- 生成:AI生產力重構營銷新范式
- 譚北平 金立印
- 1444字
- 2025-06-19 18:24:31
2.2 基于人類反饋的強化學習
關于人類應該如何看待人工智能,凱文·凱利(Kevin Kelly)有個形象的描述:“和人怎么相處,就和人工智能怎么相處。用‘當人看’來理解人工智能,用‘當人看’來控制人工智能,用‘當人看’來說服用戶正確看待人工智能的不足。”
人工智能作為一個數字神經網絡,之所以能像人一樣思考,底層的核心機制就是基于人類反饋的強化學習(Reinforcement Learning from Human Feedback, RLHF)。
RLHF是一種結合了人類反饋和強化學習的技術,主要用于優化生成式人工智能(如GPT等語言模型)的表現。它通過采集和利用人類評審員的反饋數據,指導模型生成更符合人類期望和偏好的內容,彌補了傳統監督學習中單純依賴預先標注數據的不足,使得模型能夠動態適應和改進。
以ChatGPT為例,我們簡單介紹一下RLHF的工作原理與過程,如圖2-1所示。
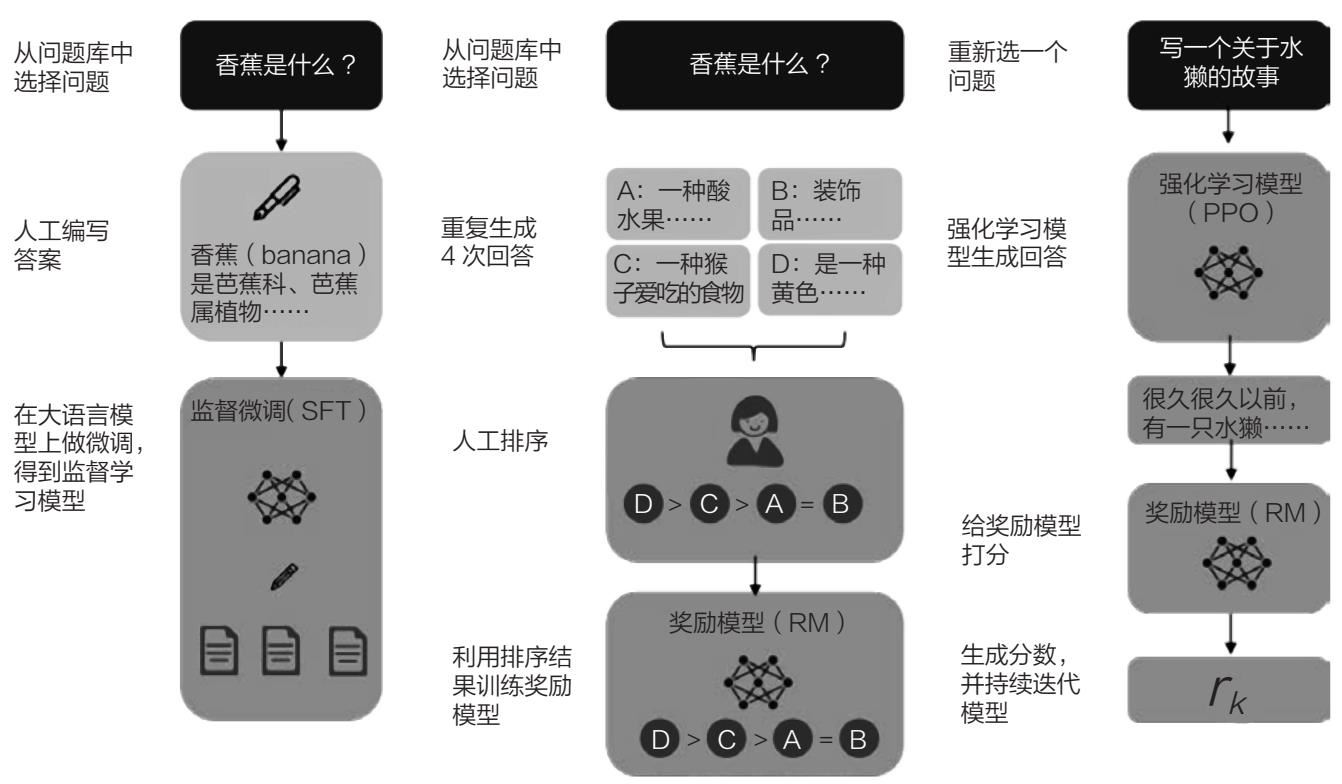
圖2-1 生成式人工智能的RPHF過程
監督學習:模型初始訓練
生成式人工智能的訓練首先從監督學習開始。在這一過程中,模型通過讀取大量人類編寫的文本數據,學會預測詞和句子的結構。具體而言,ChatGPT等模型會分析這些數據,并構建起一個初步的語言模型。這一過程類似于學生通過閱讀大量書籍和文章來掌握語言方面的基礎知識,為后續的復雜任務奠定基礎。
收集人類偏好數據
不過,僅僅依靠初始的監督學習還不夠,模型需要進一步優化,才能更好地生成符合人類期望的文本。這時,RLHF發揮了關鍵作用。RLHF通過人類反饋來不斷優化模型。在這個過程中,模型會從問題庫中選擇問題并生成多種回答。然后,人類評審員對生成的回答進行排序,確定哪些回答最符合人類的偏好。
訓練獎勵模型:理解人類偏好
接下來,開發人員將根據人類評審員的排序結果來訓練一個獎勵模型(Reward Model, RM)。這個獎勵模型會預測模型生成的回答在多大程度上符合人類的偏好,以人類的偏好來作為判斷生成內容的質量的標準。這個過程的核心在于收集大量帶有質量評分的數據,以幫助模型學習什么樣的回答更符合人類的期望。
基于強化學習的生成模型優化
在獲得訓練好的獎勵模型后,生成式人工智能將進入基于強化學習的優化過程。這里通常采用的是近端策略優化算法(Proximal Policy Optimization, PPO)。在這一過程中,模型生成回答,然后獎勵模型對回答打分和排序,記錄為rk,分數越高代表回答越符合人類的偏好,模型會選擇高分回答進行輸出。這些排序還會持續喂給獎勵模型迭代調整,這樣模型不斷優化自己的參數,以生成更高質量的回答。
這一過程類似于人類學習技能的過程,通過反復的練習和考核,人類逐漸提高自己的語言技能、算數技能、運動技能等。在強化學習的幫助下,模型能夠根據人類反饋反復修正自身,從而提升文本生成的準確性和相關性。
通過上述過程,RLHF使生成式人工智能能夠多輪反饋優化,從初步的監督學習,到收集和理解人類偏好,再到通過強化學習優化模型。這個迭代過程讓生成式人工智能變得越來越智能,逐步生成更符合人類期望的自然語言文本。通過這一機制,生成式人工智能會具有更高層次的理解和生成能力,為廣泛應用提供基礎。
討論:我們能從RLHF中學到什么?
RLHF,即根據人類反饋進行強化學習,是一種用于訓練模型的方法。其核心思想是通過人類反饋引導模型學習,從而使其表現更好地符合人類的期望和偏好。
這種核心思想與人類的語言學習與教育的過程特別匹配。這說明人工智能是可以被訓練的。
在企業中,新員工往往需要經歷一個再學習的過程,以了解企業的知識、企業的文化、企業成功的要素。這個過程往往是通過績效(Performance)來實現反饋和篩選的,也就是基于績效反饋的強化學習(Reinforcement Learning from Performance Feedback, RLPF)。
通過RLHF可以訓練出一個符合人類習慣的大語言模型,而用RLPF手段,可以訓練出一個符合企業需求的模型。