- R數(shù)據(jù)科學(xué)實(shí)戰(zhàn):工具詳解與案例分析
- 劉健 鄔書豪
- 4860字
- 2019-08-01 11:34:25
1.1 utils——數(shù)據(jù)讀取基本功
utils包是R語言的基礎(chǔ)包之一。這個包最重要的任務(wù)其實(shí)并不是進(jìn)行數(shù)據(jù)導(dǎo)入,而是為編程和開發(fā)R包提供非常實(shí)用的工具函數(shù)。使用utils包來進(jìn)行數(shù)據(jù)導(dǎo)入和初步的數(shù)據(jù)探索也許僅僅只是利用了utils包不到1%的功能,但這1%卻足以讓你在學(xué)習(xí)R語言時事半功倍。
1.1.1 read.csv/csv2——逗號分隔數(shù)據(jù)讀取
.csv可能是目前最常見的平面文件類型了。它代表的是comma-separated values,簡單來講就是文件里每一個單獨(dú)的數(shù)據(jù)值都是用逗號進(jìn)行分隔的。.csv只是text file(文本文件)的一種,文本文件在微軟的Windows操作系統(tǒng)中常以拓展名為.txt的形式呈現(xiàn)。文本文件可以使用各種符號來分隔數(shù)據(jù)值,例如常見的tab和“;”(分號),或者其他任意符號。即便是以.csv為拓展名的文件也并非一定是以逗號進(jìn)行分隔的,相關(guān)內(nèi)容在本章后面的函數(shù)演示部分會有介紹。文件的拓展名并非必須,熟悉Linux系統(tǒng)的讀者可能接觸過很多無拓展名的文件。處理無拓展名的文本文件數(shù)據(jù)時,最簡單的辦法就是使用data.table包中的fread函數(shù)(相關(guān)內(nèi)容請參見第6章)。
utils里的read.csv/csv2是專門用于設(shè)置快速讀取逗號分隔read.csv或是分號分隔read.csv2。也就是說,在事先了解數(shù)據(jù)值分隔符號的情況下,這兩個函數(shù)對分隔符和其他一些參數(shù)的默認(rèn)設(shè)置會使數(shù)據(jù)導(dǎo)入的部分更加簡單和快捷。有一點(diǎn)需要特別注意,即這兩個函數(shù)對小數(shù)點(diǎn)的處理:前者默認(rèn)的小數(shù)點(diǎn)是“.”,后者默認(rèn)的小數(shù)點(diǎn)是“,”。這只是因?yàn)椴煌瑖壹夹g(shù)人士對數(shù)據(jù)值分隔符的見解或者好惡不同而造成的。
萬里長征第一步,我們先來者read.csv最簡單的使用方式,代碼如下:
> flights <- read.csv(file = "flights.csv")
此行代碼可以解讀為使用read.csv從工作空間讀取文件flights.csv,然后將數(shù)據(jù)集保存到flights中,其他所有參數(shù)都使用默認(rèn)值。因?yàn)閒lights.csv文件已經(jīng)在R的工作路徑里,所以此處免去了設(shè)置work directory。這里希望讀者能夠自行探索使用.rproj(R項(xiàng)目——將每一次數(shù)據(jù)分析的過程都看作一個獨(dú)立的項(xiàng)目)來對每一個獨(dú)立的數(shù)據(jù)分析工作進(jìn)行分類和歸集。該方法不僅免去了設(shè)置路徑的麻煩,也減少了因原始數(shù)據(jù)文件太多而可能導(dǎo)致的各種坑隱患。
小知識
函數(shù)在執(zhí)行的時候可以依照其默認(rèn)設(shè)置的參數(shù)位置來執(zhí)行,也就是說,用戶無須指定每一個參數(shù)的名稱,只須按照位置順序來設(shè)定參數(shù)值即可。比如read.csv中的file參數(shù)名就可以省略,只要第一位是讀取文檔的目標(biāo)路徑和文件名就可以。
數(shù)據(jù)文件被讀取到R工作環(huán)境中的第一步通常為調(diào)用str函數(shù)來對該數(shù)據(jù)對象進(jìn)行初步檢視,下面的代碼列出了該函數(shù)最簡單的使用方式。
> str(object = flights) 'data.frame': 6 obs. of6 variables: $ carrier : Factor w/ 4 levels "AA","B6","DL",..: 4 4 1 2 3 4 $ flight: int1545 1714 1141 725 461 1696 $ tailnum : Factor w/ 6 levels "N14228","N24211",..: 1 2 4 6 5 3 $ origin: Factor w/ 3 levels "EWR","JFK","LGA": 1 3 2 2 3 1 $ dest: Factor w/ 5 levels "ATL","BQN","IAH",..: 3 3 4 2 1 5 $ air_time: int227 227 160 183 116 150
str函數(shù)可用于檢視讀取數(shù)據(jù)結(jié)構(gòu)、變量名稱等。這里同樣也只指定了一個非默認(rèn)參數(shù),其他參數(shù)全部都為默認(rèn)值。str的輸出結(jié)果由5個主要部分組成,具體說明如下。
1)data.frame代表數(shù)據(jù)集在R中的呈現(xiàn)格式,這里指的是數(shù)據(jù)框格式,讀者可以將其設(shè)想為常見的Excel格式。
2)6 obs.of 6 variables代表這個數(shù)據(jù)集有6個變量,每個變量分別有6個觀測值。
3)$ carrier與其余帶有“$”符號的函數(shù)均指變量名稱。
4)變量名稱冒號后面的Factor和int代表的是變量類型。這里分別是指因子型Factor和整數(shù)型int數(shù)據(jù)。另外還有字符型chr、邏輯型logi、浮點(diǎn)型dbl(帶有小數(shù)點(diǎn)的數(shù)字)、復(fù)雜型complex等。因子型變量的后面還列出了各個變量的因子水平,也就是擁有多少個不同的因子。比如,出發(fā)地origin后的3 levels就是表示其有3個因子水平。只是出發(fā)地是否屬于因子類型的數(shù)據(jù)還有待商榷,而read.csv默認(rèn)將所有的字符型數(shù)據(jù)都讀成了因子型。
5)數(shù)據(jù)中的實(shí)際觀測值。str函數(shù)在默認(rèn)情況下會顯示10行數(shù)據(jù)。使用str函數(shù)瀏覽導(dǎo)入的數(shù)據(jù)集可以讓用戶確定讀取的數(shù)據(jù)是否正確,數(shù)據(jù)中是否有默認(rèn)的部分、變量的種類等信息,進(jìn)而確定下一步進(jìn)行數(shù)據(jù)處理的方向。其他用來檢視數(shù)據(jù)集的函數(shù)還有head、tail、view等,另外,Rstudio中的Environment部分也可以用于查看目前工作環(huán)境中的數(shù)據(jù)框或其他類型的數(shù)據(jù)集。
前文提到過,.csv并非一定是以逗號進(jìn)行分隔。如果遇到以非逗號分隔數(shù)據(jù)值的情況,加之未指定分隔符例如,運(yùn)行read.csv讀取以Tab分隔的文件,就會出現(xiàn)下面的情況:
> flights1 <- read.csv(file = "flights1.csv") > str(object = flights1) 'data.frame': 6 obs. of1 variable: $ carrier.flight.tailnum.origin.dest.air_time: Factor w/ 6 levels "AA\t1141\tN619AA\tJFK\tMIA\t160",..: 4 6 1 2 3 5
小技巧
指定(assgin)符號“<-”的快捷鍵是“alt”加“-”(短劃線)。Rstudio快捷鍵參照表可以通過“alt+K”來查看詳細(xì)內(nèi)容。
由代碼可知,read.csv函數(shù)將所有數(shù)據(jù)都讀取到了一列中。因?yàn)榘凑漳J(rèn)的參數(shù)設(shè)置,函數(shù)會尋找逗號作為分隔列的標(biāo)準(zhǔn),若找不到逗號,則只好將所有變量都放在一列中。指定分隔符參數(shù)可以解決這個問題。將\t(tab在R中的表達(dá)方式)指定給sep參數(shù)后再次運(yùn)行read.csv讀取以Tab分隔的csv文件,代碼如下:
> flights3 <- read.csv(file = "flights1.csv", sep = "\t") > str(flights3) 'data.frame': 6 obs. of6 variables: $ carrier : Factor w/ 4 levels "AA","B6","DL",..: 4 4 1 2 3 4 $ flight: int1545 1714 1141 725 461 1696 $ tailnum : Factor w/ 6 levels "N14228","N24211",..: 1 2 4 6 5 3 $ origin: Factor w/ 3 levels "EWR","JFK","LGA": 1 3 2 2 3 1 $ dest: Factor w/ 5 levels "ATL","BQN","IAH",..: 3 3 4 2 1 5 $ air_time: int227 227 160 183 116 150
根據(jù)實(shí)際情況不同,字符型數(shù)據(jù)有時會是因子,有時不會。如果使用read.csv默認(rèn)的讀取方式,那么字符型全因子化會對后續(xù)的處理分析帶來很多麻煩。所以最好是將字符因子化關(guān)掉。stringsAsFactors參數(shù)就是這個開關(guān),示例代碼如下:
> flights_str <- read.csv(file = "flightsstrings.csv", sep = "\t", stringsAsFactors = FALSE) > str(object = flights_str) 'data.frame': 6 obs. of6 variables: $ carrier : chr"UA" "UA" "AA" "B6" ... $ flight: int1545 1714 1141 725 461 1696 $ tailnum : chr"N14228" "N24211" "N619AA" "N804JB" ... $ origin: chr"EWR" "LGA" "JFK" "JFK" ... $ dest: chr"IAH" "IAH" "MIA" "BQN" ... $ air_time: int227 227 160 183 116 150
1.1.2 read.delim/delim2——特定分隔符數(shù)據(jù)讀取
read.delim/delim2這兩個函數(shù)是專門用來處理以tab分隔數(shù)據(jù)的文件的,delim可用來讀取小數(shù)點(diǎn)是“.”的數(shù)據(jù),delim2則用來處理小數(shù)點(diǎn)是“,”的數(shù)據(jù),所以這兩個函數(shù)與read.csv/csv2唯一不同的就只是參數(shù)sep="\t"。聰明的你很可能已經(jīng)想到了如果使用這兩個函數(shù)的默認(rèn)設(shè)置來讀取以逗號分隔的數(shù)據(jù)會發(fā)生什么。函數(shù)的默認(rèn)參數(shù)會在原始數(shù)據(jù)中不斷地尋找tab分隔符,找不到的話就會如同1.1.1節(jié)里面演示的那樣,將所有變量都擠在一列里。read.delim/delim2示例代碼如下:
> read.delim function (file, header = TRUE, sep = "\t", quote = "\"", dec = ".", fill = TRUE, comment.char = "", ...) read.table(file = file, header = header, sep = sep, quote = quote, dec = dec, fill = fill, comment.char = comment.char, ...) <bytecode: 0x000000001a28a710> <environment: namespace:utils>
無論是read.csv還是read.delim,幫助文檔中的參數(shù)格式都是相同的。從上面的代碼結(jié)果中可以看出,read.delim執(zhí)行的其實(shí)是函數(shù)read.table。其實(shí)這4個函數(shù)都只是它們的母函數(shù)read.table的變形罷了。這樣做的原因有可能是因?yàn)樵赗Studio出生之前,read.csv/delim比read.table更容易記住,也有可能只是Henrik Bengtsson(utils包的筆者)覺得這樣做很酷。具體是什么原因已經(jīng)不再重要,會用這些函數(shù)才是第一要務(wù)。
1.1.3 read.table——任意分隔符數(shù)據(jù)讀取
read.table函數(shù)會將文件讀成數(shù)據(jù)框的格式,將分隔符作為區(qū)分變量的依據(jù),把不同的變量放置在不同的列中,每一行的數(shù)據(jù)都會對應(yīng)相應(yīng)的變量名稱進(jìn)行排放。表1-1簡要列出了read.table函數(shù)中主要參數(shù)的中英文對照。
表1-1 函數(shù)read.table實(shí)用參數(shù)及功能對照
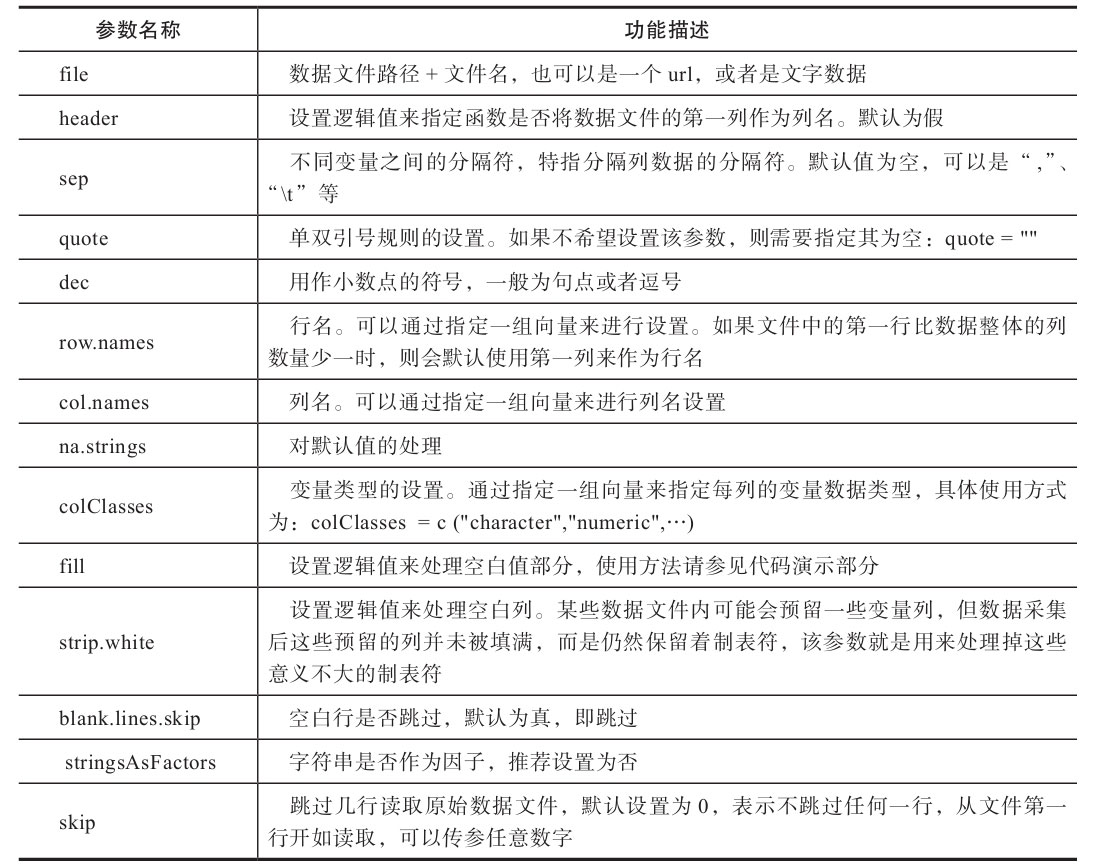
以上這些參數(shù)已足以應(yīng)付讀取日常練習(xí)所用的規(guī)整的數(shù)據(jù)文件,例如,教授布置的統(tǒng)計作業(yè)中的原始數(shù)據(jù)集,各種傳感器輸出的.csv文件等。下面的代碼及運(yùn)行結(jié)果演示非常簡單,使用read.table讀取1.1.1節(jié)中的第一個數(shù)據(jù)集,實(shí)現(xiàn)思路是每次只增加一個read.table函數(shù)中的參數(shù)。代碼如下:
> flights <- read.table(file = "flights.csv") > head(x = flights)
表1-2展示所有參數(shù)均為默認(rèn)設(shè)置的部分結(jié)果。
表1-2 read.table函數(shù)參數(shù)設(shè)置結(jié)果展示一

小提示
上面的演示代碼中使用了head函數(shù),該函數(shù)可以按照人們習(xí)慣的方式將數(shù)據(jù)框按照自上而下的方式顯示出來,而不是像str函數(shù)那用從左向右展示。一般在做初步數(shù)據(jù)檢視的時候,推薦兩個函數(shù)都運(yùn)行,作為互補(bǔ)。head方便與原始數(shù)據(jù)文檔進(jìn)行比對,而str則可以顯示所保存的數(shù)據(jù)框?qū)傩浴⒆兞款愋偷刃畔ⅰ?/p>
因?yàn)楹瘮?shù)默認(rèn)的分隔符是空白(注意不是空格),所以應(yīng)有的6個變量都被讀在一列中。且默認(rèn)的header參數(shù)是假,所以數(shù)據(jù)變量被默認(rèn)分配了一個新的變量名V1,并且應(yīng)為變量名稱的這一行變成了觀測值的第一行。將header設(shè)置為TRVE后的代碼如下:
> flights <- read.table(file = "flights.csv",header = TRUE) > head(x = flights)
表1-3中顯示的是部分結(jié)果。
表1-3 read.table函數(shù)參數(shù)設(shè)置結(jié)果展示二

指定header參數(shù)為真,分隔符sep參數(shù)為“,”后,變量名稱才得以讀取成應(yīng)有的樣子(如表1-4所示)。
> flights <- read.table(file = "flights.csv",header = TRUE,sep = ",") > head(flights)
表1-4 read.table函數(shù)參數(shù)設(shè)置結(jié)果展示三
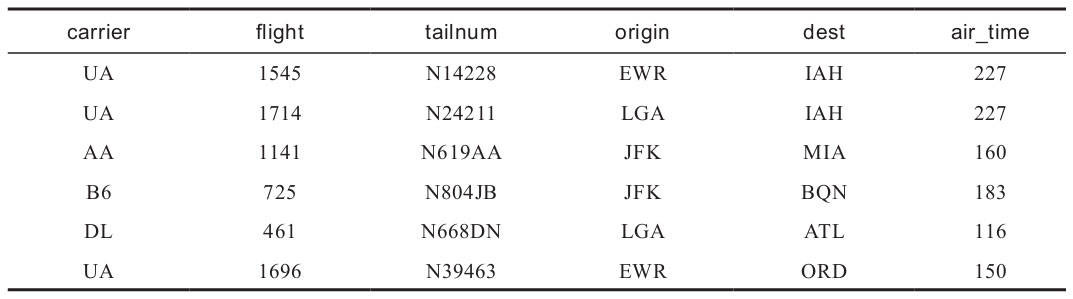
表1-4所示的數(shù)據(jù)框終于呈現(xiàn)了該有的樣子。需要注意的,是因?yàn)樽址麛?shù)據(jù)因子化的參數(shù)還是默認(rèn)設(shè)置,因此變量carrier、tailnum、origin、dest還是因子型。在實(shí)際練習(xí)或使用時,建議指定stringAsFactors=FALSE。
以上讀取的數(shù)據(jù)集都是規(guī)整的數(shù)據(jù)集,即每一行數(shù)據(jù)都有相同的觀測值。不過在實(shí)際生活中,原始數(shù)據(jù)難免會存在空白行、空白值、默認(rèn)值,或者某一行數(shù)據(jù)存在多余觀測值卻沒有與之對應(yīng)的變量名稱,抑或元數(shù)據(jù)和原始數(shù)據(jù)在同一個文件中等各種問題。這里暫且稱這些問題數(shù)據(jù)驚喜集為不規(guī)則數(shù)據(jù)集,簡單說就是,實(shí)際列的個數(shù)多于列名的個數(shù)。read.table函數(shù)為這些準(zhǔn)備了相應(yīng)的參數(shù)。
1.空白行
表1-1中介紹過read.table對于空白行的默認(rèn)處理是跳過,這可以滿足大部分常見數(shù)據(jù)的情況。不過在某些特殊情況下,例如,一個數(shù)據(jù)文件中同時存在兩個或兩個以上的數(shù)據(jù)集,那么保留空白行可能會有助于后續(xù)的數(shù)據(jù)處理。表1-5演示的就是一個比較特殊的例子。空白行的上部是元數(shù)據(jù),也即解釋數(shù)據(jù)的數(shù)據(jù),這里演示的是航空公司的縮寫和全名的對照。空白行的下部是數(shù)據(jù)的主體部分,航班號、起始地縮寫、起飛時間。這里保留空白行可有助于區(qū)分?jǐn)?shù)據(jù)的不同部分。
表1-5 特殊類型文本數(shù)據(jù)文檔

保留空白行的代碼如下所示:
> airlines <- read.table(file = "airlines.csv", header = TRUE, sep = "\t", blank.lines.skip = FALSE, stringsAsFactors = FALSE) > head(airlines, n = 8)
指定空白行保留的參數(shù)后,數(shù)據(jù)被成功讀進(jìn)R(表1-6)。
表1-6 read.table函數(shù)參數(shù)設(shè)置結(jié)果展示四

如此一來,不同的數(shù)據(jù)集就可以很容易地進(jìn)行切割并歸集到新的數(shù)據(jù)集中。可是,另外一個問題又出現(xiàn)了,函數(shù)按照第一部分的兩列變量把后續(xù)的所有數(shù)據(jù)也都寫入了兩列。這是因?yàn)閞ead.table會掃描文件中前五行的數(shù)據(jù)(包括變量名稱)并以此為標(biāo)準(zhǔn)來確定變量數(shù),airlines.csv中開始的五行數(shù)據(jù)都只有兩列,所以后續(xù)的數(shù)據(jù)也都強(qiáng)制讀取成兩列。如果數(shù)據(jù)的第2~5行中存在任何一行擁有多于前面一行或幾行的數(shù)據(jù)值,那么函數(shù)就會報錯提示第一行沒有相應(yīng)數(shù)量的值。這種情況可以根據(jù)實(shí)際數(shù)據(jù)文件內(nèi)容,用兩種方式來處理,具體如下。
1)如果文件中開始的部分是暫時不需要的元數(shù)據(jù),那么可以使用skip函數(shù)跳過相應(yīng)的行數(shù),只讀取感興趣的數(shù)據(jù)。
2)如果文件內(nèi)容是一個整體,只是若干行具數(shù)據(jù)有額外的觀測值。那么可以通過調(diào)整參數(shù)col.names或fill和header進(jìn)行處理。
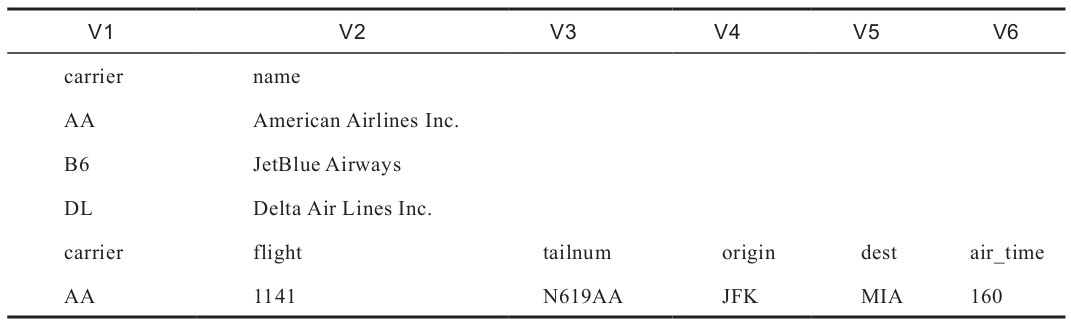
第一種情況比較容易,讀者可以自行測試,在此略過。第二種情況需要知道數(shù)據(jù)中觀測值個數(shù)的最大值,以用來補(bǔ)齊變量個數(shù)。因?yàn)橐呀?jīng)知道airlines文件的第二部分擁有6個變量,所以下面就來演示如何將6個變量名稱指定成新的變量名(表1-7),代碼如下:
> airlines <- read.table(file = "airlines.csv", header = FALSE, sep = "\t", stringsAsFactors = FALSE, col.names = paste0("V",1:6), blank.lines.skip = FALSE)
> head(airlines)
演示結(jié)果如表1-7所示。
表1-7 read.table函數(shù)參數(shù)設(shè)置結(jié)果展示五

小技巧:
另外一個獲取不規(guī)則數(shù)據(jù)集中所需變量個數(shù)的方法是利用報錯信息。當(dāng)不指定col.names參數(shù),且原始數(shù)據(jù)的第2~5行中任一行有多于第一行的數(shù)據(jù)時,read.table會報錯提示Error in scan(file=file,what=what,sep=sep,quote=quote,dec=dec,:line 1 did not have X elements,X即所需要的手動指定的變量個數(shù)。
這里使用paste0來創(chuàng)建新的變量名稱。paste0可以理解為膠水函數(shù),用于將需要的字符串粘合在一起。這里演示的意思是創(chuàng)建6個以V開頭,從V1到V6的字符串作為變量名。這種處理方式足以應(yīng)付平時練習(xí)用的小型數(shù)據(jù)集(比如,只有幾行到幾十行數(shù)據(jù)的數(shù)據(jù)集)。但是在處理實(shí)際工作中成百上千行的數(shù)據(jù)時,這種手動指定變量個數(shù)的方法就顯得笨拙而低效了。下面的代碼演示了如何實(shí)現(xiàn)自動檢測數(shù)據(jù)集所需的變量數(shù):
> number_of_col <- max(count.fields("airlines.csv",sep = "\t"))
> airlines <- read.table(file = "airlines.csv", header = FALSE, sep = "\t", stringsAsFactors = FALSE, col.names = paste0("V",seq_len(number_of_col)), blank.lines.skip = FALSE)
> head(airlines)
部分結(jié)果展示如表1-8所示。
表1-8 read.table函數(shù)參數(shù)設(shè)置結(jié)果展示六

count.fields/max/seq_len這三個函數(shù)的配合使用實(shí)現(xiàn)了如下功能。
count.fields用于自動檢測數(shù)據(jù)集中每一行數(shù)據(jù)的觀測值個數(shù),max用于找出count.fields輸入結(jié)果中的最大值,seq_len以最大值為參照生成1到最大值的整數(shù)序列,膠水函數(shù)paste0用于定義變量名稱。
因?yàn)镽基于向量計算的特性,因此這種函數(shù)之間簡單的配合使用很常見也很有效。所以希望小伙伴們在以后的練習(xí)或?qū)嶋H工作中,多思考,盡量使用這樣的組合來提高代碼的效率、簡潔性和可重復(fù)性。
使用參數(shù)fill和header也可以讀取不規(guī)則數(shù)據(jù)集。需要注意的是,采用這種方法是有前提條件的,即原始數(shù)據(jù)第2~5行實(shí)際列的個數(shù)應(yīng)大于列名。代碼如下:
> flights_uneven <- read.table("airlines.csv", header = FALSE, sep = "\t", stringsAsFactors = FALSE, fill = TRUE)
> head(flights_uneven)
上述代碼的演示結(jié)果如表1-9所示。
表1-9 read.table函數(shù)參數(shù)設(shè)置結(jié)果展示七
2.默認(rèn)值、空白
一個數(shù)據(jù)集里出現(xiàn)默認(rèn)值(NA)或空白(“”)的情況十分常見,兩者之間的區(qū)別需要根據(jù)不同的實(shí)際情況來確定。理論上來講,默認(rèn)值仍是數(shù)據(jù)觀測值的一種,雖然在原始數(shù)據(jù)中其可能與空白一樣沒有顯示,但是它可以通過其他手段來進(jìn)行補(bǔ)齊。而空白有可能并不是數(shù)據(jù),比如在上面的演示中,V3至v6列,1~5行都是空白,這些空白不屬于任何實(shí)際數(shù)據(jù)變量,是真正的空白,因而不能說這些空白是默認(rèn)值。默認(rèn)值和空白的處理完全可以獨(dú)立成書,因?yàn)橄嚓P(guān)內(nèi)容已經(jīng)超出了本書的范圍,所以這里不再過多討論。下面只演示在導(dǎo)入數(shù)據(jù)的過程中,如何進(jìn)行簡單的默認(rèn)值、空白預(yù)處理,代碼如下:
> flights_uneven <- read.table(file = "flights_uneven.csv", header = FALSE, sep = "\t", stringsAsFactors = FALSE, fill = TRUE, na.strings = c(""))
> head(flights_uneven)
表1-10中展示了處理后的部分?jǐn)?shù)據(jù)值。
表1-10 read.table函數(shù)參數(shù)設(shè)置結(jié)果展示八
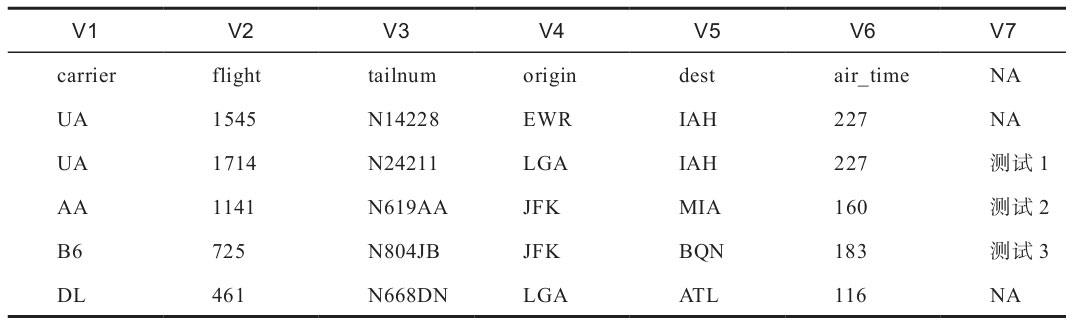
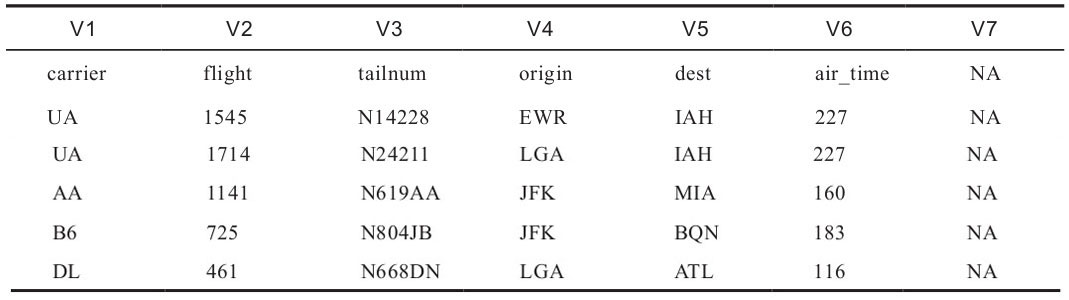
第七列中的數(shù)據(jù)在指定將空白替換成“NA”之后,原有的空白位置被寫入了“NA”,也就是說第七列的空白屬于數(shù)據(jù)的一部分。根據(jù)實(shí)際情況,也可以將多余的數(shù)據(jù)部分或全部替換成“NA”(如表1-11所示),以方便后續(xù)的處理及分析,代碼如下:
> flights_uneven <- read.table("flights_uneven.csv",sep = "\t", stringsAsFactors = FALSE, fill = TRUE,header = FALSE, na.strings = c(paste0("測試",1:3),""))
> head(flights_uneven)
替換結(jié)果如表1-11所示。
表1-11 read.table函數(shù)參數(shù)設(shè)置結(jié)果展示九
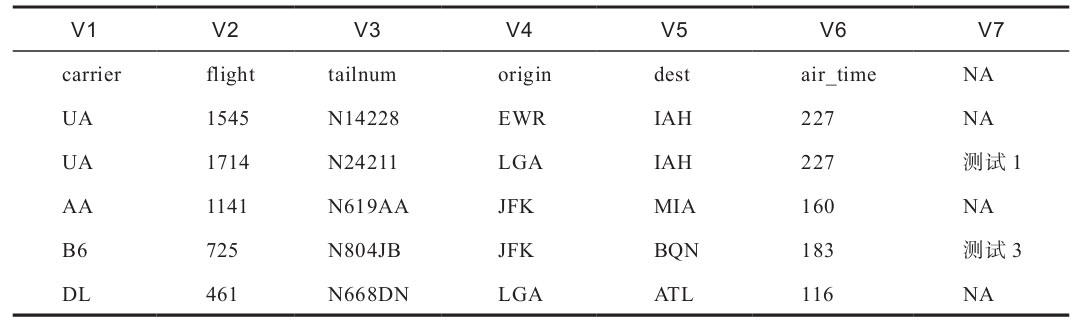
當(dāng)數(shù)據(jù)集行數(shù)較多,無法輕易地鑒別出某一列到底有多少個觀測值需要賦值為“NA”的時候,可以配合unique函數(shù)進(jìn)行處理。處理的思路是先將數(shù)據(jù)讀取到R中,然后使用unique函數(shù)找到指定列中的非重復(fù)觀測值,選取指定觀測值并保存到一個向量內(nèi),然后將向量指定給na.strings參數(shù)來進(jìn)行替換,代碼如下:
> flights_uneven <- read.table("flights_uneven.csv",sep = "\t", string-sAsFactors = FALSE, fill = TRUE, header = FALSE)
> replace <- unique(flights_uneven$V7)
replace
[1] """測試1" "測試2" "測試3"
> flights_uneven <- read.table("flights_uneven.csv",sep = "\t", stringsAsFactors = FALSE, fill = TRUE,header = FALSE, na.strings = c(replace[c(1,3)]))
> head(flights_uneven)
替換結(jié)果如表1-12所示。
表1-12 read.table函數(shù)參數(shù)設(shè)置結(jié)果展示十
第一次讀取數(shù)據(jù)是為了獲得需要替換的觀測值,第二次讀取則是將需要替換成“NA”的觀測值指定給相應(yīng)參數(shù)。因?yàn)閞eplace是一個字符串向量,所以可以使用“[”按位置選擇其中的值,當(dāng)然也可以不選擇任何值,直接全部替換。
小知識
“[”是baseR中Extract的一種,在R的使用過程中,這是必須掌握和理解的函數(shù)之一。
- Python程序設(shè)計教程(第2版)
- 從零開始:數(shù)字圖像處理的編程基礎(chǔ)與應(yīng)用
- Instant Apache Stanbol
- Vue.js前端開發(fā)基礎(chǔ)與項(xiàng)目實(shí)戰(zhàn)
- Cross-platform Desktop Application Development:Electron,Node,NW.js,and React
- Spring Cloud、Nginx高并發(fā)核心編程
- Scratch 3游戲與人工智能編程完全自學(xué)教程
- HTML5+CSS3網(wǎng)頁設(shè)計
- Python編程:從入門到實(shí)踐
- Linux Shell核心編程指南
- Red Hat Enterprise Linux Troubleshooting Guide
- Visual Basic程序設(shè)計(第三版)
- 并行編程方法與優(yōu)化實(shí)踐
- Java Web應(yīng)用開發(fā)給力起飛
- 從零開始學(xué)算法:基于Python