- 數(shù)據(jù)挖掘方法及天體光譜挖掘技術(shù)
- 趙旭俊著
- 4604字
- 2018-12-27 18:58:38
1.1 數(shù)據(jù)挖掘
數(shù)據(jù)挖掘(Data Mining)是一個(gè)從大量的數(shù)據(jù)中發(fā)現(xiàn)潛在知識(shí)的過程,是半自動(dòng)或自動(dòng)地從海量數(shù)據(jù)中發(fā)現(xiàn)模式、相關(guān)性、變化、反常規(guī)律性的過程。根據(jù)挖掘任務(wù)劃分,數(shù)據(jù)挖掘主要發(fā)現(xiàn)五類知識(shí):廣義型知識(shí)(Generalization)——根據(jù)數(shù)據(jù)的微觀特性發(fā)現(xiàn)其表征的、帶有普遍性的、較高層次概念的、微觀或宏觀的知識(shí);分類型知識(shí)(Classification)——反映同類事物共同性質(zhì)的特征知識(shí)和不同事物之間差異型的特征知識(shí),用于描述數(shù)據(jù)的匯聚模式或根據(jù)對(duì)象的屬性區(qū)分其所屬類別;關(guān)聯(lián)型知識(shí)(Association)——反映一個(gè)事件和其他事件之間依賴或關(guān)聯(lián)的知識(shí),又稱為依賴(Dependency)關(guān)系,這類知識(shí)可用于數(shù)據(jù)庫(kù)的歸一化、查詢優(yōu)化等;預(yù)測(cè)型知識(shí)(Prediction)——通過時(shí)間序列型數(shù)據(jù),由歷史的和當(dāng)前的數(shù)據(jù)去預(yù)測(cè)未來的情況,它實(shí)際上是一種以時(shí)間為關(guān)鍵屬性的關(guān)聯(lián)知識(shí);偏差型知識(shí)(Deviation)——離群數(shù)據(jù)(孤立點(diǎn))的挖掘(Outliers Mining),通過分析標(biāo)準(zhǔn)類外的特例、數(shù)據(jù)聚類外的異常值、實(shí)際觀測(cè)值和系統(tǒng)預(yù)測(cè)值間的顯著差別,來對(duì)差異和極端特例進(jìn)行描述。
1.1.1 產(chǎn)生和定義
隨著數(shù)據(jù)庫(kù)和計(jì)算機(jī)網(wǎng)絡(luò)的廣泛應(yīng)用,人們所擁有的數(shù)據(jù)量急劇增大,海量數(shù)據(jù)層出不窮。先進(jìn)的現(xiàn)代科學(xué)觀測(cè)儀器的使用造成每天都要產(chǎn)生巨量的數(shù)據(jù),如我國(guó)建成的LAMOST望遠(yuǎn)鏡,每晚將有2萬(wàn)~4萬(wàn)條光譜需要進(jìn)行自動(dòng)分類識(shí)別及參數(shù)測(cè)量。顯然,大量信息在給人們帶來方便的同時(shí)也帶來了一系列問題,如信息量過大,超過了人們掌握、消化的能力;一些信息的真?zhèn)坞y辨,從而給信息的正確運(yùn)用帶來了困難;信息組織形式的不一致性導(dǎo)致難以對(duì)信息進(jìn)行有效統(tǒng)一處理等,這種變化使得傳統(tǒng)的數(shù)據(jù)庫(kù)技術(shù)和數(shù)據(jù)處理手段已經(jīng)不能滿足要求。如何在海量數(shù)據(jù)中獲取有價(jià)值的信息和知識(shí)成了信息系統(tǒng)的核心問題之一。數(shù)據(jù)挖掘正是為了解決這一問題,并針對(duì)大規(guī)模數(shù)據(jù)的分析處理而出現(xiàn)的。
數(shù)據(jù)挖掘就是從大量原始數(shù)據(jù)中提取人們感興趣的、隱含的、尚未被發(fā)現(xiàn)的、有用的信息和知識(shí),使它們可以有利于為專家進(jìn)行決策提供技術(shù)支持,其提取的知識(shí)可以表示為概念、規(guī)則、規(guī)律、模式等形式。數(shù)據(jù)挖掘是當(dāng)今數(shù)據(jù)庫(kù)和人工智能相互結(jié)合的最前沿和極富應(yīng)用前景的研究領(lǐng)域,已引起了國(guó)內(nèi)外眾多學(xué)者和業(yè)界的高度重視,他們已對(duì)數(shù)據(jù)挖掘的方法論、理論和工具開展了廣泛深入的研究工作。由于數(shù)據(jù)挖掘獲取的信息和知識(shí)可以廣泛地應(yīng)用于生物醫(yī)學(xué)和DNA分析、銀行與金融機(jī)構(gòu)、零售業(yè)、電信業(yè)、商務(wù)管理、市場(chǎng)分析和企業(yè)決策管理等領(lǐng)域,所以數(shù)據(jù)挖掘技術(shù)引起了信息產(chǎn)業(yè)界的極大關(guān)注。目前,國(guó)內(nèi)外學(xué)者已研究和開發(fā)出了一些數(shù)據(jù)挖掘系統(tǒng),比較有代表性的通用數(shù)據(jù)挖掘系統(tǒng)有IBM公司的Almaden研究中心開發(fā)的Quest、加拿大Simon Fraser大學(xué)開發(fā)的DBMiner、SGI公司和美國(guó)Standford大學(xué)聯(lián)合開發(fā)的MineSet、南京大學(xué)開發(fā)的Knight原型工具等。一個(gè)典型的數(shù)據(jù)挖掘系統(tǒng)可以由以下幾個(gè)主要成分組成(如圖1-1所示)。
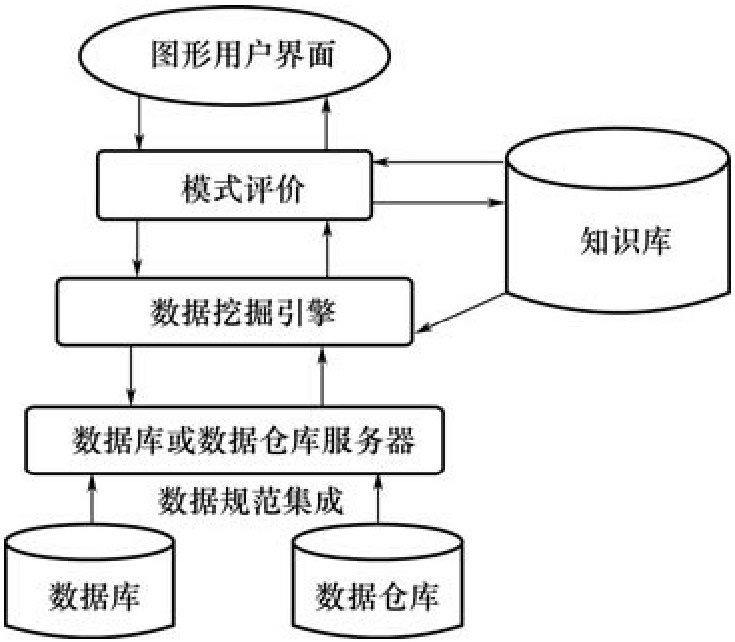
圖1-1 數(shù)據(jù)挖掘系統(tǒng)的組成圖
數(shù)據(jù)庫(kù)、數(shù)據(jù)倉(cāng)庫(kù)或其他信息庫(kù):這是一個(gè)或一組數(shù)據(jù)庫(kù)、數(shù)據(jù)倉(cāng)庫(kù)、電子表格或其他類型的信息庫(kù)。可以在數(shù)據(jù)庫(kù)上進(jìn)行數(shù)據(jù)的清理和集成。
數(shù)據(jù)庫(kù)或數(shù)據(jù)倉(cāng)庫(kù)服務(wù)器:根據(jù)用戶的數(shù)據(jù)挖掘請(qǐng)求,數(shù)據(jù)庫(kù)或數(shù)據(jù)倉(cāng)庫(kù)服務(wù)器負(fù)責(zé)提取相關(guān)數(shù)據(jù)。
知識(shí)庫(kù):這是領(lǐng)域知識(shí),用于指導(dǎo)搜索或評(píng)估結(jié)果模式的興趣度。
數(shù)據(jù)挖掘引擎:這是數(shù)據(jù)挖掘系統(tǒng)的基本部分,由一組功能模塊組成,用于特征化、關(guān)聯(lián)、分類、聚類分析,以及演變和偏差分析。
模式評(píng)價(jià):通常,此成分使用興趣度度量,并與數(shù)據(jù)挖掘引擎模塊交互,以便將搜索聚焦在有趣的模式上。
圖形用戶界面:本模塊在用戶和數(shù)據(jù)挖掘系統(tǒng)之間進(jìn)行通信,允許用戶與系統(tǒng)交互,制定數(shù)據(jù)挖掘查詢?nèi)蝿?wù),提供信息,幫助搜索聚焦,根據(jù)數(shù)據(jù)挖掘的中間結(jié)果進(jìn)行探索式數(shù)據(jù)挖掘。
1.1.2 挖掘的過程
數(shù)據(jù)挖掘的一般過程可用圖1-2進(jìn)行描述。
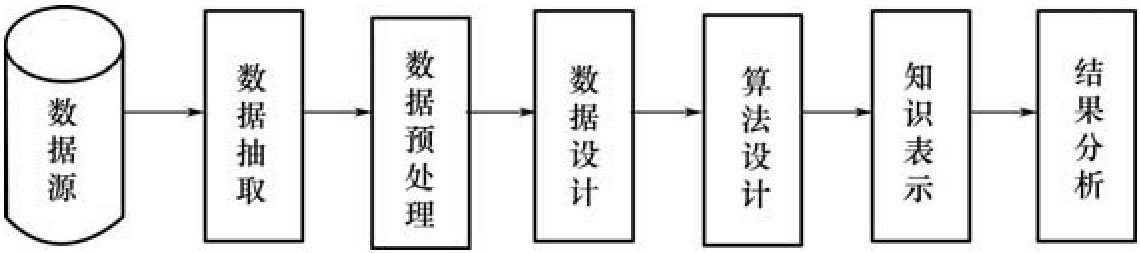
圖1-2 數(shù)據(jù)挖掘的一般過程
1.數(shù)據(jù)抽取
大多數(shù)時(shí)候,與數(shù)據(jù)挖掘任務(wù)有關(guān)的數(shù)據(jù)是存儲(chǔ)在應(yīng)用數(shù)據(jù)庫(kù)中的,這些數(shù)據(jù)庫(kù)往往是為應(yīng)用的目的而建立的,通常不能直接運(yùn)行數(shù)據(jù)挖掘算法,而需要進(jìn)行必要的抽取和格式的整理工作。
2.數(shù)據(jù)預(yù)處理
數(shù)據(jù)預(yù)處理是指處理掉一些噪聲數(shù)據(jù)(冗余的、不一致的)或添補(bǔ)一些丟失的數(shù)據(jù),以便使被挖掘的數(shù)據(jù)保持完整和干凈。
3.數(shù)據(jù)設(shè)計(jì)
數(shù)據(jù)設(shè)計(jì)是指去掉一些無(wú)關(guān)的屬性或?qū)?shù)據(jù)量過大的數(shù)據(jù)庫(kù)進(jìn)行抽樣等。
4.算法設(shè)計(jì)
算法設(shè)計(jì)主要是指針對(duì)特定的挖掘任務(wù),設(shè)計(jì)挖掘方法模型與高效的算法和相應(yīng)的數(shù)據(jù)結(jié)構(gòu)。
5.知識(shí)表示
知識(shí)表示是指從數(shù)據(jù)庫(kù)或數(shù)據(jù)倉(cāng)庫(kù)中獲取特定的知識(shí)類型,如分類、關(guān)聯(lián)規(guī)則、聚類和序列模式等。
6.結(jié)果分析
結(jié)果分析是指由領(lǐng)域?qū)<遥―omain Expert)分析結(jié)果的可靠性、合理性及可用性,有時(shí)還需要對(duì)結(jié)果進(jìn)行可視化處理。
從圖1-2 可以看出,數(shù)據(jù)挖掘的核心步驟是算法設(shè)計(jì),一個(gè)好的數(shù)據(jù)挖掘模型、一個(gè)好的算法(速度快、伸縮性好、結(jié)果容易使用且符合用戶的特定需求)是影響數(shù)據(jù)挖掘效率的最重要的因素。
1.1.3 挖掘的任務(wù)
數(shù)據(jù)挖掘的任務(wù)是從大量數(shù)據(jù)中發(fā)現(xiàn)有趣模式。模式是用語(yǔ)言L來表示的一個(gè)表達(dá)式E,它可用來描述數(shù)據(jù)集DS中數(shù)據(jù)的特性。E所描述的數(shù)據(jù)是DS的一個(gè)子集。在實(shí)際應(yīng)用中,數(shù)據(jù)挖掘模式可分為分類和回歸模式、關(guān)聯(lián)規(guī)則模式、聚類模式、孤立點(diǎn)模式、時(shí)間序列模式等。
分類(Classification)是找出描述并區(qū)分?jǐn)?shù)據(jù)類或概念的模型(或函數(shù))的過程。數(shù)據(jù)分類通常可以分為以下兩步。
第一步,建立一個(gè)模型,描述預(yù)定的數(shù)據(jù)類集或概念集。可以通過分析由屬性描述的數(shù)據(jù)庫(kù)元組來構(gòu)造模型,其中數(shù)據(jù)庫(kù)元組是指被分析的樣本、實(shí)例和對(duì)象。
第二步,使用模型進(jìn)行分類。
常用的數(shù)據(jù)分類方法有判定樹(Decision Tree)、貝葉斯分類(Bayesian)、神經(jīng)網(wǎng)絡(luò)(Neural Network)、K-最近鄰分類、基于案例的推理(Case-based Reasoning,CBR)、概念格方法、粗糙集方法和模糊集方法。對(duì)于分類來說,其目的主要是提高分類的準(zhǔn)確率與效率。
關(guān)聯(lián)規(guī)則模式由Agrawal、Imielinski、Swami于1993年提出,它是描述在一個(gè)事務(wù)(項(xiàng)目)中物品(交易)同時(shí)出現(xiàn)的規(guī)律的知識(shí)模式,即通過量化的數(shù)字描述物品甲的出現(xiàn)對(duì)物品乙的出現(xiàn)的影響程度。關(guān)聯(lián)規(guī)則模式的提取通常可以分為兩步:找出滿足用戶的最小支持度的頻繁項(xiàng)目集;提取出滿足用戶的最小置信度的關(guān)聯(lián)規(guī)則。從大量商務(wù)事務(wù)記錄中發(fā)現(xiàn)有趣的關(guān)聯(lián)聯(lián)系,可以幫助許多商務(wù)決策的制定,如市場(chǎng)規(guī)劃、廣告規(guī)劃、分類設(shè)計(jì)、交叉購(gòu)物和賤賣分析等。又如,在現(xiàn)今中國(guó)貸款購(gòu)買住房和汽車的顧客中,調(diào)查發(fā)現(xiàn)70%的人的年齡在35~45 歲之間,這樣銀行就可以通過分析這些客戶的特點(diǎn)來調(diào)整一些相應(yīng)的政策,以便將貸款發(fā)放給這類客戶群體。自從Agrawal等提出從大型數(shù)據(jù)庫(kù)中挖掘關(guān)聯(lián)規(guī)則以來,關(guān)聯(lián)規(guī)則的挖掘已廣泛地應(yīng)用在電子通信行業(yè)、信用卡公司、股票交易所、銀行和超級(jí)市場(chǎng)等場(chǎng)合。目前,國(guó)內(nèi)外研究者正在從多種角度、多種渠道研究基于各種數(shù)據(jù)模型的關(guān)聯(lián)規(guī)則的提取。
聚類(Clustering)分析是指根據(jù)對(duì)象屬性標(biāo)識(shí)對(duì)象集的類(組、簇)的過程。將對(duì)象按某種聚類準(zhǔn)則聚類后,可以使對(duì)象組內(nèi)的相異性最小、組間的相異性最大。例如,在保險(xiǎn)業(yè)上,聚類能幫助保險(xiǎn)公司分析投保人群的特征,以加大對(duì)這些客戶群體的投保率。
孤立點(diǎn)(Outlier)分析是指挖掘出與數(shù)據(jù)的一般行為或模型不一致的數(shù)據(jù)對(duì)象的過程。例如,孤立點(diǎn)分析通過監(jiān)測(cè)一個(gè)給定賬號(hào)與正常的付費(fèi)的比較,以付款數(shù)額特別大來發(fā)現(xiàn)信用卡的欺騙使用。
時(shí)間序列(Timer Serial)分析是指把數(shù)據(jù)之間的關(guān)聯(lián)性與時(shí)間聯(lián)系起來,根據(jù)數(shù)據(jù)隨時(shí)間變化的趨勢(shì)預(yù)測(cè)未來的相關(guān)數(shù)值。
1.1.4 挖掘的分類
數(shù)據(jù)挖掘可以從很多不同的角度進(jìn)行分類。
(1)根據(jù)挖掘的數(shù)據(jù)庫(kù)類型,數(shù)據(jù)挖掘可分為關(guān)系數(shù)據(jù)庫(kù)挖掘、空間數(shù)據(jù)庫(kù)挖掘、時(shí)間數(shù)據(jù)庫(kù)挖掘、文本數(shù)據(jù)庫(kù)挖掘和多媒體數(shù)據(jù)庫(kù)挖掘。
(2)根據(jù)發(fā)現(xiàn)知識(shí)的種類不同,數(shù)據(jù)挖掘可分為分類規(guī)則挖掘、聚類規(guī)則挖掘、關(guān)聯(lián)規(guī)則挖掘和序列模式挖掘。
(3)根據(jù)挖掘使用技術(shù)的不同,數(shù)據(jù)挖掘可分為決策樹、貝葉斯網(wǎng)絡(luò)(Bayesian Networks)、模糊集、粗糙集、遺傳算法和概念格。
1.1.5 面臨的主要問題
目前,數(shù)據(jù)挖掘面臨的主要問題有三大類:挖掘方法和用戶交互的問題、性能問題和存儲(chǔ)數(shù)據(jù)的數(shù)據(jù)庫(kù)類型具有多樣性的問題。
1.挖掘方法和用戶交互的問題
這一問題反映了所挖掘的知識(shí)類型、在多粒度上挖掘知識(shí)的能力、領(lǐng)域知識(shí)的使用、特定的挖掘和知識(shí)顯示。由于不同的用戶可能對(duì)不同類型的知識(shí)感興趣,所以數(shù)據(jù)挖掘系統(tǒng)應(yīng)當(dāng)覆蓋范圍很廣的數(shù)據(jù)分析和知識(shí)發(fā)現(xiàn)任務(wù),并且用戶可以和數(shù)據(jù)挖掘系統(tǒng)交互,以不同的粒度和從不同的角度觀察數(shù)據(jù)和發(fā)現(xiàn)模式;發(fā)現(xiàn)的知識(shí)應(yīng)易于理解,能夠直接被人們使用。
2.性能問題
這一問題包括數(shù)據(jù)挖掘算法的有效性、可伸縮性和并行處理。為了有效地從數(shù)據(jù)庫(kù)中提取信息,數(shù)據(jù)挖掘算法必須是有效的和可伸縮的,即對(duì)于大型數(shù)據(jù)庫(kù)來說,數(shù)據(jù)挖掘算法的運(yùn)行時(shí)間必須是可預(yù)計(jì)的和可接受的,這是促使開發(fā)并行和分布式數(shù)據(jù)挖掘算法的因素。此外,當(dāng)數(shù)據(jù)庫(kù)更新時(shí),不必重新挖掘全部數(shù)據(jù),只要進(jìn)行知識(shí)更新,修正和加強(qiáng)已經(jīng)發(fā)現(xiàn)的知識(shí)即可。
3.存儲(chǔ)數(shù)據(jù)的數(shù)據(jù)庫(kù)類型具有多樣性的問題
這一問題包括關(guān)系的、復(fù)雜的數(shù)據(jù)庫(kù)處理和在異種數(shù)據(jù)庫(kù)之間挖掘信息。目前,有些數(shù)據(jù)庫(kù)可能包含復(fù)雜的數(shù)據(jù)對(duì)象、超文本和多媒體數(shù)據(jù)、空間數(shù)據(jù)、時(shí)間數(shù)據(jù)或事務(wù)數(shù)據(jù),由于數(shù)據(jù)類型的多樣性和數(shù)據(jù)挖掘的目標(biāo)不同,所以指望一個(gè)系統(tǒng)挖掘所有類型的數(shù)據(jù)是不現(xiàn)實(shí)的。從具有不同數(shù)據(jù)語(yǔ)義的,結(jié)構(gòu)化的、半結(jié)構(gòu)化的和非結(jié)構(gòu)化的數(shù)據(jù)源來發(fā)現(xiàn)知識(shí),對(duì)數(shù)據(jù)挖掘提出了巨大挑戰(zhàn)。
以上問題是數(shù)據(jù)挖掘技術(shù)未來發(fā)展的主要需求和挑戰(zhàn)。在近年來的數(shù)據(jù)挖掘的研究和開發(fā)中,一些挑戰(zhàn)業(yè)已受到一定程度的關(guān)注,并考慮到了各種需求,而另外一些仍處于研究階段。
1.1.6 主要應(yīng)用
數(shù)據(jù)挖掘的研究方興未艾,具有非常廣闊的前景。面向?qū)ο髷?shù)據(jù)庫(kù)、分布式數(shù)據(jù)庫(kù)、文本數(shù)據(jù)庫(kù)等的數(shù)據(jù)挖掘;貝葉斯網(wǎng)的興起;面向多策略和合作的發(fā)現(xiàn)系統(tǒng);結(jié)合多媒體技術(shù)的應(yīng)用等都是新的研究方向。數(shù)據(jù)挖掘原型系統(tǒng)和商業(yè)軟件已開始在多個(gè)方面得到應(yīng)用。
(1)客戶分析:在銀行信用卡和保險(xiǎn)業(yè)中,確定有良好信譽(yù)和無(wú)不良傾向的客戶是經(jīng)營(yíng)成功與否的關(guān)鍵。數(shù)據(jù)挖掘可以從以往的交易記錄中“總結(jié)”出客戶這些方面的信息。
(2)客戶關(guān)系管理:數(shù)據(jù)挖掘可以識(shí)別產(chǎn)品使用模式或協(xié)助了解客戶行為,從而可以改進(jìn)通道管理(Channel Management)。例如,適時(shí)銷售(Right Time Marketing)就是基于可由數(shù)據(jù)挖掘發(fā)現(xiàn)的顧客生活周期模型來實(shí)施的一種商業(yè)策略。
(3)零售業(yè):數(shù)據(jù)挖掘?qū)︻櫩唾?gòu)物籃數(shù)據(jù)(Basket Data)的分析可以協(xié)助貨架布置、確定促銷活動(dòng)時(shí)間、促銷商品組合及了解暢銷和滯銷商品的狀況。
(4)產(chǎn)品質(zhì)量保證:通過對(duì)歷史數(shù)據(jù)的分析,數(shù)據(jù)挖掘可以發(fā)現(xiàn)某些不正常的數(shù)據(jù)分布,暴露制造和裝配操作過程中出現(xiàn)的問題。
(5)WEB站點(diǎn)的數(shù)據(jù)挖掘:電子商務(wù)網(wǎng)站每天都可能有上百萬(wàn)次的在線交易,生成大量的記錄文件和登記表,可以對(duì)這些數(shù)據(jù)進(jìn)行分析和挖掘,充分了解客戶的喜好、購(gòu)買模式,甚至是客戶的一時(shí)沖動(dòng),以設(shè)計(jì)出滿足不同客戶群體需求的個(gè)性化網(wǎng)站,甚至從數(shù)據(jù)中推測(cè)客戶的背景信息,進(jìn)而增加其競(jìng)爭(zhēng)力。
另外,在各個(gè)企事業(yè)部門,數(shù)據(jù)挖掘在假偽檢測(cè)、風(fēng)險(xiǎn)評(píng)估、失誤回避、資源分配、市場(chǎng)銷售預(yù)測(cè)和廣告投資等方面都可以發(fā)揮作用。在國(guó)外,數(shù)據(jù)挖掘已應(yīng)用于銀行金融、零售批發(fā)、制造、保險(xiǎn)、公共設(shè)施、行政、教育、通信、運(yùn)輸?shù)榷鄠€(gè)行業(yè)部門,并且已經(jīng)出現(xiàn)了許多數(shù)據(jù)挖掘和知識(shí)發(fā)現(xiàn)系統(tǒng)。例如,Quest是由IBM Almaden研究中心開發(fā)的數(shù)據(jù)挖掘系統(tǒng),它可以從大型數(shù)據(jù)庫(kù)中發(fā)現(xiàn)關(guān)聯(lián)規(guī)則、分類規(guī)則、時(shí)間序列模式等;DBMiner是加拿大Jiawei Han教授領(lǐng)導(dǎo)的小組開發(fā)的一個(gè)數(shù)據(jù)挖掘系統(tǒng);SKICAT系統(tǒng)是由U.M.Fayyad等人開發(fā)的知識(shí)發(fā)現(xiàn)系統(tǒng),它將圖像處理、數(shù)據(jù)分類、數(shù)據(jù)庫(kù)管理等功能集成在一起,能夠自動(dòng)地對(duì)數(shù)字圖像進(jìn)行搜索和分類;KEFIR(Key Finding Reporter)是由GTE實(shí)驗(yàn)室開發(fā)的一個(gè)知識(shí)發(fā)現(xiàn)系統(tǒng)等。
- 現(xiàn)代測(cè)控系統(tǒng)典型應(yīng)用實(shí)例
- Mastercam 2017數(shù)控加工自動(dòng)編程經(jīng)典實(shí)例(第4版)
- 錯(cuò)覺:AI 如何通過數(shù)據(jù)挖掘誤導(dǎo)我們
- Learning Apache Spark 2
- Getting Started with MariaDB
- 條碼技術(shù)及應(yīng)用
- 大型數(shù)據(jù)庫(kù)管理系統(tǒng)技術(shù)、應(yīng)用與實(shí)例分析:SQL Server 2005
- AutoCAD 2012中文版繪圖設(shè)計(jì)高手速成
- 工業(yè)控制系統(tǒng)測(cè)試與評(píng)價(jià)技術(shù)
- Nginx高性能Web服務(wù)器詳解
- Mastering Game Development with Unreal Engine 4(Second Edition)
- Photoshop行業(yè)應(yīng)用基礎(chǔ)
- 寒江獨(dú)釣:Windows內(nèi)核安全編程
- Learn Microsoft Azure
- ADuC系列ARM器件應(yīng)用技術(shù)