- 生成式AI實戰
- 歐陽植昊 梁菁菁 呂云翔主編
- 1825字
- 2024-12-12 17:57:43
1.3.2 常見任務
1. 文本生成
文本生成任務主要包括如下內容。
● 新聞文章。自動化生成新聞內容,旨在提高新聞報道的效率和速度。
● 故事創作。創造新穎的故事和小說,為作家和內容創造者提供靈感。
● 代碼生成。自動生成代碼片段,幫助開發者提高開發效率。
文本總結是文本生成最廣泛的應用之一,即將長文檔縮寫成較短的文本,同時保留其中的重要信息。一些模型可以從初始輸入中提取文本,而其他模型可以生成全新的文本。
接下來我們通過如下代碼進行實踐。
Python
from transformers import pipeline
classifier = pipeline("summarization")
classifier("Paris is the capital and most populous city of France, with an estimated population of 2,175,601 residents as of 2018, in an area of more than 105 square kilometres (41 square miles). The City of Paris is the centre and seat of government of the region and province of ?le-de-France, or Paris Region, which has an estimated population of 12,174,880, or about 18 percent of the population of France as of 2017.")
## [{ "summary_text": " Paris is the capital and most populous city of France..." }]
可以看到,借助Hugging Face的transformers庫,可以快速完成文本生成任務。
2. 圖像生成
圖像生成任務主要包括如下內容。
● 藝術創作。利用AI創作獨特的藝術品,模仿或超越傳統的藝術風格。
● 圖像編輯。自動調整圖像參數或進行復雜的編輯任務,如風格轉換、面部編輯等。
● 虛擬現實內容。生成虛擬現實環境中的視覺內容,用于游戲、模擬和教育等場景。
圖1-3展示了無條件圖像生成,即在任何上下文(如提示文本或另一幅圖像)中無條件生成圖像的任務。一旦訓練完成,模型將創造出類似其訓練數據分布的圖像。這個領域中非常流行的模型包括生成對抗網絡和變分自編碼器模型。由于此類模型不如Stable Diffusion模型更有用,因此本書不會花大量篇幅介紹這類較為過時的模型。
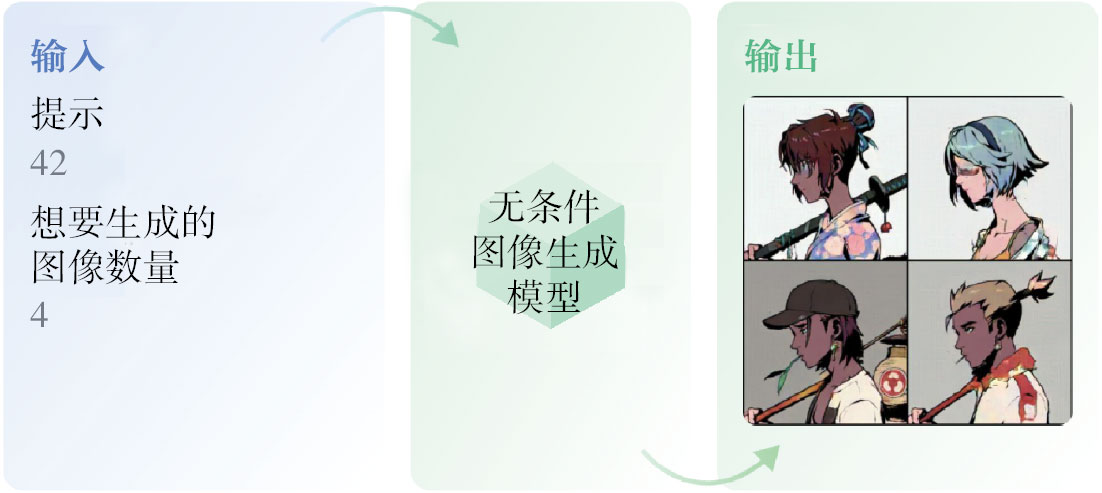
圖1-3 無條件圖像生成
圖1-4展示了文生圖模型的應用過程,即輸入文本生成圖像。這些模型可以用來根據文本提示生成或修改圖像。

圖1-4 輸入文本生成圖像
這里我們使用第三方庫進行文生圖代碼的實踐。示例代碼如下。
Python
from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
model_id = "stabilityai/stable-diffusion-2"
scheduler = EulerDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
3. 音頻生成
音頻生成任務主要包括如下內容。
● 音樂創作。創造新的音樂作品,模仿特定藝術家或風格,或完全創新。
● 語音合成。生成清晰、自然的語音輸出,用于虛擬助手、有聲讀物和其他應用。
音頻到音頻是一類任務,其中輸入是一個音頻,輸出是一個或多個生成的音頻。示例任務如語音增強和聲源分離等。圖1-5展示了音頻到音頻轉換的過程。
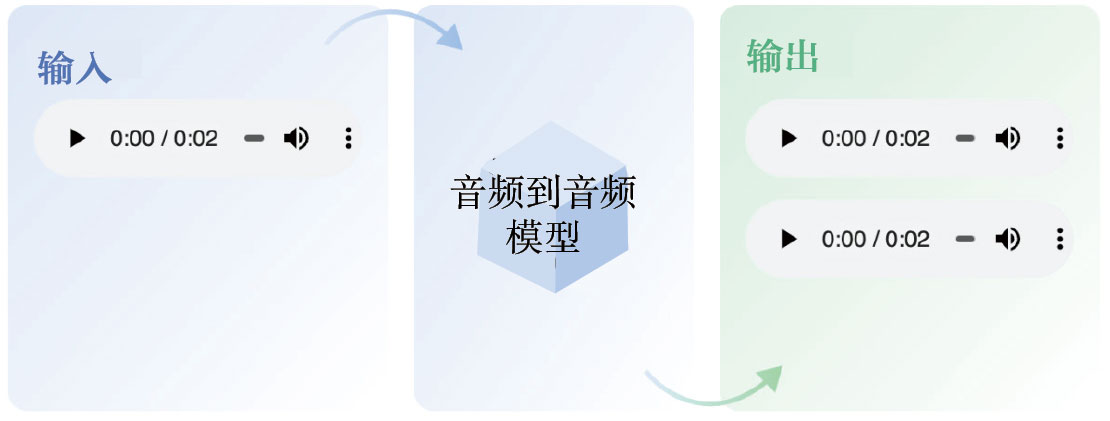
圖1-5 音頻到音頻轉換
音頻到音頻轉換的示例代碼如下。
Python
from speechbrain.pretrained import SpectralMaskEnhancement
model = SpectralMaskEnhancement.from_hparams(
"speechbrain/mtl-mimic-voicebank"
)
model.enhance_file("file.wav")
如圖1-6所示,文本轉語音(Text-to-Speech,TTS)模型可用于任何需要將文本轉換成模仿人聲的語音應用中。在智能設備上,TTS模型被用來創建語音助手。與通過錄制聲音并映射它們來構建助手的拼接方法相比,TTS模型是更好的選擇,因為TTS模型生成的輸出包含自然語音中的元素,如重音。在機場和公共交通的公告系統中,TTS模型被廣泛使用,主要用于將給定文本的公告轉換成語音。
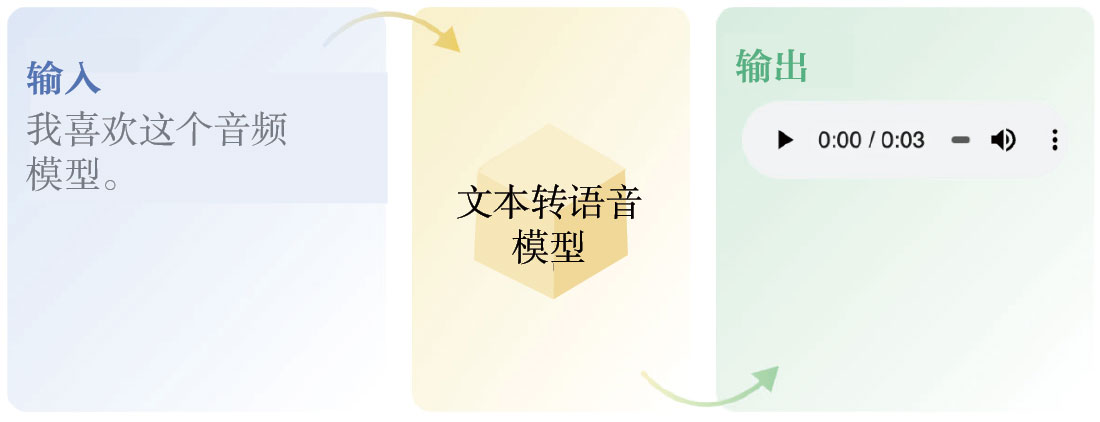
圖1-6 文本轉語音
文本轉語音的示例代碼如下。
Python
from transformers import pipeline
synthesizer = pipeline("text-to-speech", "suno/bark")
synthesizer("Look I am generating speech in three lines of code!")
4. 視頻生成
視頻生成任務主要包括如下內容。
● 基于腳本的視頻生成。根據提供的文本腳本創建短視頻內容,如營銷視頻,解釋產品工作原理等。
● 內容格式轉換。將長篇文本、博文、文章和文本文件轉換成視頻,用于制作教育視頻,讓內容變得更加吸引人,互動性更強。
● 配音和語音。創建AI新聞播報員以傳遞日常新聞,或者由電影制作人創建短片或音樂視頻等。
視頻生成任務的變體如下。
● 文本到視頻編輯。生成基于文本的視頻樣式和局部屬性編輯,簡化裁剪、穩定、色彩校正、調整大小和音頻編輯等任務。
● 文本到視頻搜索。檢索與給定文本查詢相關的視頻,通過語義分析、視覺分析和時間分析,確定與文本查詢最相關的視頻。
● 文本驅動的視頻預測。根據文本描述生成視頻序列,目標是生成視覺上真實且與文本描述語義一致的視頻。
● 視頻翻譯。將視頻從一種語言翻譯成另一種語言,或允許使用非英語句子查詢多語言文本-視頻模型,適用于希望觀看包含自己不懂的語言的視頻的人群,特別是當有多語言字幕可供訓練時。
視頻生成(這里使用了文生視頻模型,即從文字生成視頻模型)的示例如圖1-7所示。
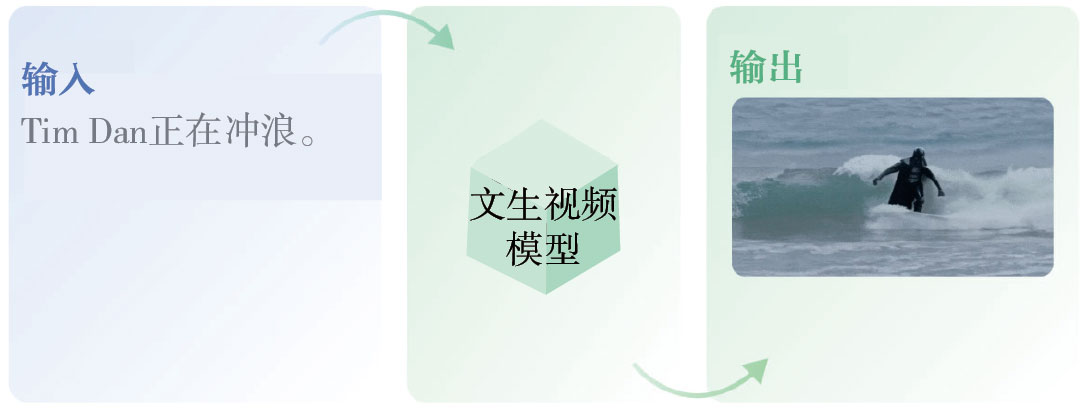
圖1-7 視頻生成
5. 多模態任務
如圖1-8所示,圖像問答(也稱為視覺問答)是基于圖像回答開放式問題的任務。它們對自然語言問題輸出自然語言響應。

圖1-8 圖像問答
圖像問答的示例代碼如下。
Python
from PIL import Image
from transformers import pipeline
vqa_pipeline = pipeline("visual-question-answering")
image = Image.open("elephant.jpeg")
question = "Is there an elephant?"
vqa_pipeline(image, question, top_k=1)
#[{'score': 0.9998154044151306, 'answer': 'yes'}]
如圖1-9所示,文檔問答(也稱為文檔視覺問答)是指在文檔圖像上回答問題的任務。文檔問答模型將文檔-問題對作為輸入,并返回自然語言的答案。這類模型通常依賴于多模態特征,涉及文本、單詞位置(邊界框)和圖像等。

圖1-9 文檔問答
文檔問答的示例代碼如下。
Python
from transformers import pipeline
from PIL import Image
pipe = pipeline("document-question-answering", model="naver-clova-ix/donut-base-finetuned-docvqa")
question = "What is the purchase amount?"
image = Image.open("your-document.jpg")
pipe(image=image, question=question)
## [{'answer': '20,000$'}]