大數(shù)據(jù)分析與應(yīng)用實(shí)戰(zhàn):統(tǒng)計(jì)機(jī)器學(xué)習(xí)之?dāng)?shù)據(jù)導(dǎo)向編程
- 大數(shù)據(jù)分析與應(yīng)用實(shí)戰(zhàn):統(tǒng)計(jì)機(jī)器學(xué)習(xí)之?dāng)?shù)據(jù)導(dǎo)向編程
- 鄒慶士編著
- 1256字
- 2022-07-28 20:15:35
1.3.6 因子
一般而言,屬性的衡量尺度分成名目尺度(nominal scale)、順序尺度(ordinal scale)、區(qū)間尺度(interval scale)與比例尺度(ratio scale)。名目尺度數(shù)據(jù)表示群或類別,僅能進(jìn)行是否相等的運(yùn)算,如身份證號(hào)碼、眼色、郵政編碼等。順序尺度數(shù)據(jù)順序有別,大小比較的排序是有意義的,如排名、年級(jí),或者是以高大、中等或矮小來(lái)表示高度的衡量值。區(qū)間尺度數(shù)據(jù)可自定義任意零點(diǎn),零以下還有負(fù)值,以加減計(jì)算差值或距離有意義,如日期、攝氏度或華氏溫度。比例尺度數(shù)據(jù)有自然零點(diǎn),或稱絕對(duì)零點(diǎn),沒(méi)有負(fù)值,乘除運(yùn)算產(chǎn)生的比率有意義,如開(kāi)氏(Kelvin)溫度、長(zhǎng)度、耗時(shí)、次數(shù)等。
名目尺度屬性又稱為類別變量(此后屬性、特征、變量與變項(xiàng)會(huì)交替使用),順序尺度又稱為有序的類別變量,在R語(yǔ)言中兩者都稱為因子(factor),是R語(yǔ)言非常重要的一個(gè)類別,它決定數(shù)據(jù)如何被分析與可視化,例如,分類問(wèn)題建模時(shí)因變量必須為因子類別,又可視化時(shí)因子變量會(huì)按照其頻率分布(frequency distribution)產(chǎn)生直方圖與圓餅圖等。下例中函數(shù)factor()將字符串向量中的類別值對(duì)應(yīng)到[1,2,…,k]的整數(shù)值向量,其中k為名目變量中獨(dú)特值的個(gè)數(shù),統(tǒng)計(jì)術(shù)語(yǔ)稱為水平數(shù)(number of levels),名目變量的各個(gè)獨(dú)特值即為各水平(level)。因此,字符串向量與整數(shù)值的因子向量間有一對(duì)應(yīng)關(guān)系,默認(rèn)的對(duì)應(yīng)關(guān)系中字符串與整數(shù)值分別按照字母順序與大小升冪排列。以前面五位患者其糖尿病類型的字符串向量diabetes為例,轉(zhuǎn)換為因子向量的做法如下:

對(duì)于有序的類別變量,可在factor()函數(shù)中設(shè)定ordered的參數(shù)值為T(mén)RUE,形成R語(yǔ)言有序因子(ordered factor)對(duì)象。但此處患者康復(fù)狀況的類別值字母順序?yàn)镋xcellent, Improved與Poor,所以須用levels參數(shù)強(qiáng)制設(shè)定兩者的對(duì)應(yīng)關(guān)系如下(1=Poor,2=Improved,3=Excellent),表達(dá)數(shù)值越高,復(fù)原狀況越好。總結(jié)來(lái)說(shuō),因子變量的模式(mode)是數(shù)值的,但外表看來(lái)像字符串,如此貼心的設(shè)計(jì)是R語(yǔ)言特有的,Python語(yǔ)言需要自行編碼(參見(jiàn)1.4.3節(jié)Python語(yǔ)言類別變量編碼)。

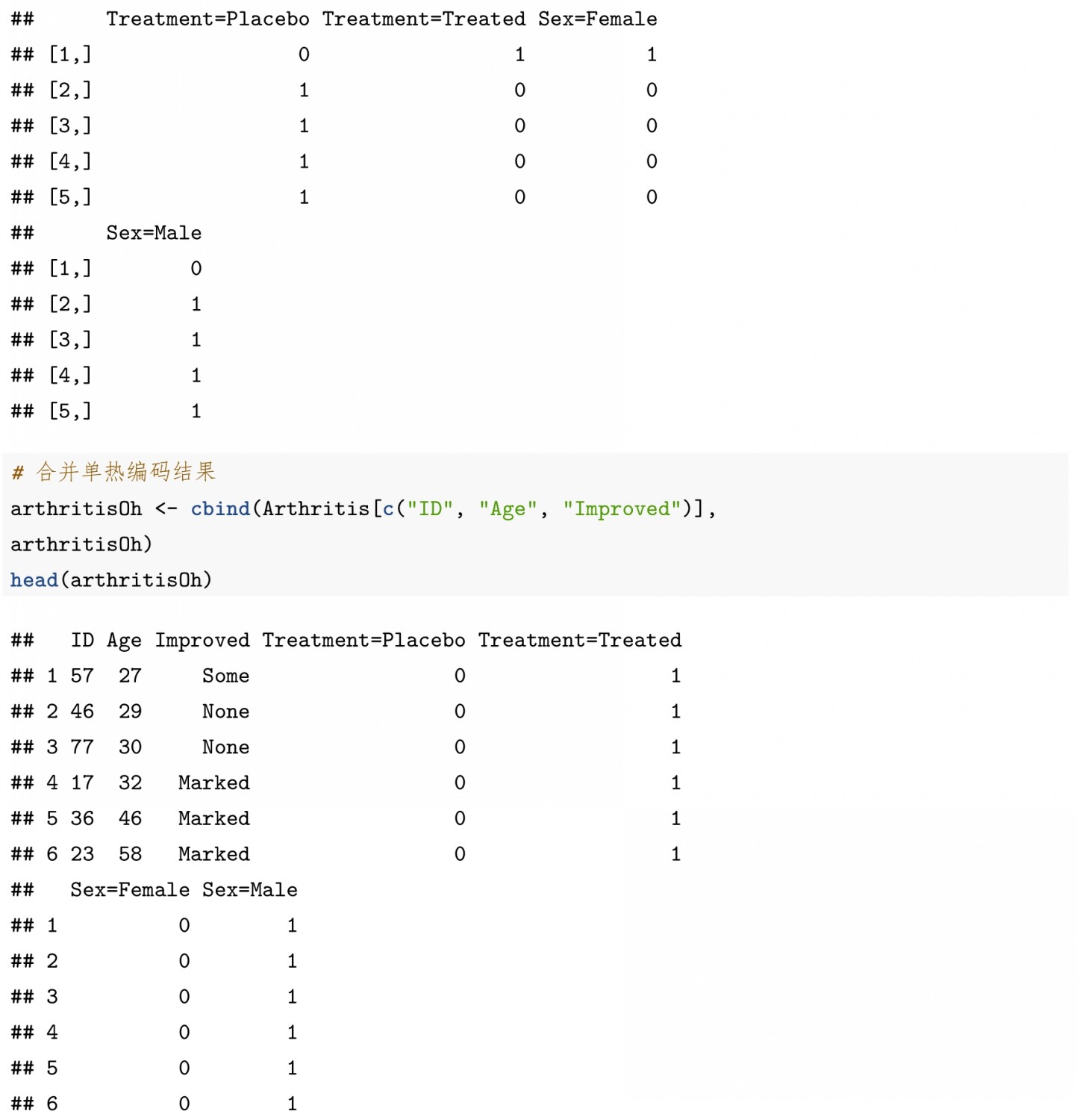
前述因子的編碼方式,是所謂的標(biāo)簽編碼(label encoding)。另一種常用的編碼方式單熱編碼(onehot encoding)與虛擬編碼(dummy encoding)相似,將原本單一的類別變量編碼成多個(gè)互相獨(dú)立的二元類別變量(independent binary categories)。此處以套件{vcd}中的關(guān)節(jié)炎Arthritis數(shù)據(jù)集為例,使用單熱編碼套件{onehot}先建立模型對(duì)象encoder,其類別值為onehot,再使用predict()泛型函數(shù)對(duì)Treatment與Sex兩字段進(jìn)行單熱編碼,最后再與未做單熱編碼的三個(gè)字段整合為數(shù)據(jù)集arthritisOh。因?yàn)門(mén)reatment與Sex均為兩水平的因子變量,整合后的表格共有7個(gè)(3未單熱編碼+2水平單熱編碼+2水平單熱編碼)變量。此處{onehot}套件單熱編碼過(guò)程與R語(yǔ)言機(jī)器學(xué)習(xí)建模過(guò)程相同,也是1.6.2節(jié)中Python語(yǔ)言模型擬合過(guò)程的精簡(jiǎn)版,請(qǐng)參考該節(jié)內(nèi)容及后面的建模案例。

總結(jié)來(lái)說(shuō),R語(yǔ)言的前身S語(yǔ)言是數(shù)據(jù)分析語(yǔ)言與統(tǒng)計(jì)運(yùn)算(statistical computing)環(huán)境的先驅(qū),大多數(shù)的情況下它們會(huì)將數(shù)據(jù)表中的字符串變量自動(dòng)編碼成因子變量,例如,read.csv()函數(shù)也可以通過(guò)stringsAsFactors參數(shù)的設(shè)定,自動(dòng)完成標(biāo)簽編碼,方便后續(xù)的統(tǒng)計(jì)計(jì)算。然而Python語(yǔ)言并非如此,許多Python套件并無(wú)這種自動(dòng)轉(zhuǎn)換的功能,數(shù)據(jù)導(dǎo)入Python后,通常須先進(jìn)行類別變量編碼的動(dòng)作。想同時(shí)使用R語(yǔ)言和Python語(yǔ)言的數(shù)據(jù)分析工作者請(qǐng)注意這種差異,以免導(dǎo)致無(wú)謂的錯(cuò)誤。1.4節(jié)介紹完P(guān)ython語(yǔ)言數(shù)據(jù)對(duì)象后,我們會(huì)舉例說(shuō)明Python類別變量編碼的工作流程。
- 極簡(jiǎn)算法史:從數(shù)學(xué)到機(jī)器的故事
- 軟件安全技術(shù)
- Java多線程編程實(shí)戰(zhàn)指南:設(shè)計(jì)模式篇(第2版)
- Selenium Design Patterns and Best Practices
- Java Web及其框架技術(shù)
- Banana Pi Cookbook
- Java Web基礎(chǔ)與實(shí)例教程
- Visual C#通用范例開(kāi)發(fā)金典
- Essential C++(中文版)
- Python開(kāi)發(fā)基礎(chǔ)
- Mastering HTML5 Forms
- 創(chuàng)意UI Photoshop玩轉(zhuǎn)移動(dòng)UI設(shè)計(jì)
- 虛擬現(xiàn)實(shí)建模與編程(SketchUp+OSG開(kāi)發(fā)技術(shù))
- INSTANT Premium Drupal Themes
- Mastering Python