- 寫給架構師的Linux實踐:設計并實現基于Linux的IT解決方案
- (哥斯)丹尼斯·薩拉曼卡 埃斯特班·弗洛雷斯
- 1588字
- 2020-06-15 18:40:55
2.2 什么是集群
SDS(軟件定義存儲)有很多優勢可以利用,它能夠幫我們打造易于伸縮且容錯力較強的方案,而GlusterFS就是這樣的一種軟件,用來創建高伸縮力、高性能的存儲集群。
在講解這個具體的軟件之前,首先要定義什么是集群,并說明為什么使用集群,以及它能夠解決什么樣的問題。
2.2.1 用集群處理計算任務
簡單地說,集群是協同運作以處理同一套負載的一系列計算機(通常也稱為節點)。集群會把總負載分配到每一臺可用的計算機上以提升性能,這同時也使得該集群具備自我修復能力與高度的可用性。請注意,集群里的成員叫作節點(node),而不是服務器(server),因為任何計算機都可以加入集群,不一定非得是服務器。無論是簡單的Raspberry Pi(樹莓派),還是擁有許多CPU的服務器,都可以進入集群中構成只有兩個節點的配置方案,或是多達上千個節點的數據中心。
圖2-1描述了集群的結構。
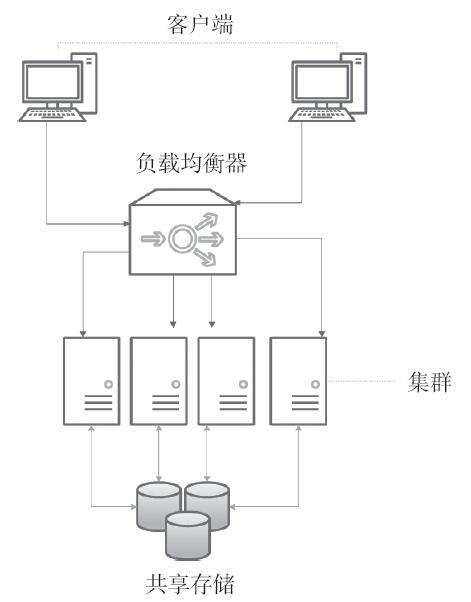
圖2-1
從理論上來說,要想提升集群的工作性能,可以添設資源特征相似的同類型服務器。最理想的情況是集群的所有節點都采用同一套硬件,這樣的話就不會在性能上出現差異,同時也讓維護工作變得相當有規律。要做到這一點,必須采用同一系列的CPU,并按照同一種方式來配置內存及軟件。這種給集群添設節點的辦法,是通過減少處理時間來提升工作效率。對于某些應用來說,工作效率有可能呈線性增長。
為了更好地理解集群的計算原理,我們想象有這樣一個應用程序:它要接收從前的財務數據,收到數據后根據已經存儲的信息,進行預測。如果集群里面只有一個節點,那么這個預報進程(集群里的進程,通常稱為job(工作任務))大約要6天才能完成,因為它需要處理的數據高達數TB(TeraByte)。給集群添設一個特征相似的節點后,處理時間就可以降到4天;若是再添一個,則會降至3天。
請注意,計算資源變為原來的三倍,并不能保證處理時間會降為原來的三分之一。在上述例子中,我們只能把處理時間降到原來的大約二分之一。某些應用確實可以讓速度隨著節點數量呈線性增長 ,但另一些應用則不行。對于后一類應用來說,添加節點所得到的增益越來越少,直至幾乎為零。如果添設新資源所帶來的增益很少,那么這樣做就顯得不夠劃算了。
,但另一些應用則不行。對于后一類應用來說,添加節點所得到的增益越來越少,直至幾乎為零。如果添設新資源所帶來的增益很少,那么這樣做就顯得不夠劃算了。
根據上述內容,可以看出集群的幾個作用:
?可以用更多的計算資源,來降低處理時間。
?可以進行垂直擴展及水平擴展。
?可以實現冗余機制,也就是說,如果其中一個節點故障,那么本來應該由該節點負責的工作,可以交給其他節點負責。
?可以給應用程序提供更多的資源。
?是一套整合的資源池,而不是由許多臺孤立的服務器拼湊起來的。
?沒有故障單點。
2.2.2 存儲集群
上節告訴我們集群是如何處理計算任務的,接下來介紹集群的另外一種用途。
除了可以聚合計算資源以降低處理時間,集群還有一項功能是把可用的存儲空間整合起來,以提升其利用率;同時提供某種形式的冗余機制。現在,越來越多的人要求用較低的成本存放大量的數據,同時又要求提升數據的可用性;而存儲集群把許多存儲節點整合成一個龐大的存儲池,正可以解決這個問題。于是,我們不需要部署特別的專屬硬件,就可以實現PB級別的存儲系統。
例如,如果集群只有一個500TB節點的可用空間,就無法實現出帶有冗余機制的1 PB(PetaByte,等于1024TB)存儲系統。因為該節點在這種情況下會成為故障單點,只要它一故障,整個存儲系統就無法提供數據,冗余得不到保證。此外,由于它的HDD(Hard Disk Drive,硬盤驅動器)只有500TB空余,因此存放不下1PB的數據。總之,只有一個節點是無法實現水平擴展的。
為了解決這個問題,我們可以給集群里再添加兩個相同的節點,與現有的這個節點合起來實現出1PB的存儲系統。有人會問,3個500TB合起來是1.5PB才對,為什么只說是1PB呢?這是因為要想確保該方案具備高可用性,需要讓其中一個節點充當備份節點;如果另外兩個節點里有某個節點發生故障,這個備份節點可以取代故障節點,從而保證集群與客戶之間的通信不受影響。這種節點容錯能力要靠SDS與存儲集群來實現,下節我們就會講解這樣一種采用GlusterFS來實現存儲集群的方式。