據包的發送和接收順序,所以可能會出現數據重發、丟失等情況。
(3)原始套接字用來實現IP數據包通信,用于直接訪問協議的較低層,常用于偵聽及分析數據包,廣泛應用于高級網絡編程,也是一種經常使用的黑客手段。
這3種類型的套接字均可以使用System.Net.Sockets命名空間中的Socket類來實現。Socket的構造函數為:
public Socket(AddressFamily addressFamily,SocketType socketType,ProtocolType protocolType);
各參數的含義如下。
①addressFamily:指網絡類型,使用AddressFamily枚舉指定Socket使用的尋址方案,常見的有AddressFamily.InterNetwork(表示IPv4的地址)和AddressFamily.InterNetmorkV6(表示IPv6的地址)。
②socketType和protocolType:這兩個枚舉類型的參數必須對應,共同指明Socket使用哪種協議的哪種套接字。表2-5列出這兩個參數的組合。
表2-5 套接字類型與協議對應關系

了解了構造函數的參數含義后,就可以創建套接字實例了,例如:
Socket socket=new Socket(AddressFamily.InterNetwork,SocketType.stream,ProtocolType.Tcp)
表示創建基于TCP協議的IPv4流套接字。
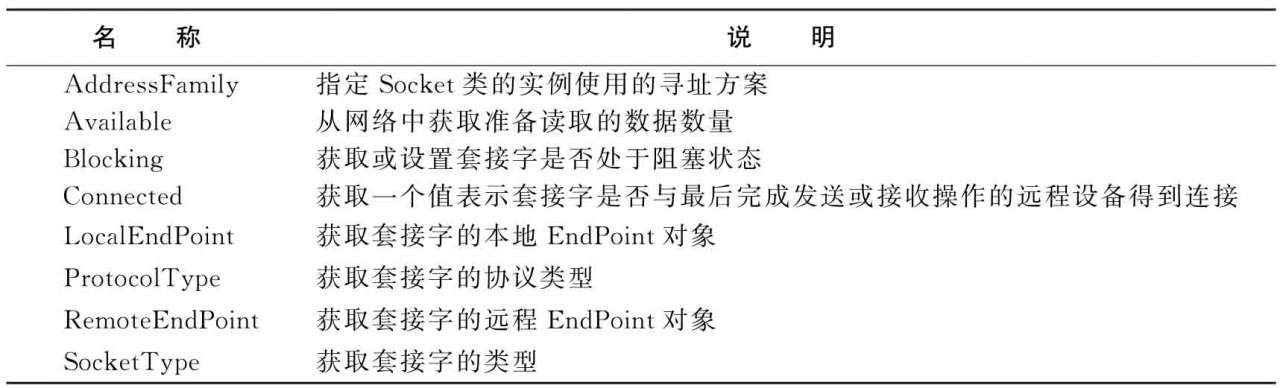
2. Socket類的常用屬性
表2-6列出套接字的一些常用的屬性。
表2-6 套接字的常用屬性
3. Socket類的常用方法
1)void Connect(IPEndPoint remoteIcp)
該方法客戶機獨有,通過遠程設備的套接字建立與遠程設備的連接。
2)int Send()/int Receive()
這兩個方法在完成客戶端的連接后,將數據發送到連接到的Socket上以及將數據從連接的Socket接收到緩沖區的指定位置。當Receive方法沒有可讀的數據時,將一直處于阻止狀態。
3)void Bind(IPEndPoint localIcp)
該方法對應服務器程序而言,使用Socket與本地IP地址和端口號關聯。
4)void Listen(int backlog)
該方法用于等待客戶端發出連接請求,其中的backlog為用戶的最大連接數,超過該參數值的其他客戶不能與服務器進一步通信。
5)Socket Accept()
該方法創建新的Socket以處理連接請求。當程序執行到該方法時會處于阻塞狀態,直到有新的客戶機請求連接。該方法返回包含客戶端信息的套接字句柄。
6)void ShutDown()
該方法在通信完成后負責將連接釋放,并關閉socket對象。表2-7列出了ShutDown方法可以使用的值。
表2-7 Socket.ShutDown值

7)void Close()
該方法關閉遠程主機連接,并釋放所有與Socket關聯的資源。關閉后,Connected屬性將設置為false。對于面向連接的協議,先調用Shutdown方法,再調用Close方法,以確保在已連接的套接字關閉之前,已發送和接收該套接字上的所有數據。
4. 面向連接的套接字
面向連接的套接字使用TCP建立兩個IP地址端點間的通信。根據連接啟動的方式及本地Socket要連接的目標,套接字間的連接包括服務器監聽、客戶端請求、連接確認3個步驟。建立連接后的套接字雙方可以進行數據傳輸。其編程步驟如圖2-12所示。
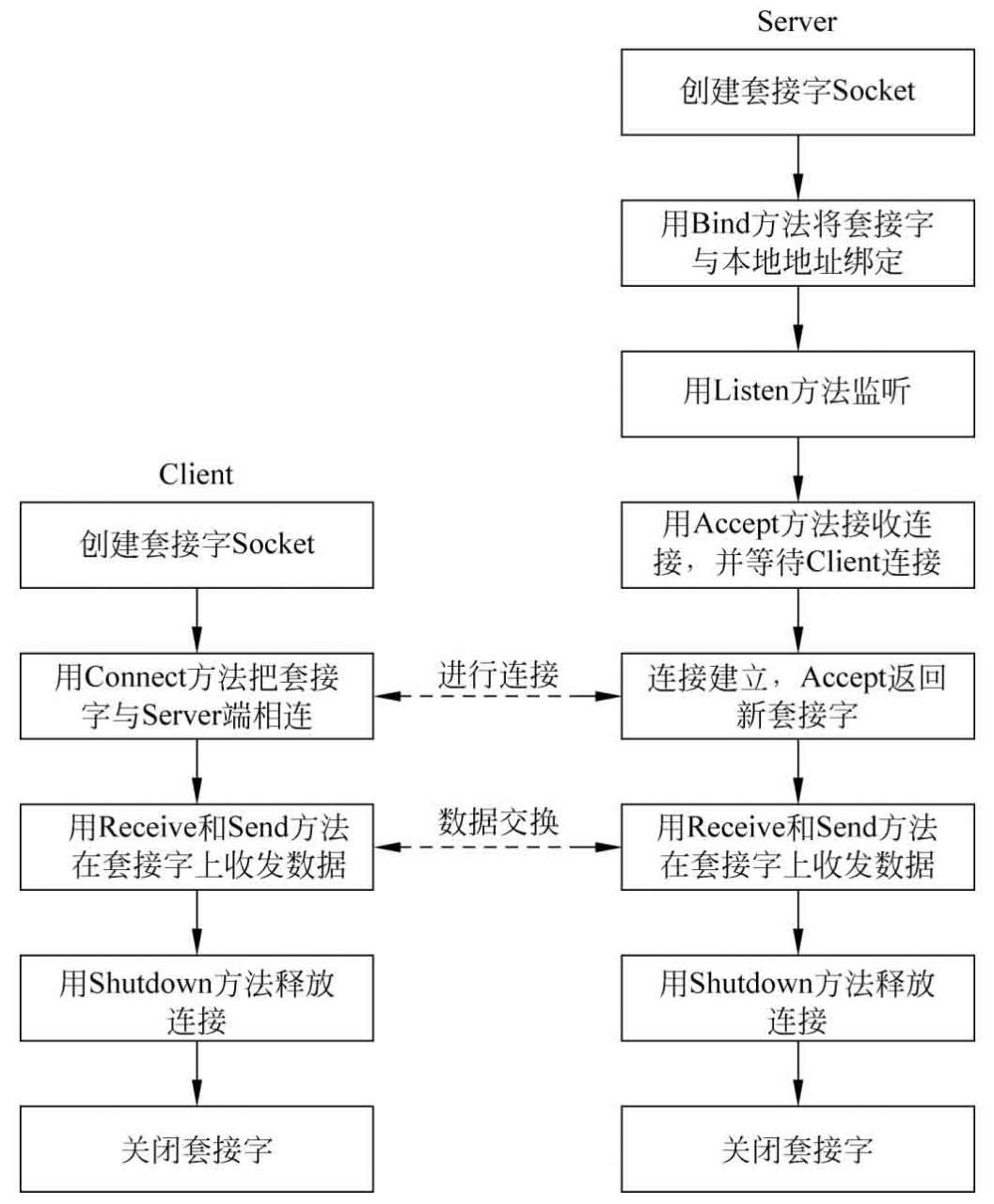
圖2-12 面向連接的套接字編程流程
【例2-3】 編寫控制臺程序,利用同步的面向連接Socket實現客戶端和服務器的消息通信。
(1)編寫服務器端程序,Program類中代碼如下:

(2)編寫客戶端程序,Program類中代碼如下:

5. 無連接的套接字
無連接的套接字使用UDP協議,不需要像面向連接的套接字那樣發送連接信息,即沒有使用Connect方法進行連接的步驟,發送進程直接使用SendTo方法進行數據發送;但是如果一個進程是等待遠程設備的信息,則套接字必須用Bind方法綁定到一個本地“IP地址/端口”上,完成綁定后才能使用ReceiveFrom方法接收數據。其編程步驟如圖2-13所示。
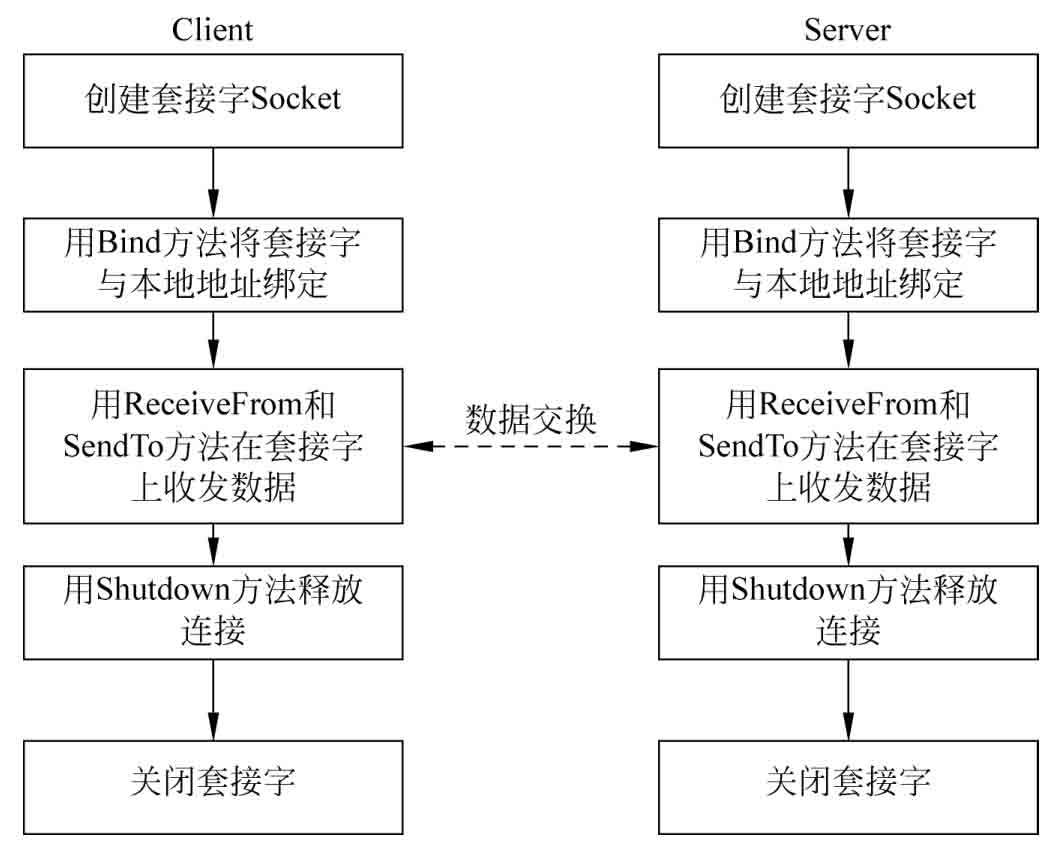
圖2-13 無連接的套接字編程流程
【例2-4】 編寫控制臺程序,利用無連接Socket實現接收方和發送方的消息通信。
(1)編寫接收方程序,Program類中代碼如下:

(2)編寫發送方程序,Program類中代碼如下:

2.4.3 網絡流
當通過網絡傳輸數據,或對文件數據進行操作時,需要將數據轉化為數據流的形式。數據流(stream)是對串行傳輸的數據(以字節為單位)的一種抽象表示,數據源可以是文件、外部設備、主存、網絡套接字等。數據流分為文件流、內存流和網絡流。網絡流用于在網絡上傳輸數據。使用網絡流時,數據在網絡的各個位置之間以連續的字節形式傳輸。為了處理這種網絡流,C#在System.Net.Sockets命名空間中提供了NetworkStream類用于收發網絡數據。
NetworkStream類相當于在網絡數據的源端和目的端之間架起了一個數據橋梁,使得讀取和寫入數據只針對這個通道進行。但NetworkStream類只支持面向連接的套接字。
對于NetworkStream流,寫入操作是從源端內存緩沖區到網絡上的數據傳輸,讀取操作是從網絡上到目的端內存緩沖區的數據傳輸,如圖2-14所示。

圖2-14 NetworkStream流的數據傳輸
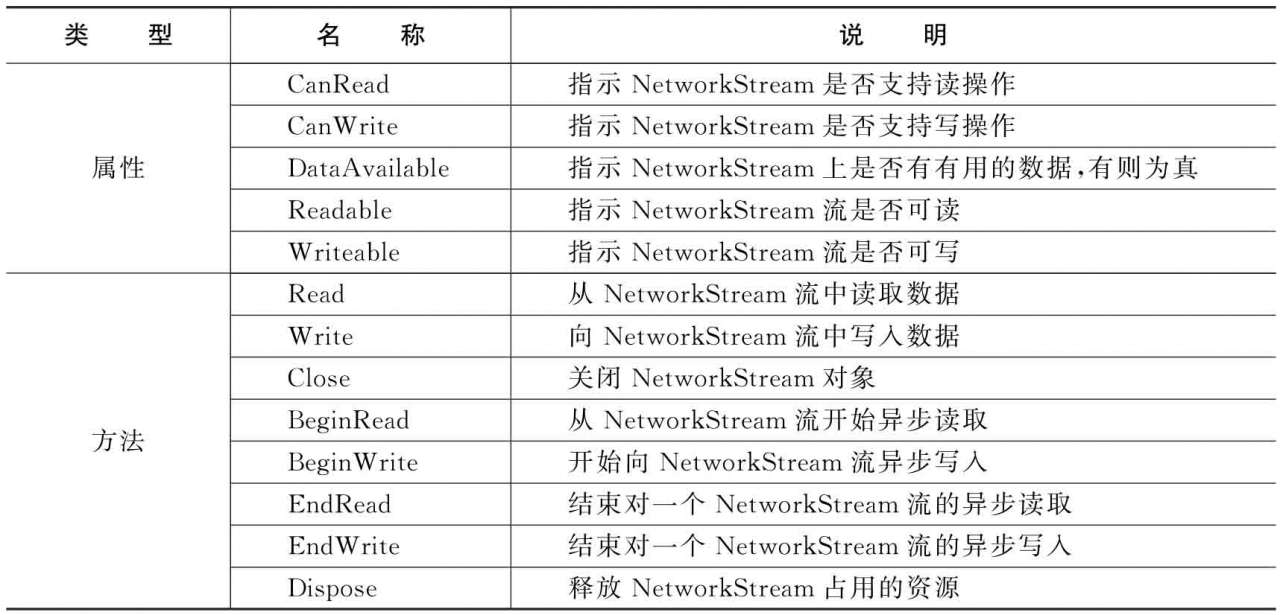
表2-8列出了NetworkStream類的常用屬性和方法。
表2-8 NetworkStream類的常用屬性和方法
下面介紹如何使用NetworkStream收發網絡數據。
1. 獲取NetworkStream實例
在構造一個NetworkStream實例后,就可以用它來收發網絡數據。
(1)利用TcpClient獲取網絡流對象。例如:
TcpClient tcpClient=new TcpClient();
tcpClient.Connect("www.cqut.edu.cn",5188);
NetworkStream myNteworkStream=tcpClient.GetStream();
(2)利用Socket獲取網絡流對象。例如:
NetworkStream myNetworkStream=new NetworkStream(mySocket);//mySocket為獲取的Socket對象
2. 利用NetworkStream實例收發數據
圖2-15顯示了利用網絡流收發數據的流程。其中,Write方法負責將字節數組從進程緩沖區發送到本機的TCP發送緩沖區,然后TCP/IP協議棧再通過網絡適配器將數據真正發送到網絡上,最終到達接收方的TCP接收緩沖區。

圖2-15 NetworkStream流收發數據的流程
由于Write方法為同步方法,所以在發送成功或者返回異常前都將處于阻塞狀態,直到發送成功或者返回異常。
下面的代碼給出使用NetworkStream發送數據的一個示例。
if(myNetworkStream.Canwrite)
{
byte[]myWriteBuffer=Encoding.ASCII.GetBytes("Are you receiving this message?");
myNetworkStream.Write(myWriteBuffer,0,myWriteBuffer.Length);
}
else
Console.WriteLine("Sorry.You cannot write to this NetworkStream.");
接收方通過調用Read方法將數據從接收緩沖區讀入到進程緩沖區,完成讀取操作。
下面的代碼給出使用NetworkStream讀取數據的一個示例。
if(myNetworkStream.CanRead)
{
byte[]myReadBuffer=new byte[1024];
String myCompleteMessage="";
int numberOfBytesRead=0;
//準備接收的信息有可能大于1024,所以用循環
do{
numberOfBytesRead=myNetworkStream.Read(myReadBuffer,0,myReadBuffer.Length);
myCompleteMessage=String.Concat(myCompleteMessage,Encoding.ASCII.GetString(myReadBuffer,
0,numberOfBytesRead));
}while(myNetworkStream.DataAvailable);
}
使用NetworkStream實例時,需要注意以下幾點:
(1)通過DataAvailable屬性,可以查看在緩沖區中是否有數據等待讀出。
(2)網絡流沒有當前位置的概念,因此它不支持對數據流的查找和隨機訪問。
(3)網絡數據傳輸完成后,必須用Close方法關閉NetworkStream實例。
2.4.4 網絡數據編碼與解碼
在網絡通信中,很多時候通信雙方傳達的是字符信息。但是字符信息不能直接在網絡中傳遞,而是需要轉換成一個字節序列后才能在網絡中傳輸。將字符序列轉換為字節序列的過程稱為編碼;反之即為解碼。
1. 常見字符編碼方式
常見的字符編碼方式有以下3種:
1)ASCII字符集
ASCII字符集是美國信息交換標準委員會(American Standards Committee for Information Interchange)的縮寫,在20世紀80年代由美國英語通信所設計。每個ASCII碼由7位構成,整個ASCII字符集由128個字符組成,包括大小寫字母、數字0~9、標點符號、非打印字符(換行符、制表符等4個)以及控制字符(退格、響鈴等)。
2)非ASCII字符集
由于ASCII字符針對英語設計,當處理漢字等其他字符時,這種編碼就不適用了。為解決這個問題,不同國家制訂了自己的編碼標準。我國一般使用國標碼,常用的有GB 2312和GB 18030—2000編碼,其中,GB 18030編碼漢字更多,是我國計算機系統必須遵循的基礎性編碼標準之一。
在GB 2312編碼中,漢字都采用雙字節編碼。為了與系統中基本的ASCII字符集區分開,所有漢字編碼的每個字節的第一位都是1。例如,“啊”字的編碼為0xB0A1。GB 18030是對GB 2312的擴展,其編碼長度由2個字節變為1~4個字節。
3)Unicode字符集
由于每個國家都有自己的編碼方式,要想打開一個文本文件,就必須知道其編碼方式,否則就會出現亂碼。為了讓國際信息交流更加方便,國際組織制定了Unicode字符集。它為各種語言中的每一個字符規定了統一且唯一的字符,并且只需要兩個字節,便可以表示地球上絕大部分地區的文字。
C#的默認字符都是Unicode碼,一個英文字母和一個漢字一樣,都占兩個字節。Unicode碼雖然能夠表示大部分國家的文字,但是其占有空間比ASCII碼大一倍,這對于能用ASCII碼表示的字符顯得有些浪費。因此,又出現了一些中間格式的字符集,它們被稱為通用轉換格式,即UTF(Universal Transformation Format)。目前比較流行的是UTF-8、UTF-16、UTF-32。
UTF-8是Internet上使用最廣泛的一種UTF格式。它是Unicode的一種變長字符編碼,一般用1~4個字節編碼一個Unicode字符,即將一個Unicode字符編為1~4個字節組成的UTF-8格式,根據不同的符號變化字節長度。UTF-8是與字節順序無關的,它的字節順序在所有系統中都是一樣的,故此種編碼可以使排序變得容易。
UTF-16將每個碼位表示為一個由1~2個16位整數組成的序列。
UTF-32將每個碼位表示為一個32位整數。
2. C#中的編碼與解碼類
1)Encoding類
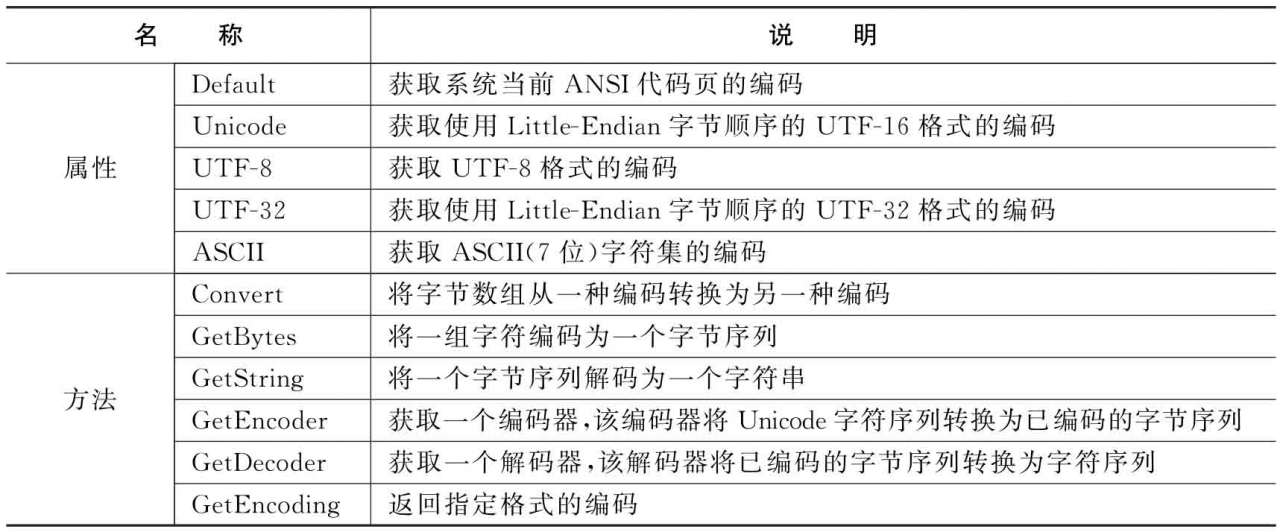
Encoding類位于System.Text命名空間中,主要用于在不同的編碼和Unicode之間進行轉換。表2-9中列出了Encoding類常見的屬性和方法。
表2-9 Encoding類常見的屬性和方法
利用Encoding類的Convert方法可將字節數組從一種編碼轉換為另一種編碼。方法原型為:
Public static byte[]Convert(Encoding srcEncoding,Encoding dstEncoding,byte[]bytes)
各參數含義如下。
srcEncoding:表示源編碼格式。
dstEncoding:表示目標編碼格式。
Bytes:待轉換的字節數組。
返回值為包含轉換結果的Byte類型的數組。
將Unicode字符串轉換為UTF8字符串時,可以參考以下步驟。
(1)利用Encoding的UTF8和Unicode屬性獲取UTF8格式的編碼實例utf8和Unicode編碼實例unicode,例如:
string unicodeString="unicode字符串pi(\u03a0)";
Encoding Unicode=Encoding.Unicode;
Encoding utf8=Ecoding.UTF8;
(2)利用unicode實例的GetBytes方法將Unicode字符編碼為Unicode字節數組:
byte[]unicodeBytes=unicode.GetBytes(unicodeString);
(3)利用Encoding的Convert方法將Unicode字節數組轉換為UTF8字節數組:
byte[]utf8Bytes=Encoding.Convet(Encoding.Unicode,Encoding.UTF8,unicodeBytes);
(4)最后利用實例utf8的GetString方法將UTF8字節數組解碼為UTF8字符串:
string utf8String=utf8.GetString(utf8Bytes);
2)Encoder類和Decoder類
在網絡傳輸和文件操作中,如果數據量比較大,需要將其劃分為較小的塊。對于跨塊傳輸的情況,直接使用Encoding類的GetBytes方法編寫程序比較麻煩,而Encoder和Decoder由于維護了數據塊結尾信息,則可以輕松地實現跨塊字符序列的正確編碼和解碼,因此它們在網絡傳輸和文件操作中很有用。
Encoder和Decoder類位于System.Text命名空間下,Encoder可以將一組字符串轉換為一個字節序列,而Decoder則將已編碼的字節序列解碼為字符序列。Encoder編碼的步驟為:
(1)獲取Encoder實例。利用它對字符編碼首先要獲取Encoder類的實例,由于Encoder的構造函數為protected,不能直接創建該類的實例,必須通過Encoding提供的GetEncoder方法創建實例,例如:
//獲取ASCII編碼的Encoder實例
Encoder ASCiiEncoder=Encoding.ASCII.GetEncoder();
//獲取Unicode編碼的Encoder實例
Encoder unicodeEncoder=Encoding.Unicode.GetEncoder();
(2)GetBytes方法。獲取Encoder實例后,利用它的GetBytes方法將一組字符編碼轉換為字節序列。
方法原型:

該方法將編碼后的字節數組存儲在參數bytes中,返回結果為寫入bytes的實際字節數。如果設置flush為false,則編碼器會將數據塊末尾的尾部字節存儲在內部緩沖區中,為下次編碼操作中使用這些字節做準備。
(3)GetByteCount方法。該方法計算對字符序列進行編碼后所產生的精確字節數,以確定GetBytes方法中byte類型數組實例的長度。
方法原型:

Decoder類解碼的步驟為:首先通過Encoding的GetDecoder方法創建Decoder實例,然后用實例的GetChars方法將字節序列解碼為一組字符。
GetChars方法用于將一個字節序列解碼為一組字符,并從指定的索引位置開始存儲這組字符。
方法原型:

該方法返回chars寫入的實際字符數。
【例2-5】 利用Encoder和Decoder類實現編碼和解碼。

程序運行結果如圖2-16所示。
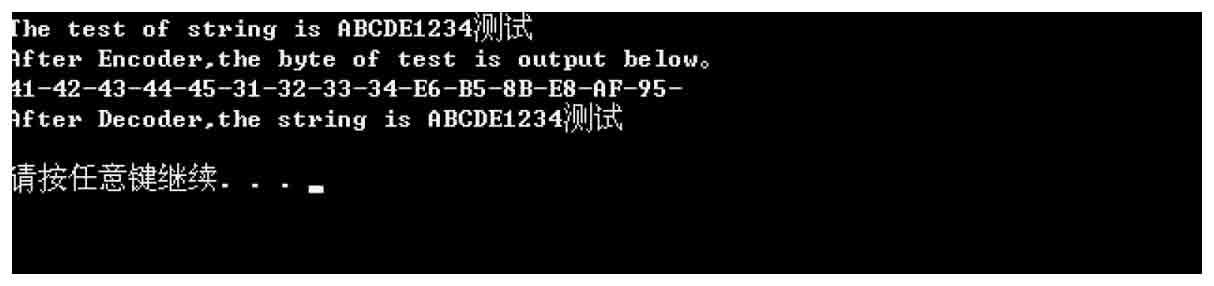
圖2-16 編碼與解碼程序運行結果