- Flink原理深入與編程實戰:Scala+Java(微課視頻版)
- 辛立偉編著
- 590字
- 2023-07-17 18:54:39
2.3.1 Flink數據流
在Flink中,應用程序由數據流組成,這些數據流可以由用戶定義的運算符(有時將這些運算符稱為“算子”)進行轉換。這些數據流形成有向圖,從一個或多個源開始,以一個或多個輸出結束,如圖2-25所示。

圖2-25 Flink程序流
Flink支持流處理和批處理,它是一個分布式的流批結合的大數據處理引擎。在Flink中,認為所有的數據本質上都是隨時間產生的流數據,把批數據看作流數據的特例,只不過流數據是一個無界的數據流,而批數據是一個有界的數據流(例如固定大小的數據集),如圖2-26所示。
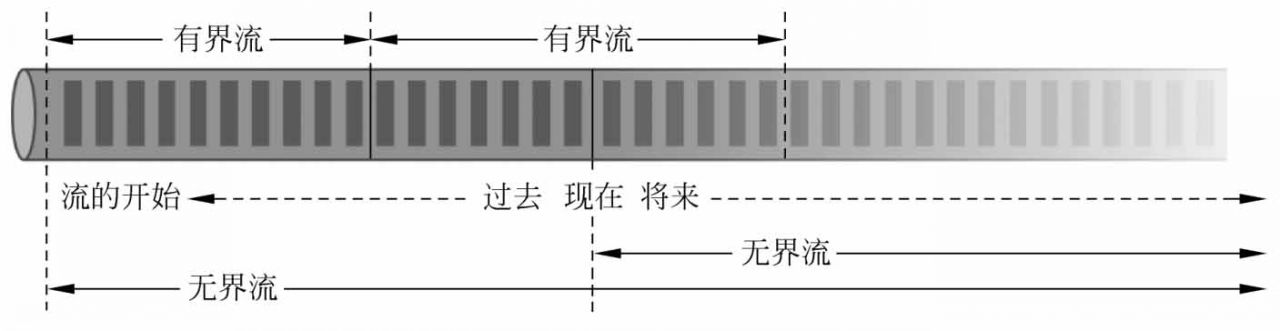
圖2-26 有界流和無界流
因此,Flink是一個用于在無界和有界數據流上進行有狀態計算的通用的處理框架,它既具有處理無界數據流的復雜功能,也具有專門的運算符來高效地處理有界數據流。通常將無界數據稱為實時數據,這些數據來自消息隊列或分布式日志等流源(如Apache Kafka或Kinesis);而有界數據通常指的是歷史數據,這些數據來自各種數據源(如文件、關系型數據庫等)。由Flink應用程序產生的結果流可以發送到各種各樣的系統,并且可以通過REST API訪問Flink中包含的狀態,如圖2-27所示。
當Flink處理一個有界的數據流時采用的就是批處理工作模式。在這種操作模式中,可以選擇先讀取整個數據集,然后對數據進行排序、計算全局統計數據或生成總結所有輸入的最終報告。
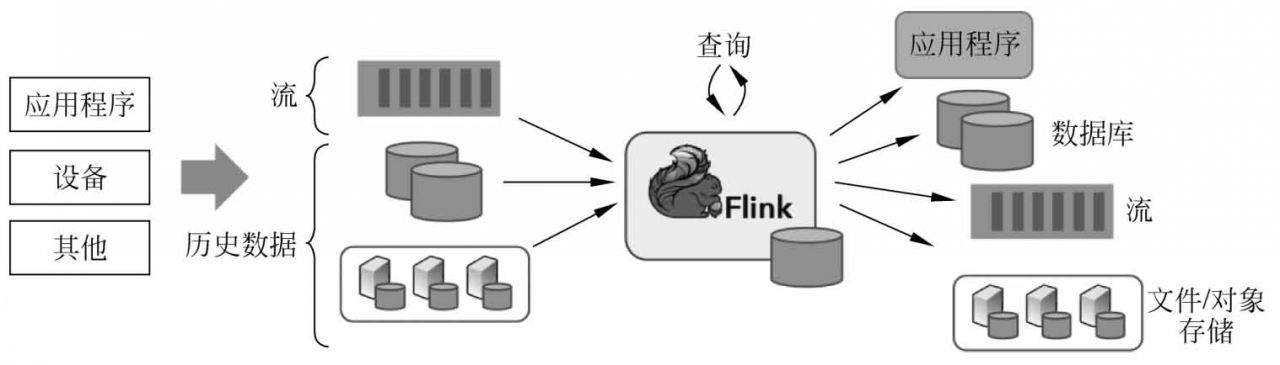
圖2-27 Flink處理框架
當Flink處理一個無界的數據流時采用的就是流處理工作模式。對于流數據處理,輸入可能永遠不會結束,因此必須在數據到達時持續不斷地對這些數據進行處理。
推薦閱讀
- 深入核心的敏捷開發:ThoughtWorks五大關鍵實踐
- Learning NServiceBus(Second Edition)
- Python快樂編程:人工智能深度學習基礎
- C++程序設計(第3版)
- Computer Vision for the Web
- JavaFX Essentials
- Unity Game Development Scripting
- 硅谷Python工程師面試指南:數據結構、算法與系統設計
- Java面向對象程序設計
- Android應用開發實戰(第2版)
- Secret Recipes of the Python Ninja
- Drupal 8 Development:Beginner's Guide(Second Edition)
- 數據結構:Python語言描述
- ASP.NET Core and Angular 2
- Mastering Machine Learning with scikit-learn