- R數據科學實戰:工具詳解與案例分析
- 劉健 鄔書豪
- 804字
- 2019-08-01 11:34:29
2.1 基本概念
“臟”數據沒有任何標準,只要是不能滿足分析要求的數據集都將打上“臟”的標簽。所以弄清楚與之相對的“干凈”數據可以使我們更容易理解數據清理的概念。目前國際上公認的“干凈”數據可以總結為如下3點 。
。
1)屬性相同的變量自成一列。
2)單一觀測自成一行。
3)每個數據值必須獨立存在。
表2-1中顯示的數據不符合第一條原則,因為男、女都屬于性別,所以可以歸為一個變量,歸為一個變量后如表2-2中所示。但表2-2中顯示的數據不符合第三條原則,因為體重和年齡兩個變量放在了同一列中,雖然用反斜杠分隔后,人類按常識很容易理解,但計算機并不會懂,其只會將兩列本來是數字類型的數據當成是字符串來處理。表2-3中展示了一個三條原則都不滿足的樣本數據集,在完成清理之前,計算機無法對表2-3中的數據進行任何有效的數據分析。
表2-1 “臟”數據樣本一

表2-2 “臟”數據樣本二

表2-3 “臟”數據樣本

表2-4中列出了清理后的數據集。對單一數據清理的第一個指導原則就是,按照上文介紹的三點將數據集清理成相應的形式。第二個原則需要按照實際需求進行,表2-5中的數據集是將“寬”數據(一般指多個同類或不同類型變量并存)轉換成了“長”數據(同類型變量單獨成列)。“寬”數據更符合人們日常對Excel格式數據的理解,而“長”數據對計算機來講則更易進行數據存儲和計算,在R環境中,計算長數據的速度優于“寬”數據。將表2-4中的數據轉換成表2-5的形式只需一個函數gather,相關內容詳見2.3節。
表2-4 “干凈”數據樣本一
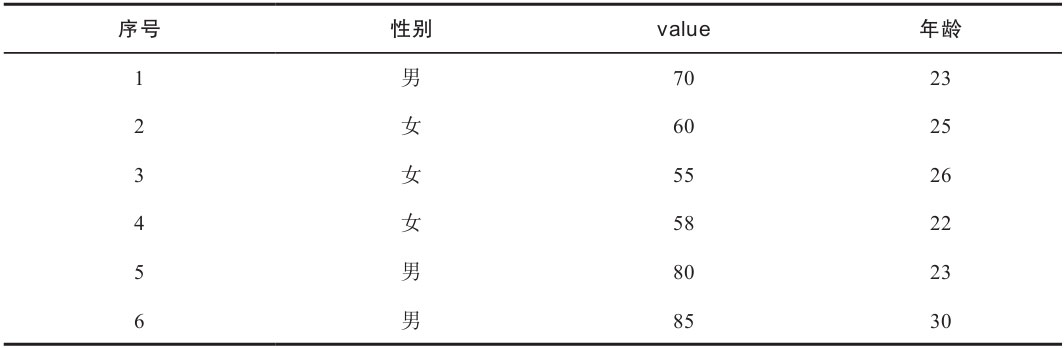
表2-5 “干凈”數據樣本二
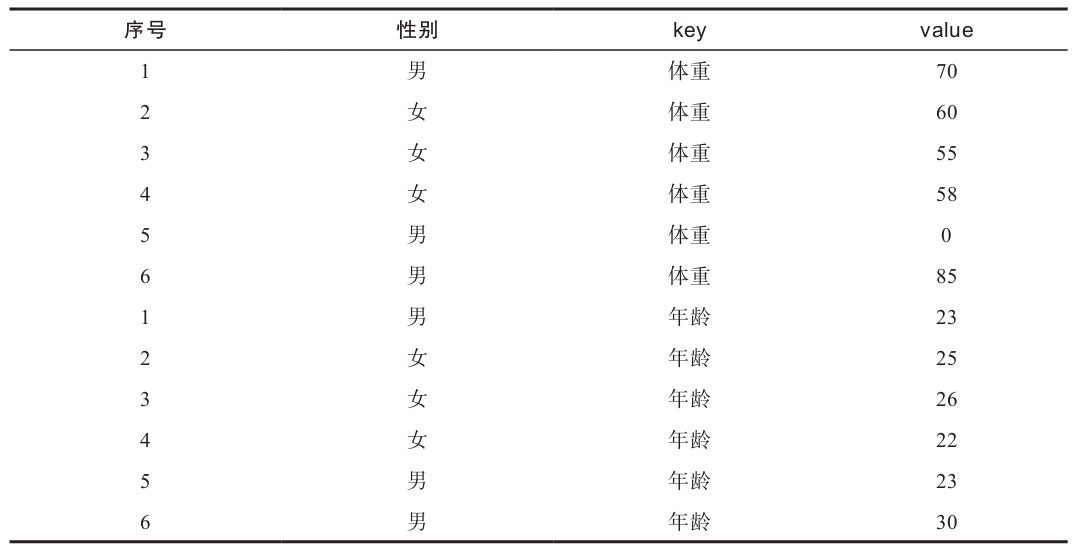
數據清理的第三個指導原則同樣需要視情況而定,不同來源的數據應單獨成表,獨立存在。比如元數據(解釋變量名稱或數據背景的數據,英文為metadata)與原始應數據同時存在一個文件或一個工作表中(參考第1章不規則數據讀取)。簡單來說,元數據通常會包含坐標、指標的具體含義等解釋性信息,這類信息不應與原始數據本身同時存在一個數據集中,而應單獨成為一個數據集,只在需要解釋原始數據本身時才調用元數據。
- Web前端開發技術:HTML、CSS、JavaScript(第3版)
- jQuery Mobile Web Development Essentials(Third Edition)
- 數據庫程序員面試筆試真題與解析
- Building a Home Security System with Raspberry Pi
- Python金融數據分析
- Java Web開發技術教程
- Android開發案例教程與項目實戰(在線實驗+在線自測)
- Java并發編程之美
- SQL Server 2016 從入門到實戰(視頻教學版)
- 奔跑吧 Linux內核
- Java Web動態網站開發(第2版·微課版)
- LabVIEW入門與實戰開發100例(第4版)
- HTML5+CSS+JavaScript深入學習實錄
- C/C++語言程序開發參考手冊
- 算法(第4版)