- 網絡爬蟲原理與實踐:基于C#語言
- 李健 種惠芳
- 5970字
- 2023-02-23 16:13:13
1.1 網絡基礎
本節將介紹與爬蟲密切相關的網絡知識,主要內容包括:網絡的基本概念、HTTP和會話機制。如果你已經掌握了這些知識,可以跳過本節。
1.1.1 網絡的基本概念
1.互聯網與網絡協議
計算機網絡由若干節點(Node)和連接這些節點的鏈路(Link)組成。網絡中的節點可以是計算機、集線器、交換機等設備。網絡之間可以通過路由器互連起來構成覆蓋范圍更大的計算機網絡——互聯網(internet)。互聯網的模型結構如圖1-1所示。
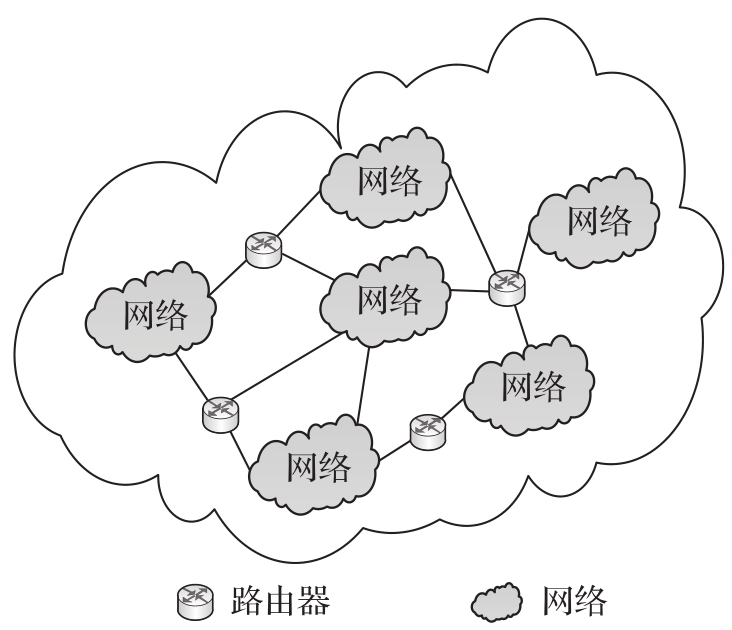
圖1-1 互聯網示意圖
因特網(Internet)是目前世界上覆蓋范圍最廣、規模最大、資源最豐富的互聯網。因特網采用TCP/IP協議族作為信息通信規則,提供包括WWW、FTP、E-mail、Telnet在內的多種服務。
計算機必須遵循一定的網絡協議才能進行正常的信息傳輸和數據交換。在計算機網絡中,通信雙方進行信息傳輸時所遵循的規則、標準或約定即網絡協議(簡稱協議)。網絡協議明確規定了交換數據的格式以及相關的同步問題,為計算機在網絡中有條不紊地進行數據交換提供了保證。網絡協議一般由語法、語義和時序3個要素組成:
□ 語法:規定了數據與控制信息的結構或格式。
□ 語義:規定了需要發出何種控制信息、完成何種動作以及做出何種響應。
□ 時序:規定了事件的實現順序。
網絡協議通過網絡協議軟件來實現。連接在網絡上的計算機要執行網絡任務,首先必須安裝網絡協議。由于計算機網絡協議非常復雜,為了簡化實現并提高設計效率,人們采用分層的方法來研究它,從而形成了分層的網絡體系結構。因特網采用的TCP/IP體系結構及各層的關鍵協議如表1-1所示。
表1-1 TCP/IP體系結構及各層的關鍵協議
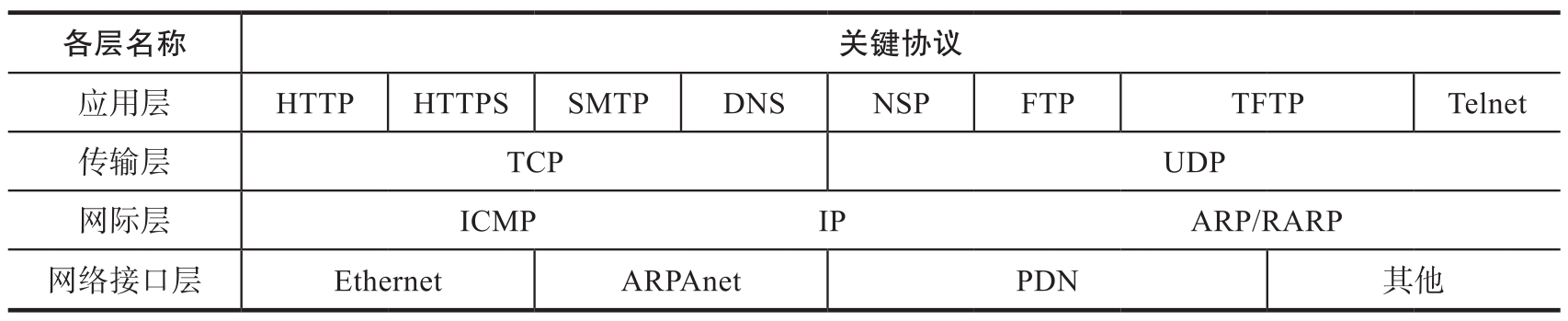
IP(Internet Protocol,網際協議)在整個TCP/IP協議族中處于核心地位,主要用于解決不同網絡之間的互連問題,是構成互聯網的基礎。IP位于TCP/IP模型的網際層,對上承載各種傳輸層協議(如TCP、UDP等),對下支持多種網絡接口(如Ethernet等)。
2.網絡地址與端口號
TCP/IP規定:網絡上的每個設備都必須至少具有一個獨一無二的IP地址,這就像信件上必須注明收件人地址,郵遞員才能將信件送到一樣。因此,每個IP數據包都必須包含目標設備的IP地址,才能夠被正確轉發到目的地。
說明:IP地址由ICANN(The Internet Corporation for Assigned Names and Numbers,因特網名稱與數字地址分配機構)負責統一分配。我國用戶可以向亞太網絡信息中心(Asia Pacific Network Information Center, APNIC)申請IP地址。目前廣泛使用的IPv4地址由32位二進制數組成。為便于識別,通常將IPv4地址表示為“點分十進制”(如220.181.38.149)。在下一代IP——IPv6中,IP地址包含128位二進制數(通常采用十六進制數表示)。
為了便于對IPv4地址進行管理,因特網對IP地址進行了分類,每一類地址由兩個固定長度的字段組成。其中第一個字段是網絡號(Net-Id),它標識主機或路由器所連接的網絡;第二個字段是主機號(Host-Id),它標識網絡中的一個主機或路由器。圖1-2展示了分類IP地址的二進制結構。
因特網使用IP地址來唯一標識網絡中的一臺設備,但一臺計算機可能運行著多個應用程序或服務,那么數據是如何正確地傳輸至同一臺計算機的不同應用程序的呢?答案是可借助協議端口號(Protocol Port Number)來區分不同的程序。
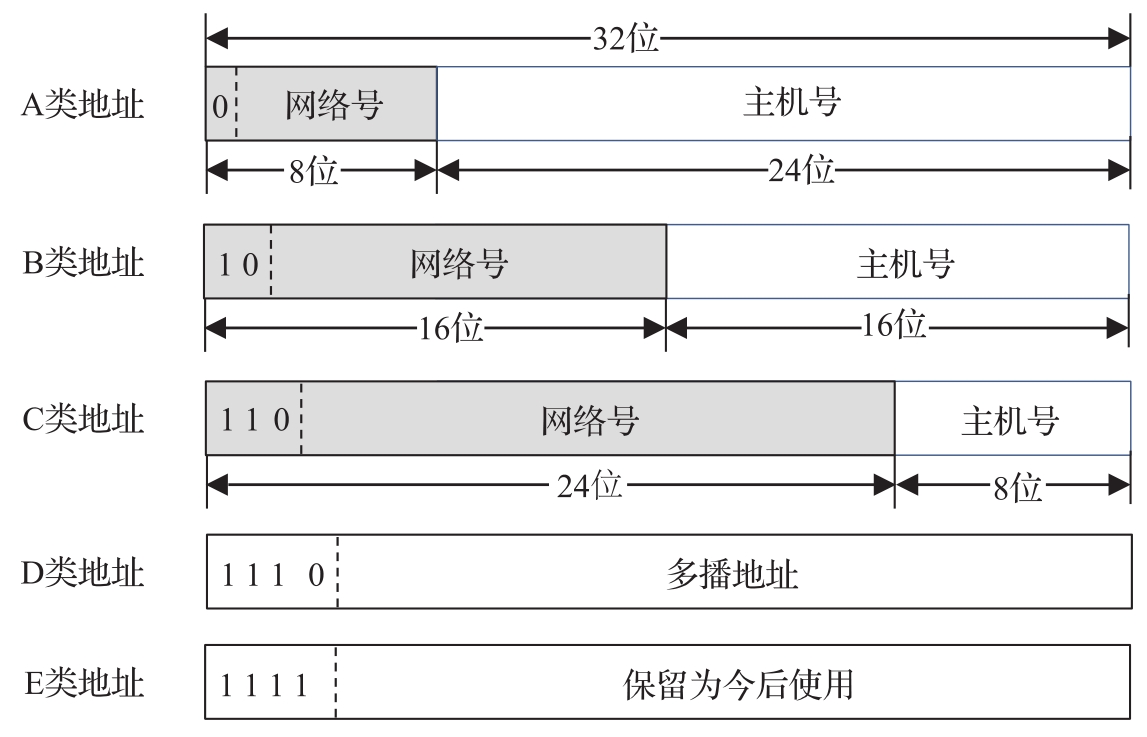
圖1-2 IP地址的分類
協議端口號簡稱端口號,是用來標識一臺計算機上的特定網絡應用的數字編號,其有效范圍為0~65535。其中,0~1023為公認端口(Well Known Port)或系統端口,相對固定地分配給常用服務程序;1024~49151為注冊端口(Registered Port)或登記端口,松散地綁定著一些服務;49152~65535為動態/私有端口(Dynamic/Private Port),供用戶程序自由申請使用。表1-2列出了一些常用的公認端口號。
表1-2 常用的公認端口號
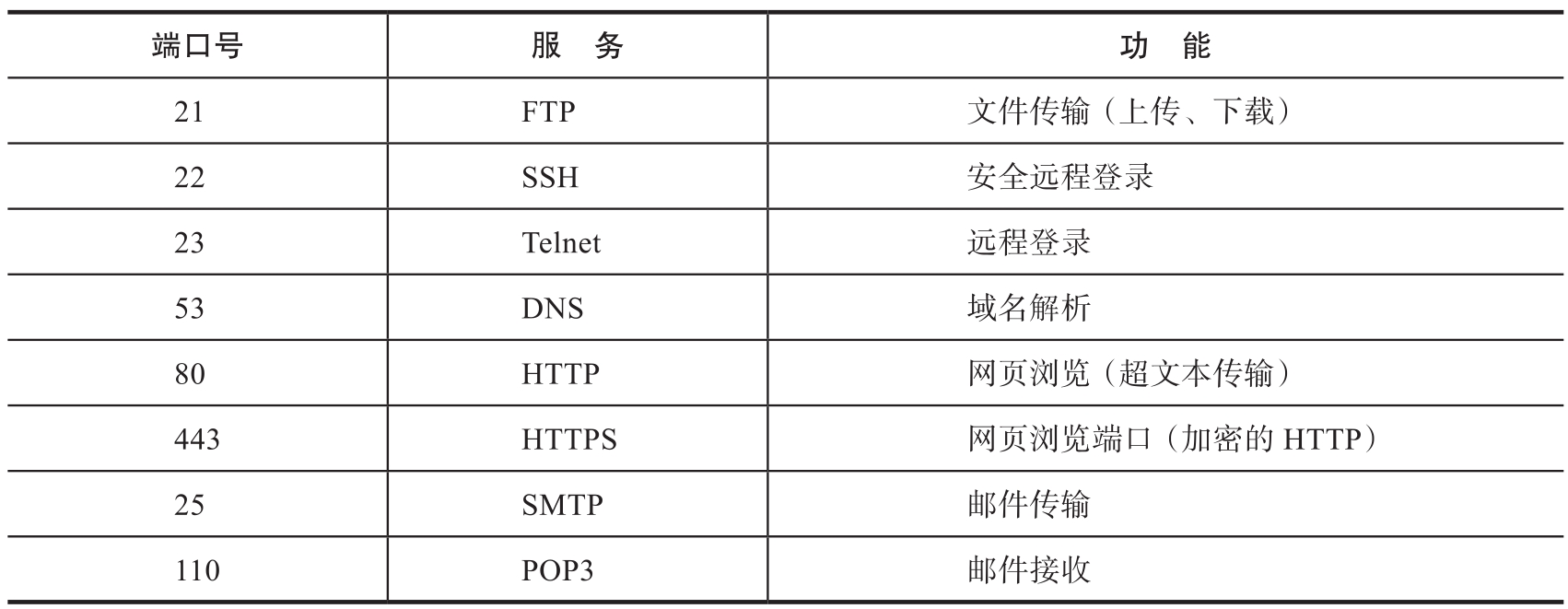
端口號通常與IP地址配合使用,端口號通過“:”連接在IP地址之后,表示該IP所指主機中某個特定的網絡應用(服務)。例如,我們可以通過“http://220.181.38.149:80”訪問百度首頁,但通常省略默認端口號(80),將其簡化為“http://220.181.38.149”。
3.域名與DNS
由于IP地址是一個固定長度的數字序列,不便于人類記憶(人們更擅長記憶那些有特定含義的字符串),因此有人提出了域名(Domain Name, DN)的概念。域名可以看作IP地址的別名,它由“.”分隔的標號序列組成。例如,可以使用域名“www.baidu.com”代替IP地址“220.181.38.149”。顯然,前者更容易被記住。
域名中的各標號分別代表不同的域,域之間存在一定的層次結構,從右至左分別為頂級域、二級域、三級域等。例如,在“www.baidu.com”中,“www”為三級域名,“baidu”為二級域名,“com”為頂級域名。因特網中的基本域名結構如圖1-3所示。
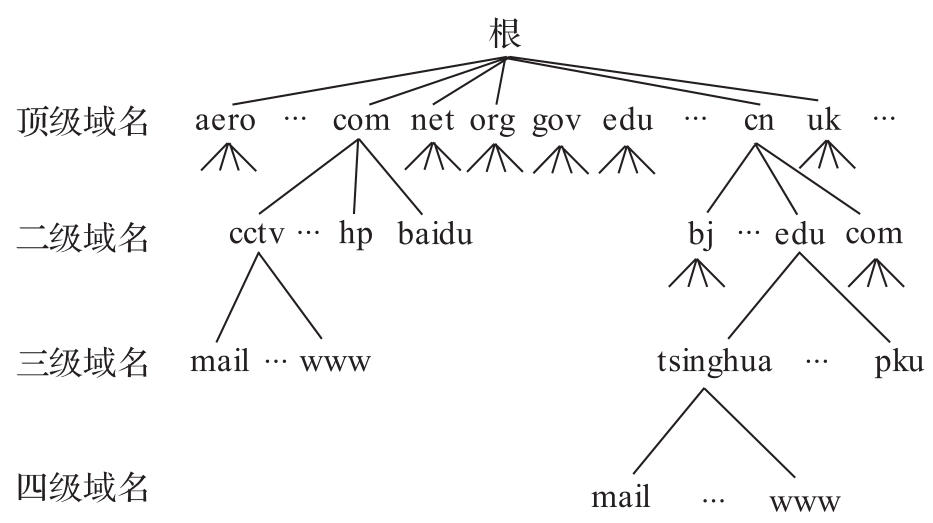
圖1-3 因特網域名結構示意圖
雖然域名便于記憶,但網絡設備仍是基于IP地址進行數據轉發的。為此,人們又設計了域名系統(Domain Name System, DNS)以實現域名到IP地址的映射,從而確保在使用域名的情況下也能夠正常進行數據轉發。因特網中的域名系統通過多個域名服務器來實現,其中最重要的是根域名服務器。由于歷史和技術原因,全球共有13個根域名服務器(從a.rootservers.net到m.rootservers.net,分別對應13個IP)。每個根域名服務器又包含若干鏡像,它們通過任播(Anycast)技術共享同一個IP,訪問該IP的報文會被轉發到就近的鏡像服務器。目前,全球共有1000多個根鏡像服務器。
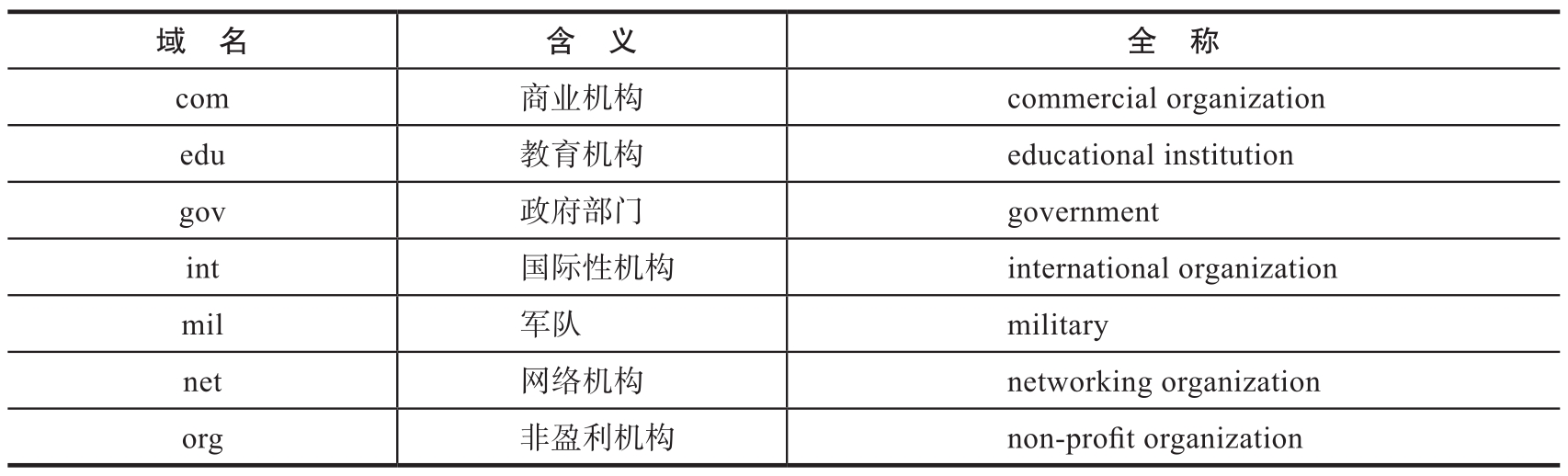
我們通常認為域名與IP地址是一一對應的,這只是一種理想狀態。實際上,一個IP地址可以對應多個域名,一個域名也可以被解析為多個IP地址。有些公司出于商業目的會注冊多個域名,并指向同一個IP地址;有些門戶網站為了負載均衡會將同一個域名解析到不同的Web服務器。頂級域名往往具有特定的含義(如表1-3所示)。
表1-3 主要的頂級域名及其含義
4.網絡資源標識
網絡資源是以數字化形式記錄,以多媒體形式表達,以二進制數據存儲,并通過計算機網絡通信方式進行傳播的信息內容集合。與傳統信息資源相比,網絡資源在數量、結構、分布、傳播范圍、載體形態、傳遞手段等方面都呈現出不同的特點。從資源形式來看,網絡資源包括文本、圖像、音頻、視頻、數據庫等。
網絡資源必須按照一定的規則進行準確標識,才能被訪問和使用。URL(Uniform Resource Locator,統一資源定位符)是一種用于標識網絡資源的技術規范。URL指定了某個資源在因特網中的位置以及訪問方式,其基本結構如下:
<協議>://<主機>:<端口>/<路徑>
□ <協議>:指出采用什么協議來獲取該網絡資源(形如http、ftp等)。
□ “://”:固定格式,位于<協議>之后、<主機>之前。
□ <主機>:指出網絡資源存儲在哪臺主機上,可使用域名或IP地址表示。
□ “:”:固定格式,位于<主機>之后、<端口>之前。
□ <端口>:指明訪問服務器上的哪個網絡應用端口號。
□ <路徑>:指明網絡資源在服務器上的具體位置(可包含多級路徑)。
以“http://github.com:80/img/favicon.ico”為例,其協議類型為HTTP,訪問目標是域名為“github.com”的主機;端口為80(HTTP默認端口,可省略);路徑指向該主機img/目錄下的favicon.ico文件。由此可見,通過URL可準確定位因特網中的某個資源。
說明:URL是URI(Uniform Resource Identifier,統一資源標識符)的子集,URL和URN(Uniform Resource Name,統一資源名稱)共同構成了URI。URN只命名資源(如“ISBN:0451450523”標識一本書)而不說明如何定位。在因特網中,幾乎所有的URI都是URL,我們通常將網絡資源鏈接稱為URL,也可稱為URI。
5.萬維網概述
WWW(World Wide Web,萬維網)也稱為Web,是因特網提供的核心服務之一。Web服務器使用HTML(HyperText Marked Language,超文本標記語言)將相關信息資源組織起來,HTML文檔和相關資源在客戶端展現為圖文并茂的網頁(Web Page)。
客戶端和服務器之間采用HTTP進行數據傳輸,客戶端向服務器發送資源請求,服務器將響應數據返回給客戶端。Web服務器將多個相關網頁有機地組織在一起,從而構成網站(Website)。用戶可以通過超鏈接從一個頁面跳轉到另一個頁面,這種跳轉既可以在站點內部,也可以在不同站點之間(如圖1-4所示)。
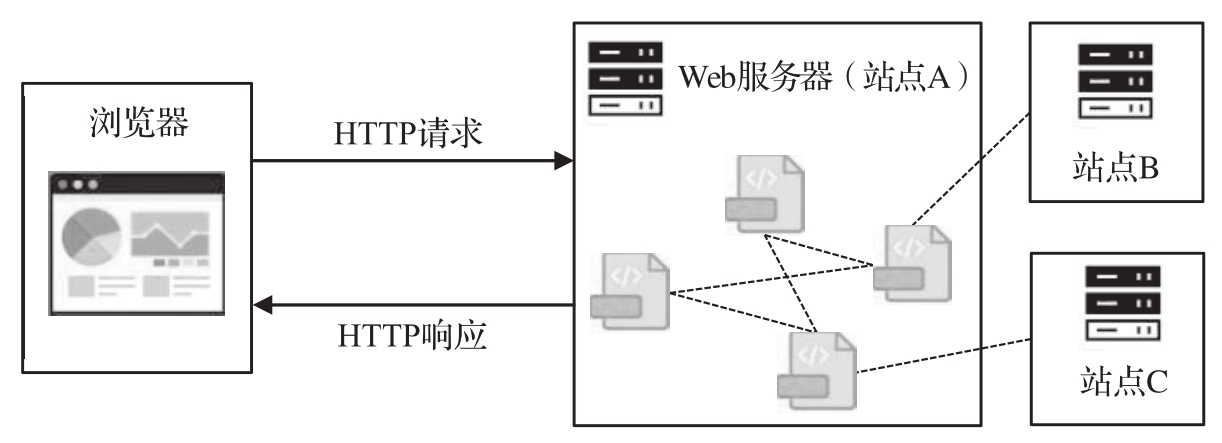
圖1-4 萬維網分布式服務
說明:當訪問站點A的頁面時,瀏覽器會將HTTP請求發送到站點A所在的服務器;若瀏覽器跳轉到站點B的頁面,則會向站點B所在的服務器發出請求。請求發送到哪里是由URL中的<主機>部分決定的,請求和響應的數據傳輸依靠下層的TCP來實現。
1.1.2 HTTP
1.HTTP與HTTPS
HTTP(HyperText Transfer Protocol,超文本傳輸協議)是由萬維網協會(World Wide Web Consortium)和互聯網工程任務組(Internet Engineering Task Force)共同制定的規范。HTTP應用廣泛,幾乎所有的Web應用都遵守該協議。HTTP基于TCP實現,它規定了瀏覽器如何向Web服務器發送請求,以及服務器如何將數據傳送給瀏覽器。
HTTP的工作過程如圖1-5所示。
1)Web服務器啟動后不斷監聽TCP端口,以發現新的連接請求。
2)若服務器檢測到連接請求,則與客戶端建立TCP連接。
3)客戶端基于前期建立的TCP連接,向萬維網服務器發出資源請求。
4)服務器返回對客戶端請求的響應,在數據傳輸完畢后釋放TCP連接,結束本次服務。
說明:在HTTP服務模型中,客戶端可以是Web瀏覽器,也可以是其他任何具有類似功能的應用程序(網絡爬蟲就屬于此類)。HTTP服務器通常是一個Web服務器程序(如Apache、IIS等),其基本功能是接收客戶端的請求并向客戶端發送HTTP響應數據。
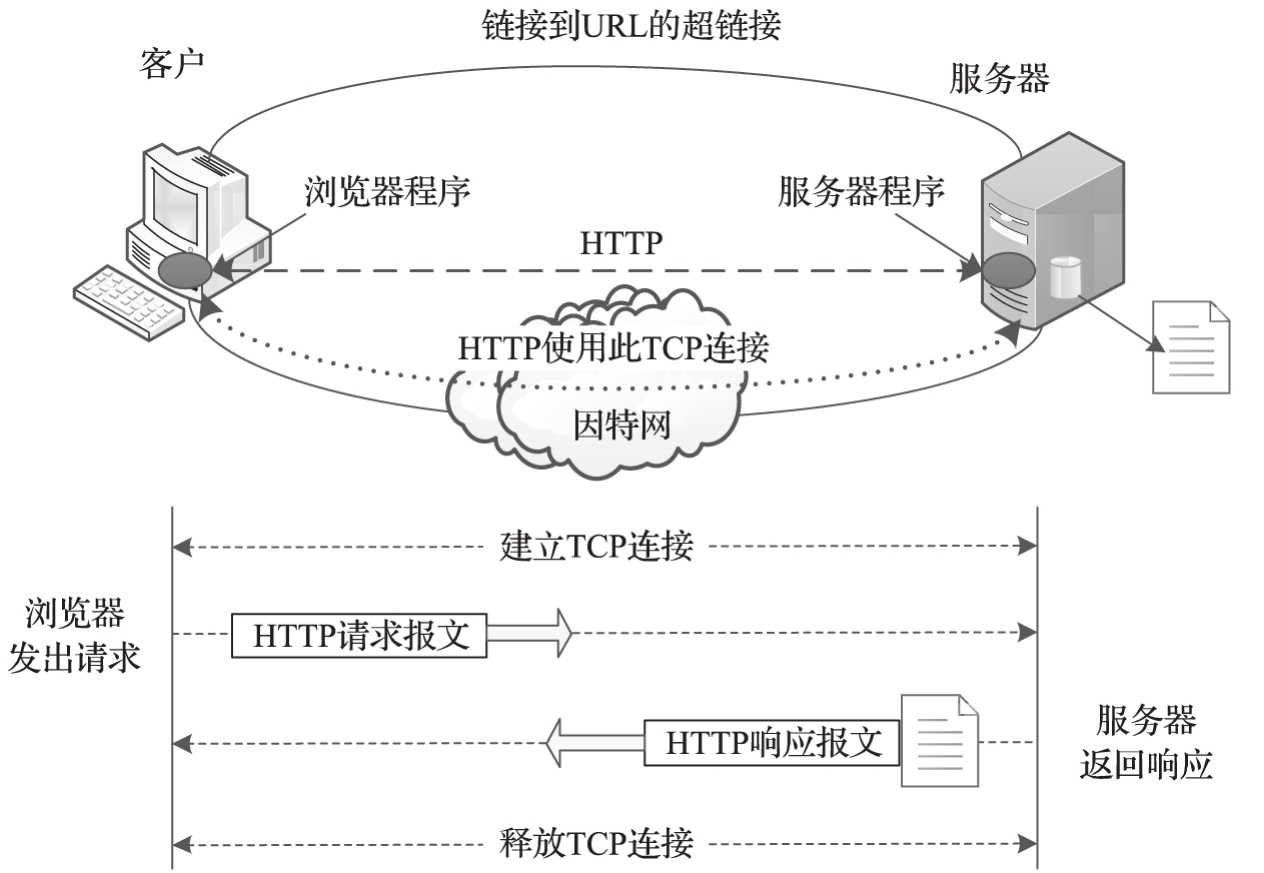
圖1-5 HTTP工作過程
HTTP具有以下特點:
1)無連接,為每次HTTP請求建立單獨的TCP連接,當服務器處理完客戶端請求后就斷開該連接。
2)無狀態,HTTP對于事務處理沒有記憶能力,有時會造成數據重復傳輸。
HTTPS(HyperText Transfer Protocol over Secure Socket Layer,超文本傳輸安全協議)是以安全為目標的協議。HTTPS本質上是在HTTP之下增加了安全套接字層(Secure Sockets Layer, SSL),HTTP與HTTPS的對比如圖1-6所示。
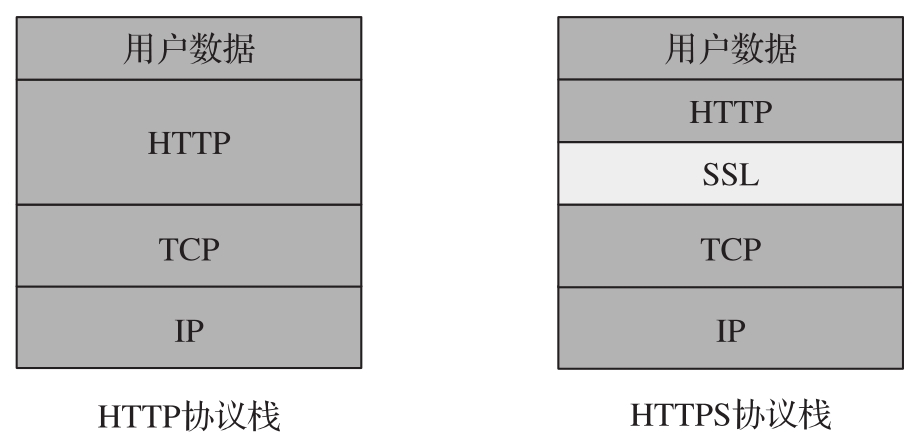
圖1-6 HTTP與HTTPS對比
安全套接字層主要提供以下服務:
1)加密數據以防止數據中途被竊取。
2)認證用戶和服務器身份,確保數據發送到正確的目標。
3)維護數據的完整性,確保數據在傳輸過程中不被改變。
總之,HTTPS能夠提供更安全的網絡通信方式,并已廣泛用于用戶登錄、交易支付等安全敏感的業務。
2.HTTP請求
HTTP請求(Request)主要包括以下要素:請求方法(Request Method)、請求網址(Request URL)、請求頭(Request Header)和請求體(Request Body)。
在HTTP 1.0標準中定義了GET、POST和HEAD 3種請求方法,HTTP 1.1又增加了6種請求方法:OPTIONS、PUT、PATCH、DELETE、TRACE和CONNECT。其中GET和POST仍然是常用的請求方法,它們的區別如表1-4所示。
表1-4 GET與POST方法的對比
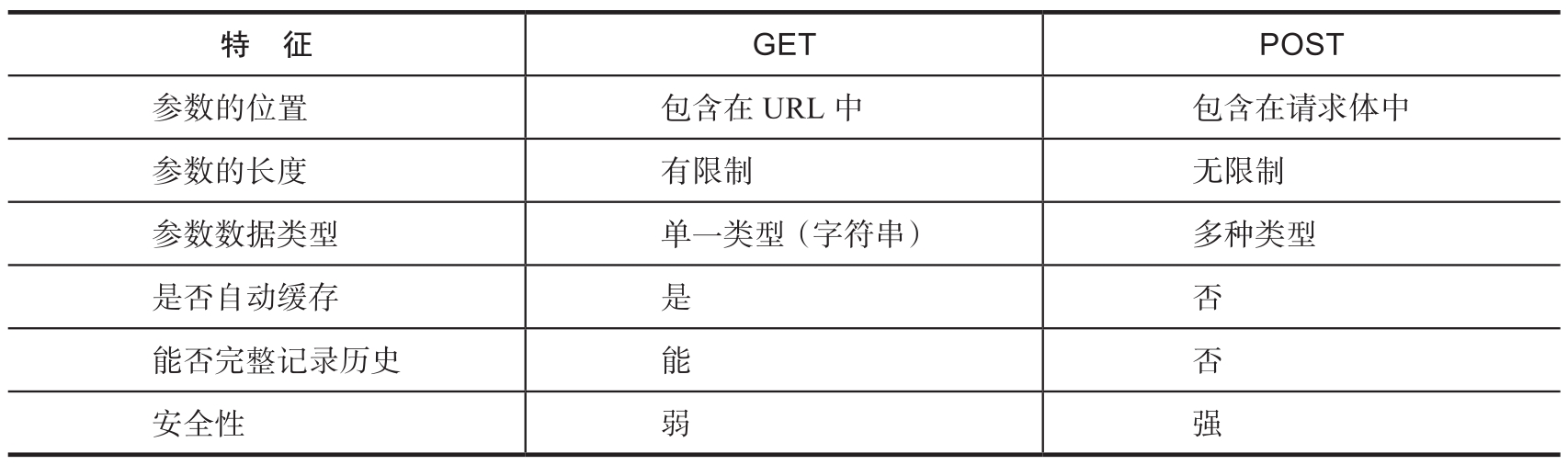
說明:GET方法的參數直接寫在URL中,例如,在“http://hostname/list.html?page=2&size=10”中,“?”之后為參數部分,參數之間以“&”分隔,參數名和參數值以“=”連接。HTTP規范并沒有對URL的長度進行限制,但大多數瀏覽器和服務器對此是有限制的。若登錄時使用GET方法,用戶名、密碼等敏感信息就會暴露在URL中,造成隱私泄露,因此應當使用POST方法。此外,上傳文件也應使用POST方法。
HTTP請求頭可包含若干字段,用于描述客戶端的狀態,其目的是針對本次請求與服務器進行協商。常見的請求頭字段如表1-5所示。
表1-5 常見的請求頭字段
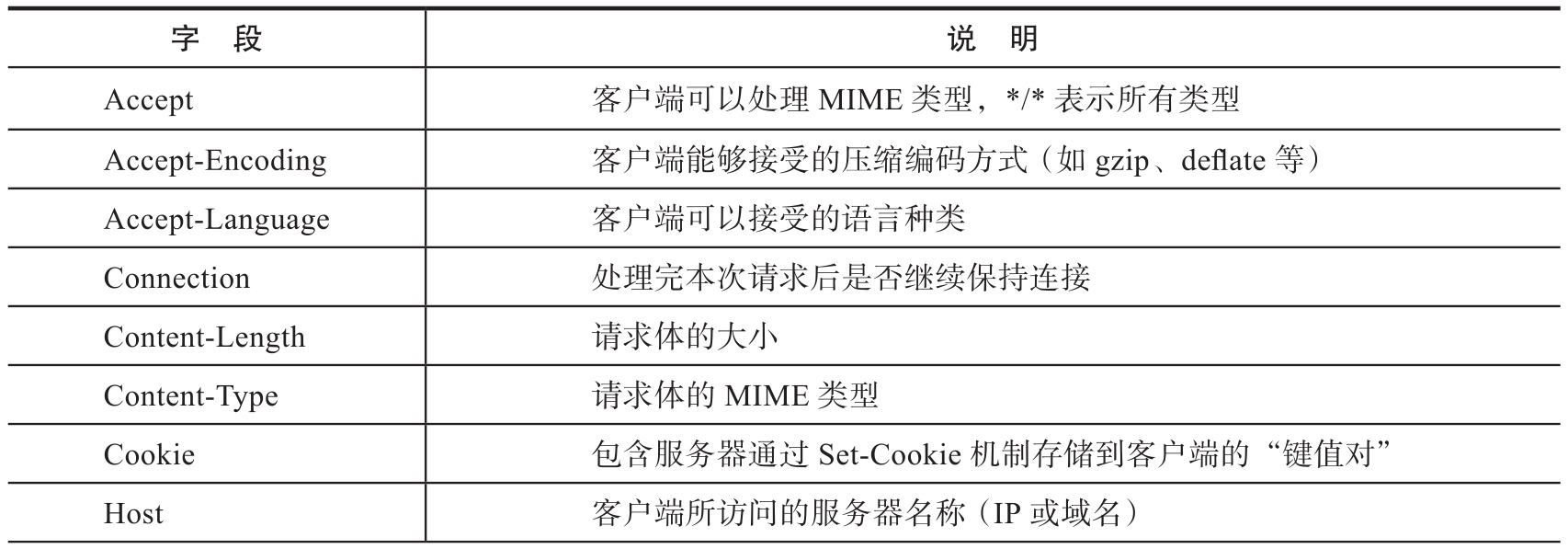
(續)

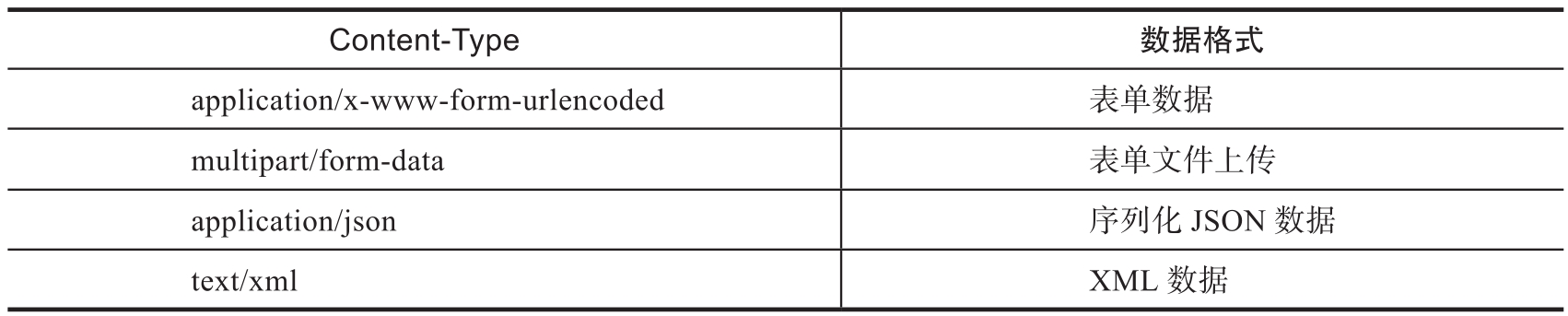
請求頭中的大部分字段是可選的,但有時某些字段是必需的,比如采用POST請求方法時必須包含Content-Length和Content-Type字段。網絡爬蟲通常需要設置User-Agent等字段,將自己偽裝成某種瀏覽器發送請求,否則可能會收到異常響應。GET方法不需要請求體,POST方法的請求體可采用多種數據格式(如表1-6所示)。
表1-6 請求體的數據格式
3.HTTP響應
HTTP響應(Response)是Web服務器對HTTP請求的回應,包括以下3個要素:響應狀態碼(Response Status Code)、響應頭(Response Header)和響應體(Response Body)。
響應狀態碼表示服務器的響應狀態,常見的狀態碼如表1-7所示。在網絡爬蟲的工作過程中,可以根據狀態碼來判斷服務器狀態,進而采取相應的措施。
表1-7 HTTP響應狀態碼
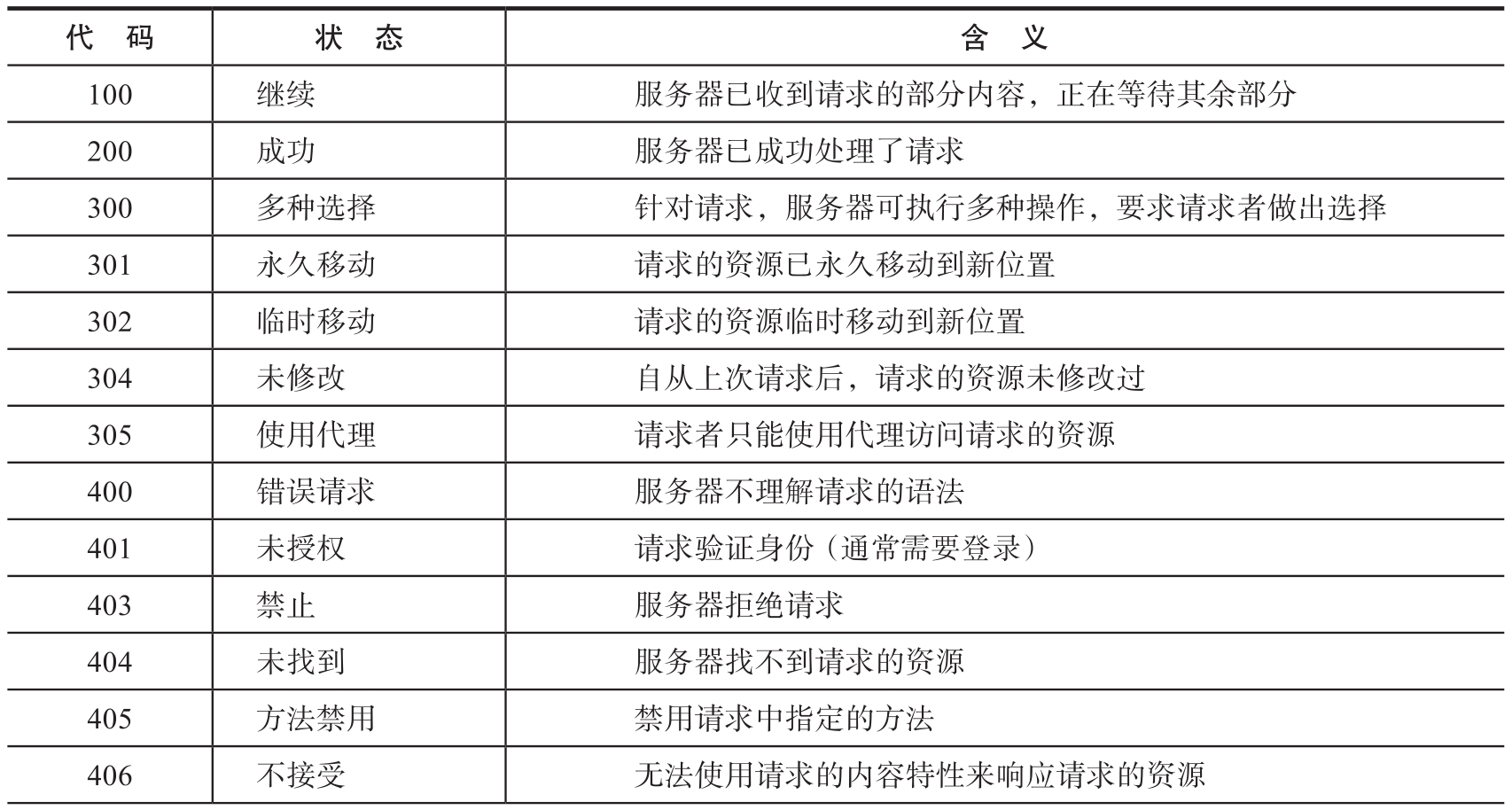
(續)
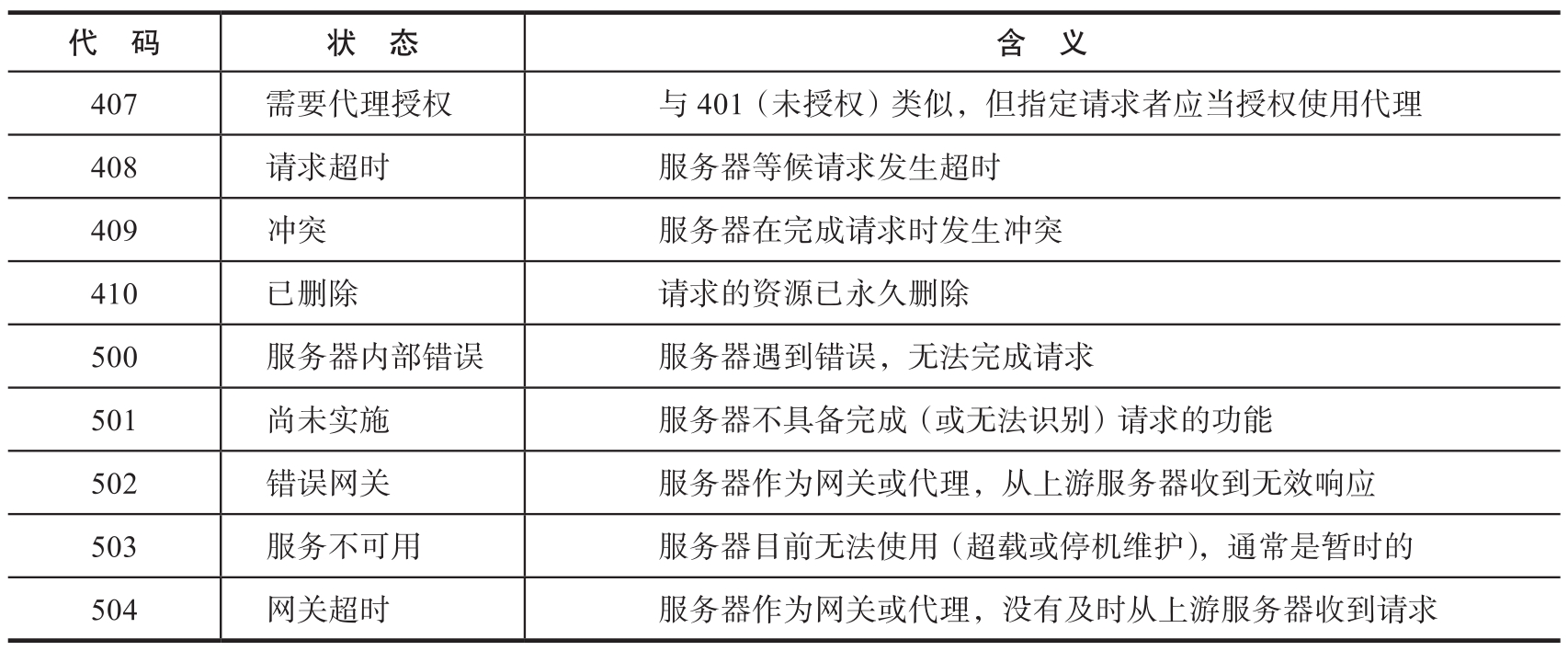
HTTP響應頭描述服務器的狀態以及響應體的相關屬性,與請求頭中的部分字段相呼應,是服務器與客戶端協商的結果。常見的響應頭字段如表1-8所示。
表1-8 響應頭字段及其含義
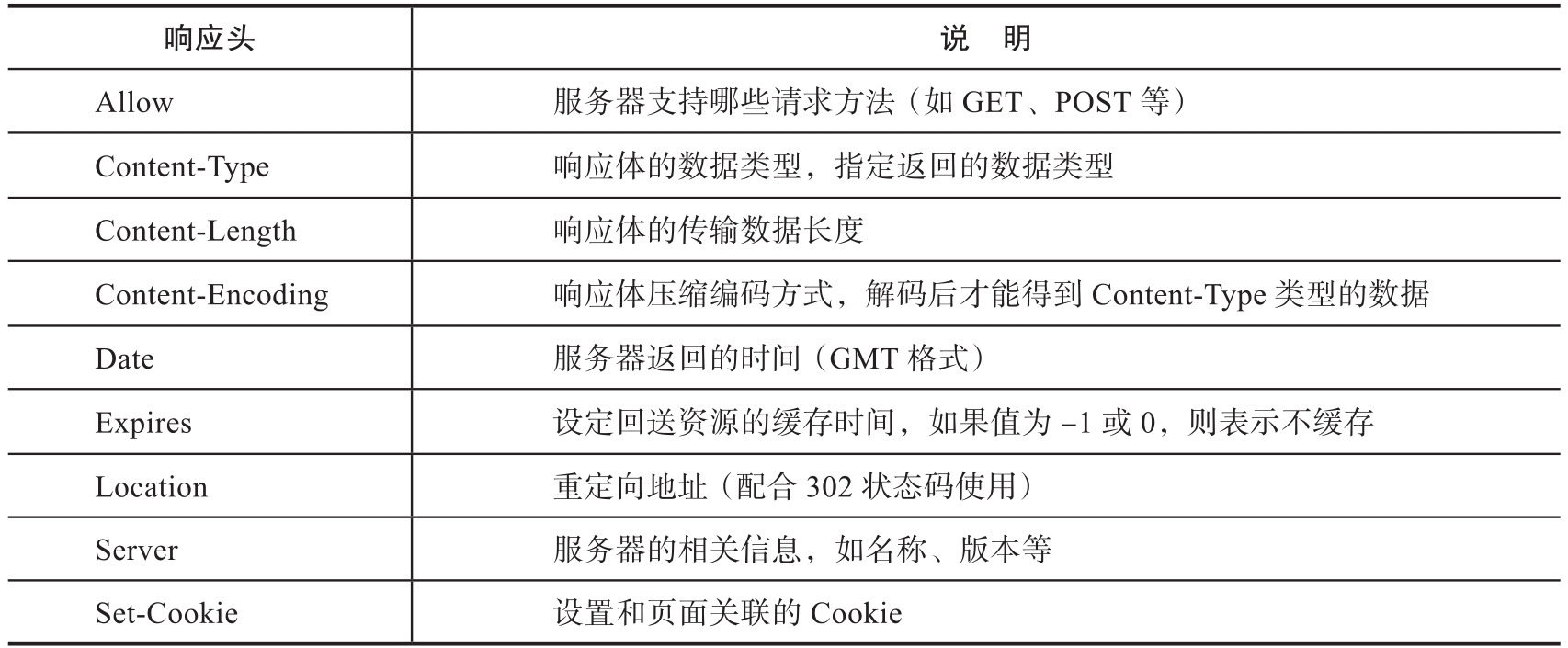
緊跟在響應頭之后的是響應體——響應的正文數據。響應體的數據類型由Content-Type字段指定:“text/html”表示HTML文檔,“text/css”表示CSS文件,“application/x-javascript”表示JavaScript文件,“image/jpeg”表示JPEG格式的圖片等。響應頭通過Set-Cookie字段告訴瀏覽器將哪些內容存放在本地Cookie中。
在Firefox瀏覽器“開發者工具”中選擇“網絡”工具(如圖1-7所示),刷新頁面即可看到當前網頁產生的HTTP請求,右側會列出請求頭和響應頭的字段詳情。
如圖1-7所示,訪問單個網頁卻引發了一系列的HTTP請求,這是因為網頁不僅包含HTML文檔,還有很多相關資源,如圖像、CSS文件、JS代碼等。這些資源的URL以各種形式嵌入HTML文檔中,瀏覽器解析到這些資源后會引發新的HTTP請求。
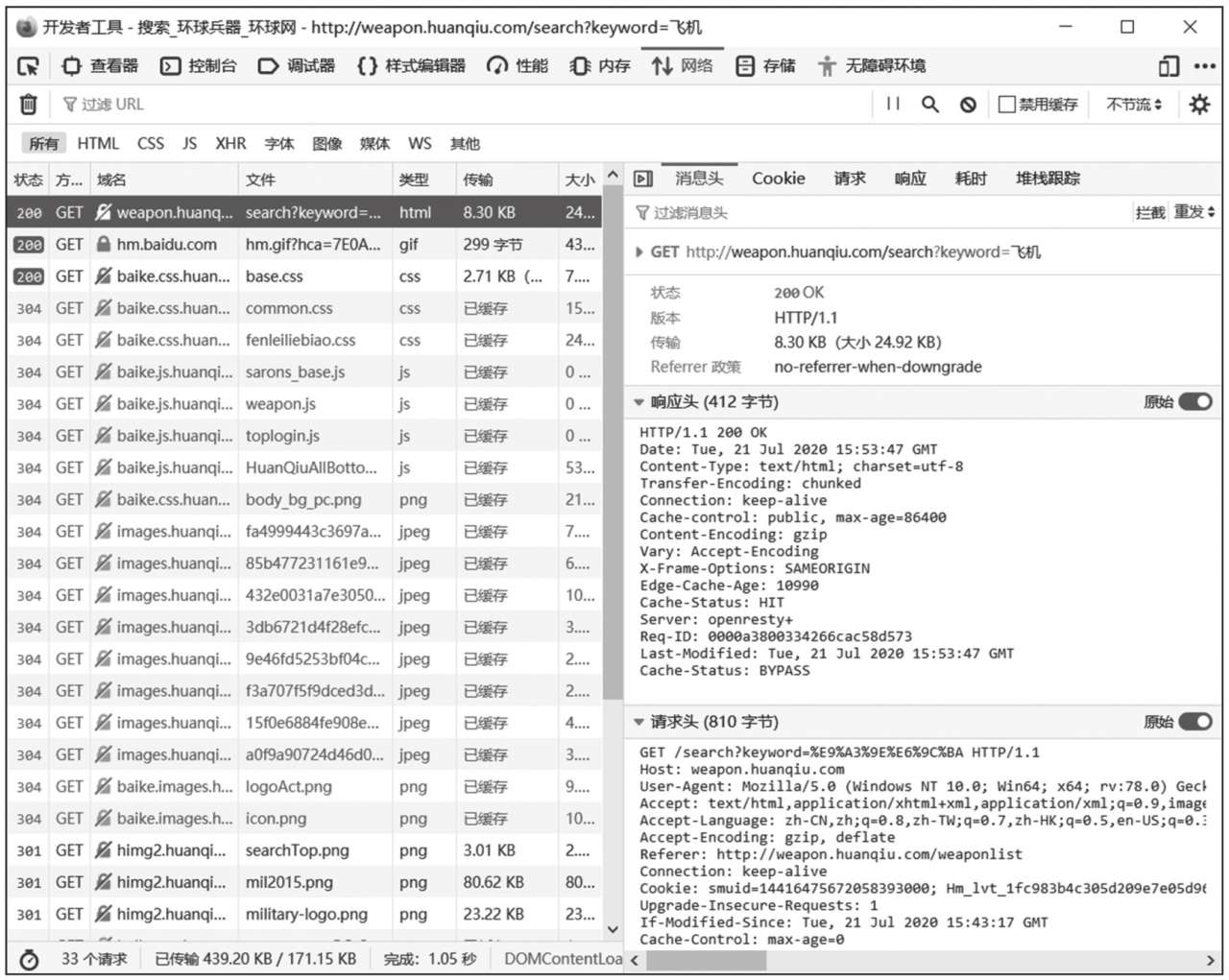
圖1-7 HTTP請求頭和響應頭實例
1.1.3 會話機制
有些Web應用場景不需要登錄(如瀏覽新聞、百度搜索等),另外一些場景則需要登錄(如網上購物、論壇發帖等)。登錄的目的是讓服務器知道你是誰,進而獲得差異化服務。例如,用戶A在登錄某論壇后,只能查看自己的用戶信息、修改自己的密碼,所發的帖子也不能記在其他用戶的名下。
客戶端與Web服務器連續發生的一系列交互過程被稱為一次會話,這個過程類似于兩人之間的一次通話。無狀態的HTTP本身并不支持會話,會話的關鍵在于服務器如何識別用戶身份,這可以借助Cookie或Session技術來實現。Cookie和Session是兩種不同的會話管理方式,前者主要在客戶端記錄用戶信息,后者主要在服務器中記錄用戶信息。
1.Cookie機制
基于Cookie的會話機制如圖1-8所示,服務器在驗證用戶身份后,會要求客戶端額外保存一些數據——Cookie,其中包含一個相當于“會話ID”的信息,此信息同時被保存到服務器的后臺數據庫中。當用戶攜帶Cookie信息再次提交請求時,服務器可以根據“會話ID”識別用戶身份。
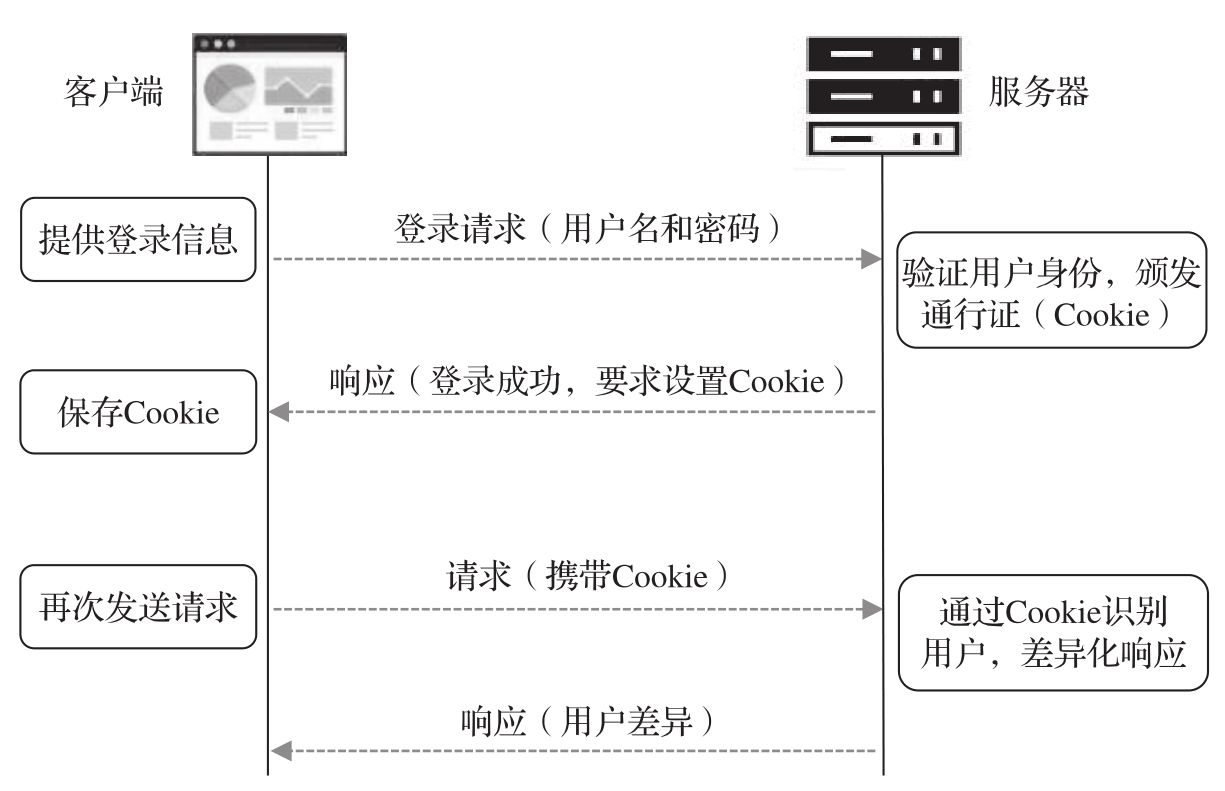
圖1-8 基于Cookie的會話機制
如圖1-9所示,當我們成功登錄“網易通行證”時,服務器所返回的響應頭中包含一些名為Set-Cookie的字段,這些字段就是服務器向客戶端頒發的通行證(Cookie)。
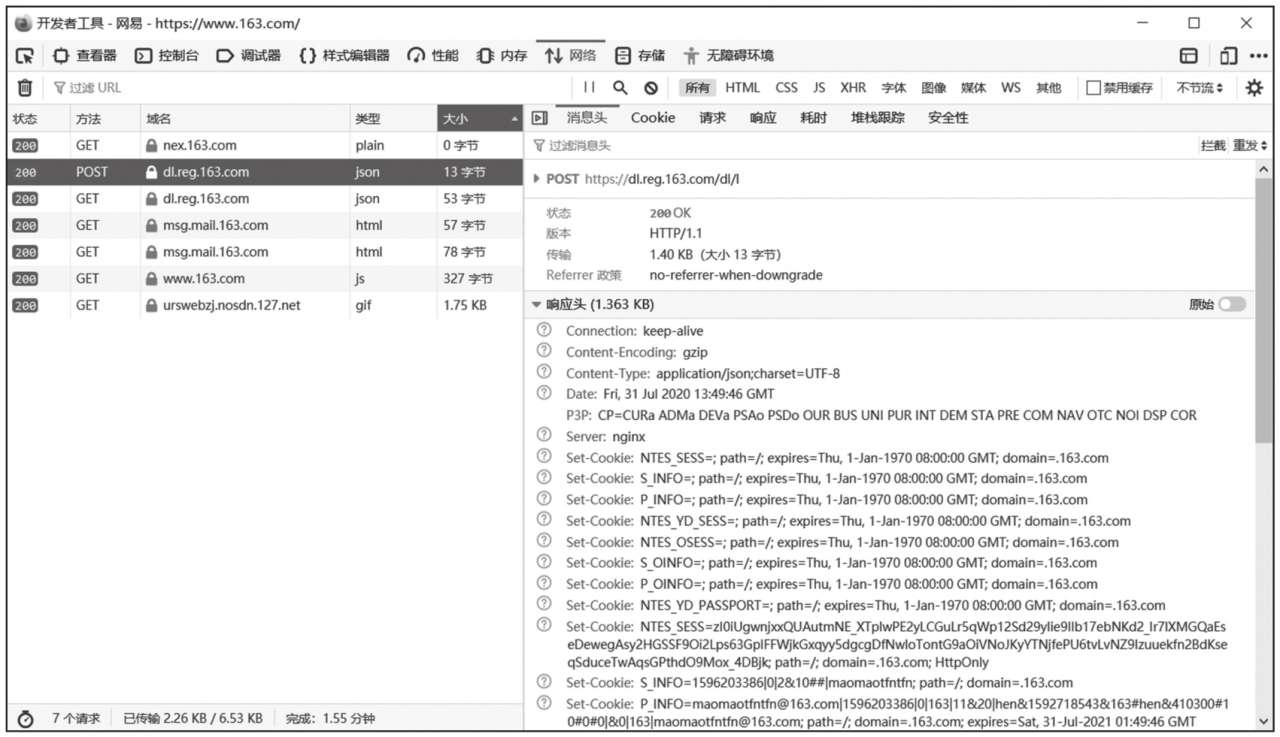
圖1-9 HTTP響應中的Set-Cookie字段
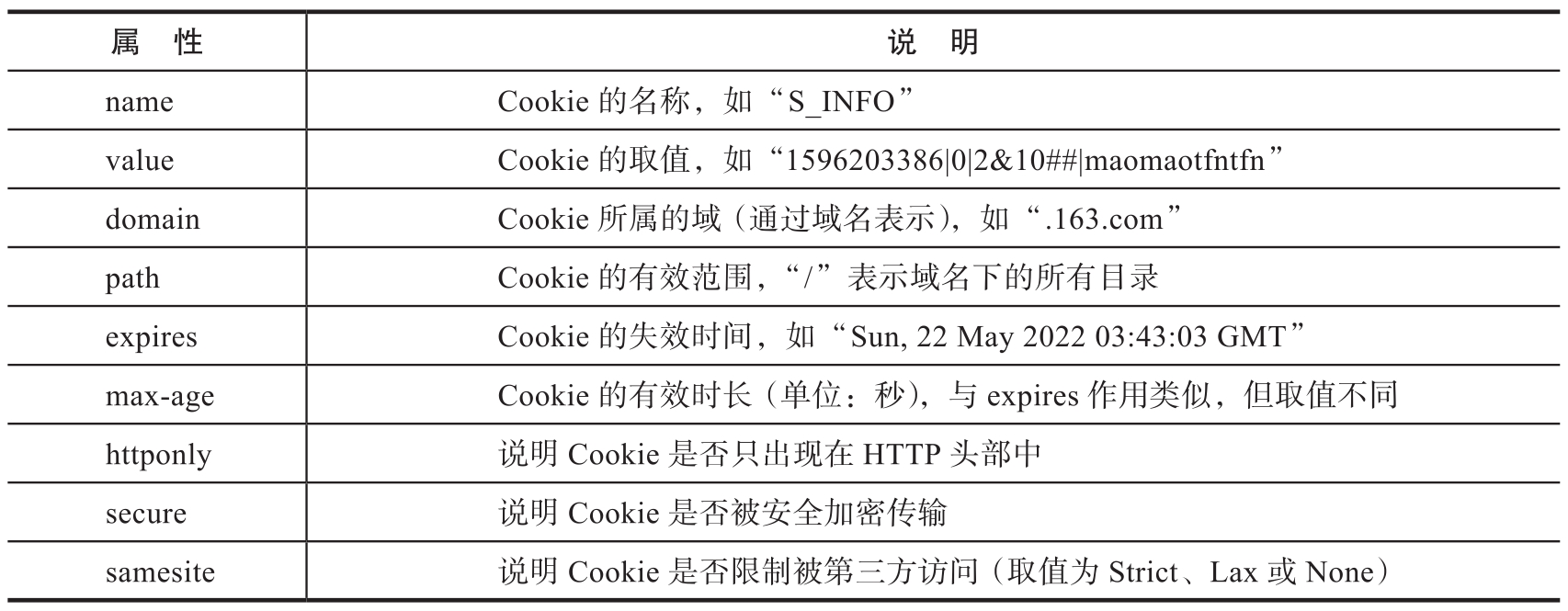
每個Set-Cookie字段包含多個鍵值對,第一個鍵值對表示Cookie的名稱(name)和取值(value),其他鍵值對則表示Cookie的一些特定屬性(如表1-9所示)。
表1-9 Set-Cookie字段中的屬性
如圖1-10所示,登錄網易后再次向服務器發送請求,就會在請求頭中攜帶所保存的Cookie信息(通過Cookie字段),服務器可以據此識別用戶身份。
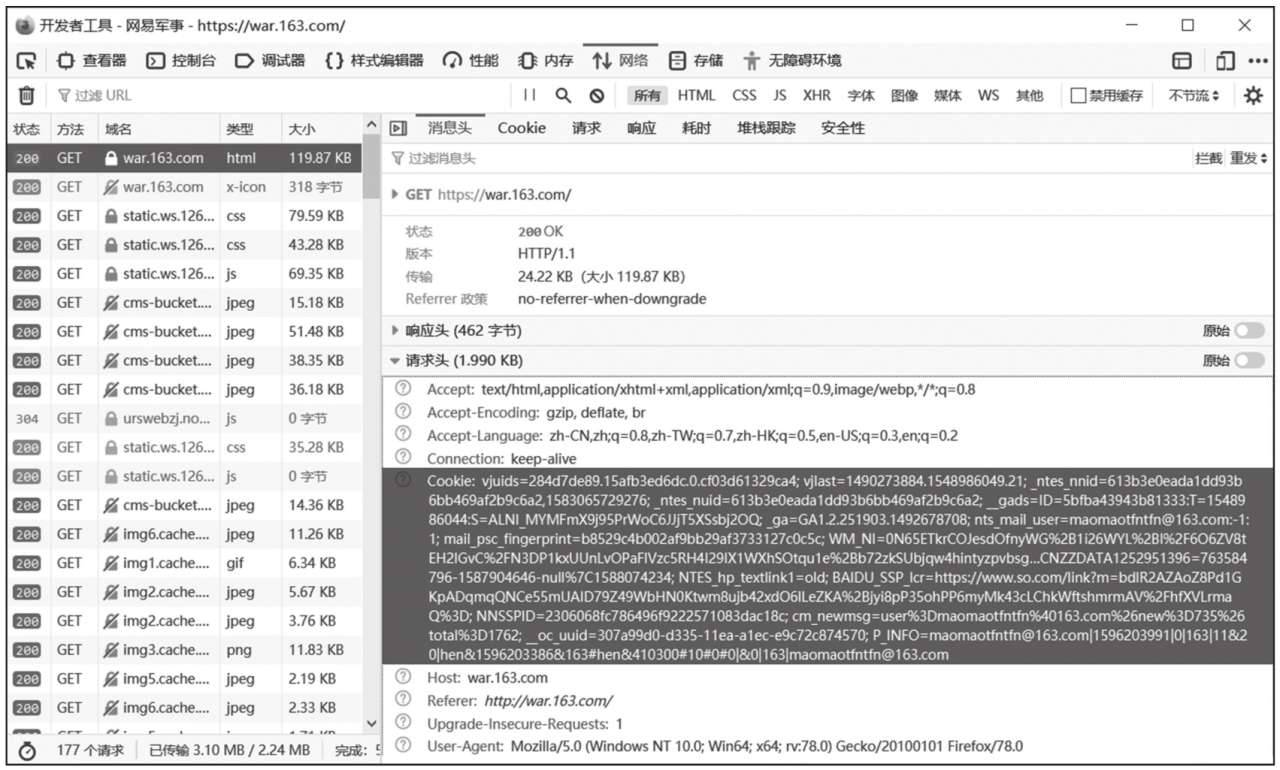
圖1-10 HTTP請求頭中的Cookie字段
響應頭中可以有多個Set-Cookie字段,但請求頭中通常只有一個Cookie字段(其中包含多個鍵值對)。Cookie數據在默認情況下會被保存,但用戶也可以設置瀏覽器禁用某些網站的Cookie。不同瀏覽器保存Cookie的方式有所不同:IE瀏覽器直接將其保存為文本文件,Firefox瀏覽器則將其保存到SQLite數據庫中。
2.Session機制
在Cookie機制中,會話數據存放在客戶端,服務器只保存會話ID。雖然Cookie簡單高效,但也存在一些不足:
1)瀏覽器對Cookie的數量和大小都有限制,難以表示復雜的會話信息。
2)Cookie數據保存在客戶端,安全性較差。
針對上述不足,人們又提出了Session機制(Session本身就是“會話”的意思)。
與Cookie相反,Session機制中的會話數據存放在服務器中,會話ID則以Cookie的形式存放在客戶端。Session的基本工作步驟如下:
1)服務器創建Session對象。當某個客戶端初次訪問服務器時,服務器將為其創建一個Session,并生成一個與此Session相關聯的Session ID。服務器將Session ID與本次響應信息一并返回給客戶端。
2)客戶端再次請求服務器。當客戶端再次訪問某服務器時,會將服務器前期返回的Session ID信息與請求信息一起發送給服務器。
3)服務器響應客戶端請求。服務器收到客戶端的請求消息后,首先檢查客戶端的請求消息里是否包含Session ID,若包含則說明前期已為該客戶創建過Session;服務器可根據Session ID將會話信息檢索出來并使用,若檢索不到則新建一個Session。
4)結束Session。當客戶端要求結束本次會話,或者服務器長時間沒有收到從該客戶端發來的請求時,則結束本次會話。會話結束后,服務器將刪除本次會話數據。
Session機制的優勢在于:
1)數據容量更大,不受瀏覽器的限制。
2)數據類型更豐富,可使用復雜內存對象。
3)會話控制更靈活,服務器能夠隨時掌握會話狀態。
4)數據安全性更高,不易被盜取利用。但是,Session機制會占用更多的服務器資源,同時需要Cookie配合才能實現。