- 深度強化學習算法與實踐:基于PyTorch的實現
- 張校捷編著
- 816字
- 2022-05-06 17:08:36
3.1.1 網格世界(Grid World)
在2.1節介紹了網格世界的概念,并且用它來闡釋了貪心算法和?-貪心算法。我們把2.1節中使用的網格世界推廣一下,增加一些元素,讓這個強化學習環境更具有普適性。
下面簡單回顧一下網格世界這個強化學習環境。顧名思義,網格世界由很多網格組成,智能體在某一時刻處于這些網格的一個網格中,并且可以在相鄰的網格中進行移動。在決策過程中,每一步智能體都能選擇跳轉的目標網格,并且在跳轉之后能夠獲取網格世界環境的獎勵,而且到達目標網格。智能體在這個強化學習環境中的目標是盡可能獲取更多的獎勵。
在2.1節中介紹的模型只是一個簡單的模型,實際上網格世界的模型可以變得非常復雜。
首先,可以很容易地看到,網格世界的復雜度是隨著網格數目增加而逐漸增加的,一旦網格數目快速增加,對應的狀態價值函數的復雜程度也會隨著狀態數目的增加而快速增加。
其次,在網格世界中,可以對網格定義不同的相鄰關系,在2.1節的例子中可以觀察到不同網格位置的跳轉,事實上對于網格世界的任意兩個網格都可以定義跳轉關系,這樣隨著跳轉關系數目的增加,整體上智能體對于環境的搜索難度也會大大增加。除了增加跳轉關系,還可以設定一些規則,規定某些網格不能進入,這樣就相當于在網格世界環境中人為制造了一些空洞,從而增加了智能體搜索的復雜性。
最后,可以給到達不同的位置設置不同的獎勵,不同位置獎勵的數目越多,智能體找到最優路徑需要搜索的可能路徑也會越多,這樣同樣增加了環境的復雜性。
圖3.1是一個相對復雜的網格世界的強化學習環境,這個環境簡單展示了前面介紹的三點,其中,箭頭代表智能體到達某個網格點后的跳轉方向,陰影部分為禁止進入區域,數字部分代表到達某個網格點能夠獲取的獎勵。讀者可以試著構建更復雜的網格世界,并且按照2.1節的例子中類似的代碼,把這個強化學習環境轉化為Python代碼。當然,也可以試著在這個網格世界的強化學習環境中運行各種基于策略迭代和值迭代的強化學習算法。
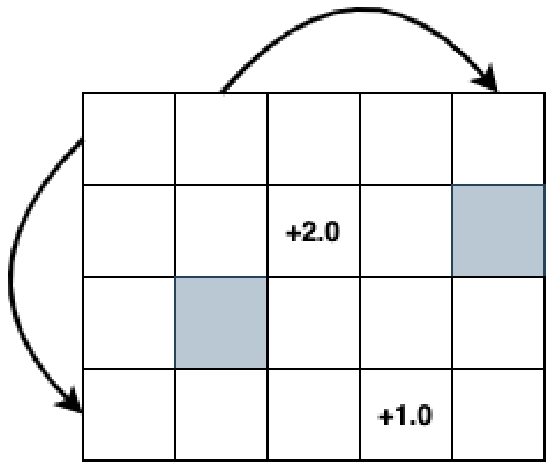
圖3.1 一個4×5的網格世界強化學習環境示意圖
- Oracle 12c中文版數據庫管理、應用與開發實踐教程 (清華電腦學堂)
- Getting Started with Laravel 4
- RabbitMQ Essentials
- Spring核心技術和案例實戰
- Test-Driven Machine Learning
- Vue.js 2 Web Development Projects
- Beginning C++ Game Programming
- Django 5企業級Web應用開發實戰(視頻教學版)
- Python趣味編程與精彩實例
- CodeIgniter Web Application Blueprints
- IPython Interactive Computing and Visualization Cookbook
- Java高并發編程詳解:深入理解并發核心庫
- Python預測之美:數據分析與算法實戰(雙色)
- Learning Ionic(Second Edition)
- 前端Serverless:面向全棧的無服務器架構實戰