- Java并發(fā)編程深度解析與實戰(zhàn)
- 譚鋒(Mic)
- 4869字
- 2022-05-10 18:39:19
3.2 深度理解可見性問題的本質(zhì)
實際上,除編譯器優(yōu)化帶來的可見性問題外,還有很多因素會導致可見性問題,比如CPU高速緩存、CPU指令及重排序等,為了徹底搞懂可見性的本質(zhì),下面我們圍繞硬件及操作系統(tǒng)層面的優(yōu)化進行分析。
3.2.1 如何最大化提升CPU利用率
CPU是計算機最核心的資源,它主要用來解釋計算機指令及處理計算機軟件中的數(shù)據(jù)。當程序加載到內(nèi)存中后,操作系統(tǒng)會把當前進程分配給指定的CPU執(zhí)行,在獲得CPU執(zhí)行權(quán)后,CPU從內(nèi)存中取出指令進行解碼,并執(zhí)行,然后取出下一個指令解碼,再次執(zhí)行。
CPU在做運算時,無法避免地要從內(nèi)存中讀取數(shù)據(jù)和指令,CPU的運算速度遠遠高于內(nèi)存的I/O速度,比如一個支持2.6GHz主頻的CPU,每秒可以執(zhí)行2.6x109次,相當于每個指令只需要0.38ns。而從內(nèi)存中讀寫一個數(shù)據(jù),每次尋址需要100ns,很顯然兩者的速度差異非常大,CPU和內(nèi)存之間的這個速度瓶頸被稱為馮諾依曼瓶頸。雖然計算機在不斷地迭代升級(比如CPU的處理性能越來越快、內(nèi)存容量越來越大、內(nèi)存的I/O效率也在不斷提升),但是這個核心的矛盾無法消除。
如圖3-1所示,CPU在做計算時必須與內(nèi)存交互,即便是存儲在磁盤上的數(shù)據(jù),也必須先加載到內(nèi)存中,CPU才能訪問。也就是說,CPU和內(nèi)存之間存在無法避免的I/O操作。
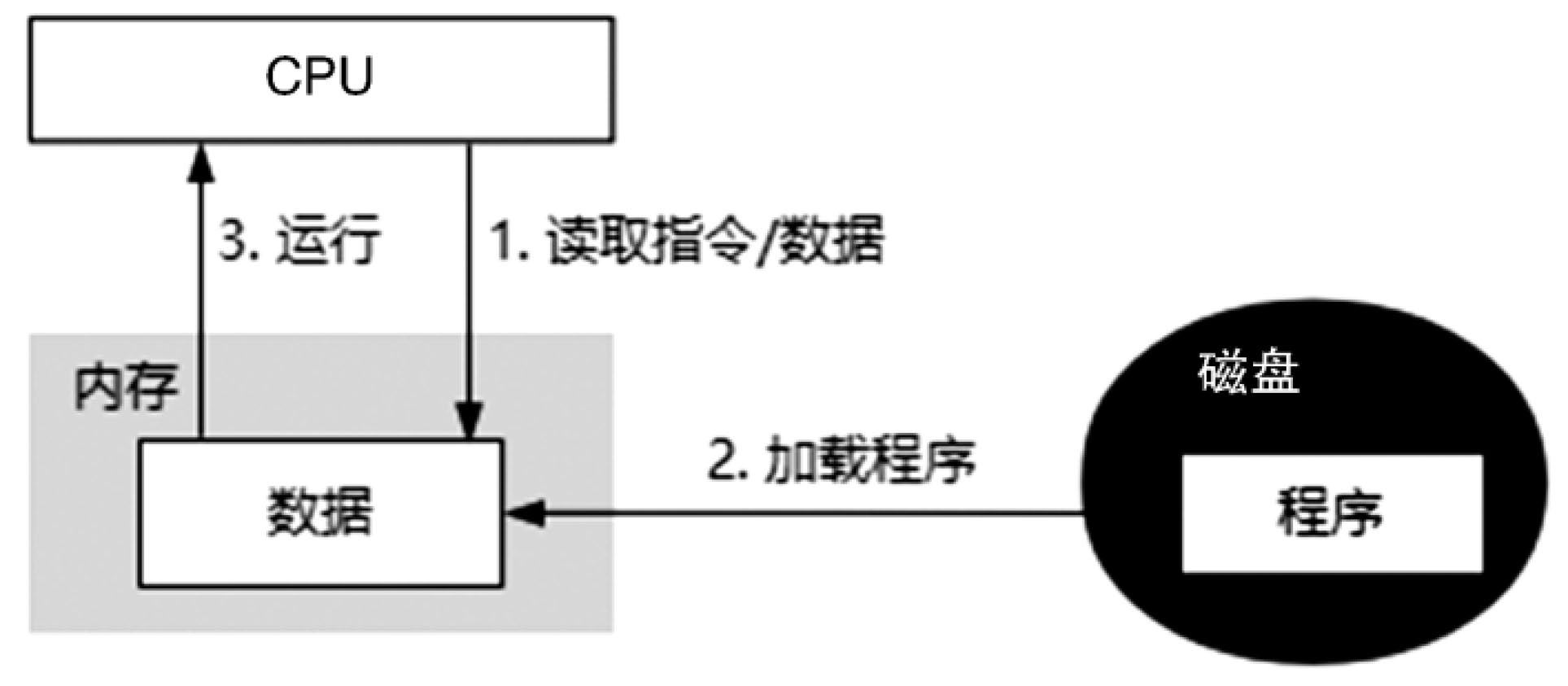
圖3-1 CPU的執(zhí)行過程
基于上述的分析可以看到,當CPU向內(nèi)存發(fā)起一個讀操作時,在等待內(nèi)存返回之前,CPU都處于等待狀態(tài),直到返回之后CPU繼續(xù)運行下一個指令,這個過程很顯然會導致CPU資源的浪費。為了解決這個問題,開發(fā)者在硬件設備、操作系統(tǒng)及編譯器層面做了很多優(yōu)化。
? 在CPU層面增加了寄存器,來保存一些關鍵變量和臨時數(shù)據(jù),還增加了CPU高速緩存,以減少CPU和內(nèi)存的I/O等待時間。
? 在操作系統(tǒng)層面引入了進程和線程,也就是說在當前進程或線程處于阻塞狀態(tài)時,CPU會把自己的時間片分配給其他線程或進程使用,從而減少CPU的空閑時間,最大化地提升CPU的使用率。
? 在編譯器層面增加指令優(yōu)化,減少與內(nèi)存的交互次數(shù)。
以上這些優(yōu)化的目的是提升CPU利用率,但是恰恰也是這些優(yōu)化導致了可見性問題的發(fā)生,下面我們進行展開分析。
3.2.2 詳述CPU高速緩存
CPU和內(nèi)存的I/O操作是無法避免的,為了降低內(nèi)存的I/O耗時,開發(fā)者在CPU中設計了高速緩存,用存儲與內(nèi)存交互的數(shù)據(jù)。CPU在做讀操作時,會先從高速緩存中讀取目標數(shù)據(jù),如果目標數(shù)據(jù)不存在,就會從內(nèi)存中加載目標數(shù)據(jù)并保存到高速緩存中,再返回給處理器。
在主流的X86架構(gòu)的處理器中,CPU高速緩存通常分為L1、L2、L3三級,它的具體結(jié)構(gòu)如圖3-2所示。
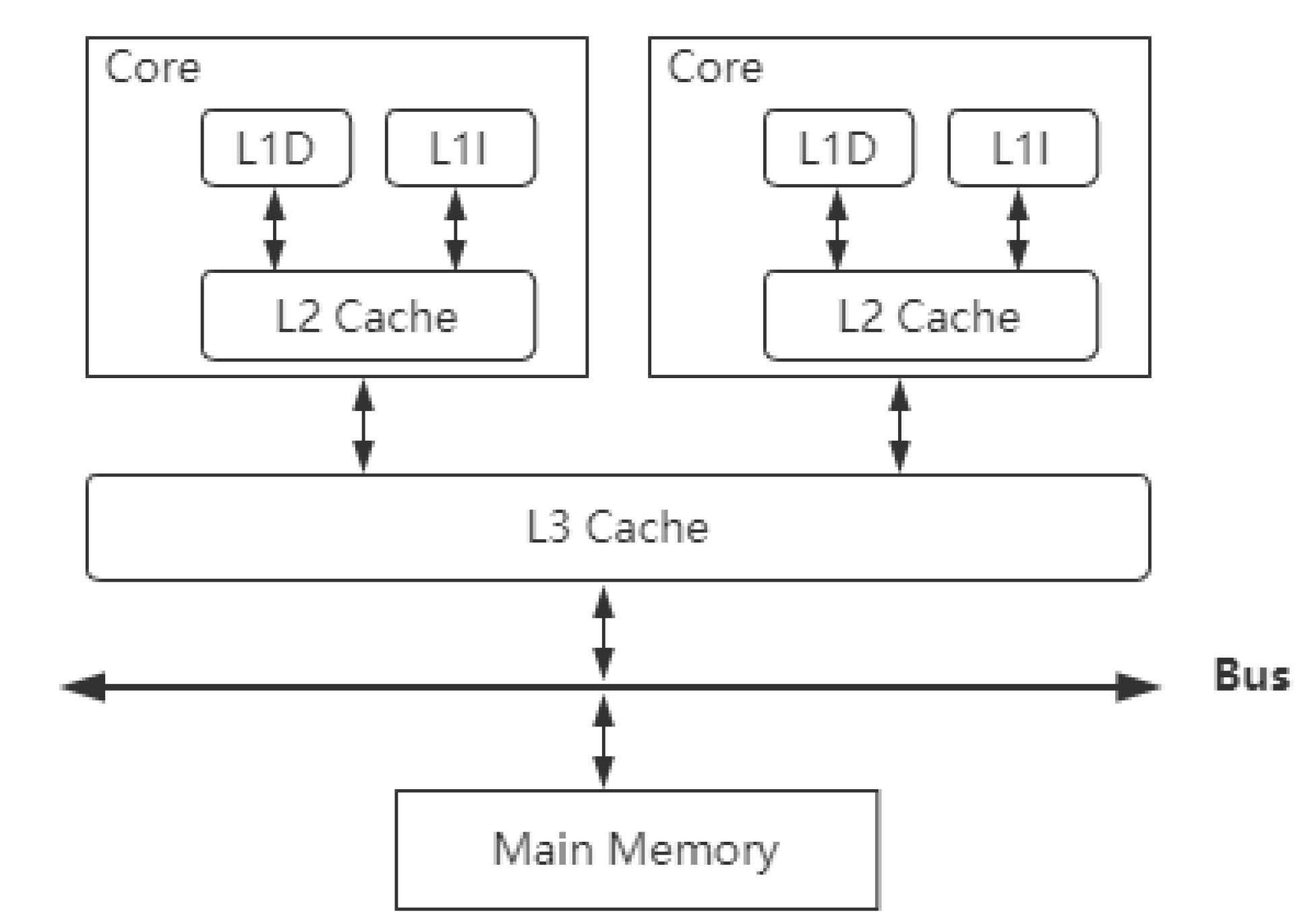
圖3-2 CPU高速緩存的結(jié)構(gòu)
圖3-2展示了CPU高速緩存的結(jié)構(gòu),L1和L2緩存是CPU核內(nèi)的緩存,是屬于CPU私有的。L3是跨CPU核心共享的緩存,其中L1緩存又分為L1D一級數(shù)據(jù)緩存、L1I一級指令緩存,這三級緩存的大小和緩存的訪問速度排列為L1 > L2 > L3。
? L1是CPU硬件上的一塊緩存,它分為數(shù)據(jù)緩存和指令緩存(指令緩存用來處理CPU必須要執(zhí)行的操作信息,數(shù)據(jù)緩存用來存儲CPU要操作的數(shù)據(jù)),它的容量最小但是速度最快,容量一般在256KB左右,好一點的CPU可以達到1MB以上。
? L2也是CPU硬件上的一塊緩存,相比L1緩存來說,容量會大一些,但是速度相對來說會慢,容量通常在256KB到8MB之間。
? L3是CPU高速緩存中最大的一塊,也是訪問速度最慢的緩存,它的容量在4MB到50MB之間,它是所有CPU核心共享的一塊緩存。
當CPU讀取數(shù)據(jù)時,會先嘗試從L1緩存中查找,如果L1緩存未命中,繼續(xù)從L2和L3緩存中查找,如果在緩存行中沒有命中到目標數(shù)據(jù),最終會訪問內(nèi)存。內(nèi)存中加載的數(shù)據(jù)會依次從內(nèi)存流轉(zhuǎn)到L3緩存,再到L2緩存,最后到L1緩存。當后續(xù)再次訪問存在于緩存行中的數(shù)據(jù)時,CPU可以不需要訪問內(nèi)存,從而提升CPU的I/O效率。
3.2.2.1 關于緩存行的實現(xiàn)
如圖3-3所示,CPU的高速緩存是由若干緩存行組成的,緩存行是CPU高速緩存的最小存儲單位,也是CPU和內(nèi)存交換數(shù)據(jù)的最小單元。在x86架構(gòu)中,每個緩存行大小為64位,即8字節(jié),CPU每次從內(nèi)存中加載8字節(jié)的數(shù)據(jù)作為一個緩存行保存到高速緩存中,這意味著高速緩存中存放的是連續(xù)位置的數(shù)據(jù),這是基于空間局部性原理的實現(xiàn)。
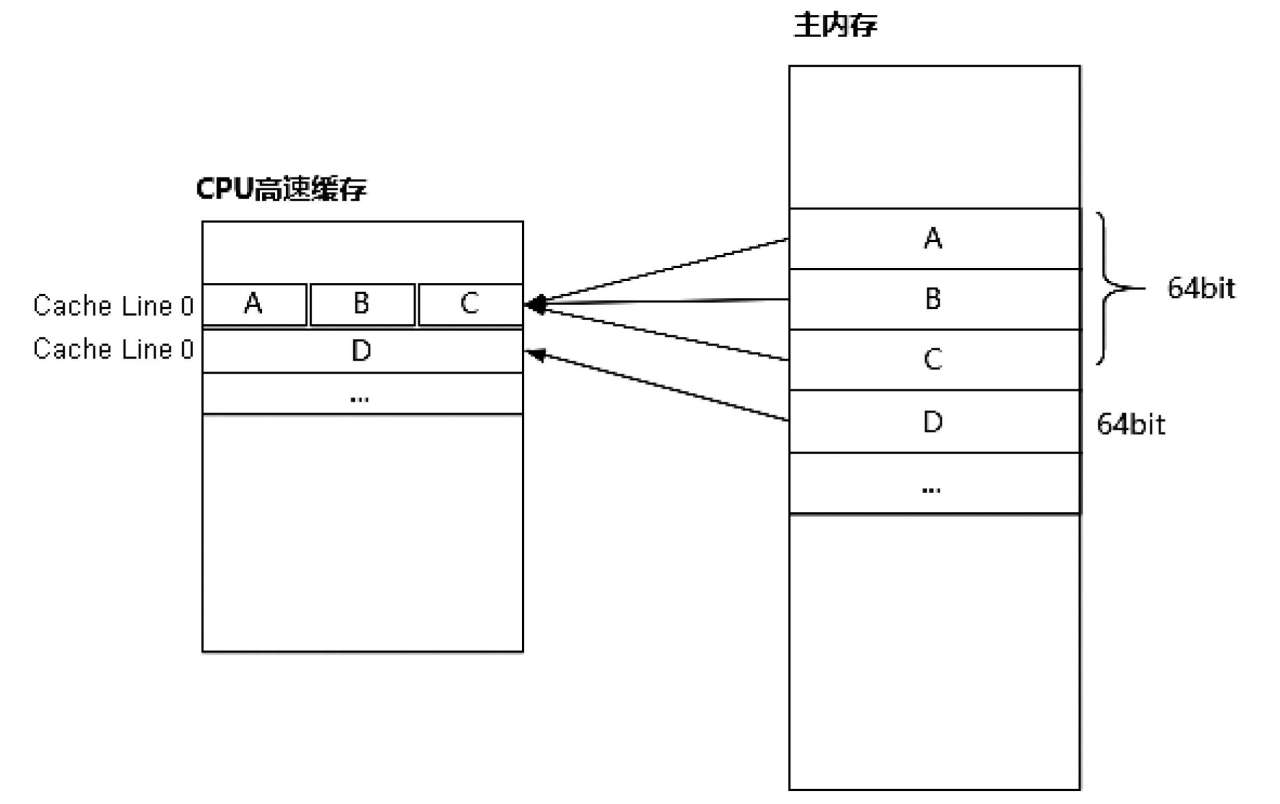
圖3-3 緩存行原理簡圖
空間局部性原理是指,如果一個存儲器的位置被引用,那么將來它附近的位置也會被引用,這種緩存行讀取的方式能夠減少與內(nèi)存的交互次數(shù),提升CPU利用率,從而節(jié)省CPU讀取數(shù)據(jù)的時間。
3.2.2.2 緩存行導致的偽共享問題
在緩存行的加載方式下,當CPU從內(nèi)存加載數(shù)據(jù)到緩存行時,會把臨近的64位數(shù)據(jù)一起保存到緩存行中。基于空間局部性原理,CPU在讀取第二個數(shù)據(jù)時發(fā)現(xiàn)該數(shù)據(jù)已經(jīng)存在于緩存行中,因此不需要再去內(nèi)存中尋址了,可以直接從緩存中獲取數(shù)據(jù)。
比如,在Java中,一個long類型是8字節(jié),因此一個緩存行中可以存8個long類型的變量,假設當前訪問的是一個long類型數(shù)組,當數(shù)組中的一個值被加載到緩存中時,也會同步加載另外7個。因此,CPU可以減少與內(nèi)存的交互,快速完成這些數(shù)據(jù)的計算,這是緩存行的優(yōu)勢。
假設存在這樣一種情況:有兩個線程,分別訪問上述long類型數(shù)組的不同的值,比如線程A訪問long[1],線程B訪問long[4],由于緩存行的機制使得兩個CPU的高速緩存會共享同一個緩存行,為了保證緩存的一致性,CPU會不斷使緩存行失效,并重新加載到高速緩存。如果這兩個線程競爭非常激烈,就會導致緩存頻繁失效,這就是典型的偽共享問題。
如圖3-4所示,CPU0要從主內(nèi)存中加載X變量,CPU1要從主內(nèi)存中加載Y變量,如果X/Y/Z都在同一個緩存行中,那么CPU0和CPU1都會把這個緩存行加載到高速緩存中。如果CPU1先執(zhí)行了對X變量的修改,那么基于緩存一致性協(xié)議,會使得CPU1中的緩存行失效。接著CPU1執(zhí)行對X變量的修改,發(fā)現(xiàn)緩存行已經(jīng)失效了,此時需要再次從主內(nèi)存中加載該緩存行進行修改,而CPU1的這個修改也會導致CPU0中的緩存行失效,基于這樣的方式不斷循環(huán)運行。這個問題最終導致的結(jié)果就是程序的處理性能會大大降低。
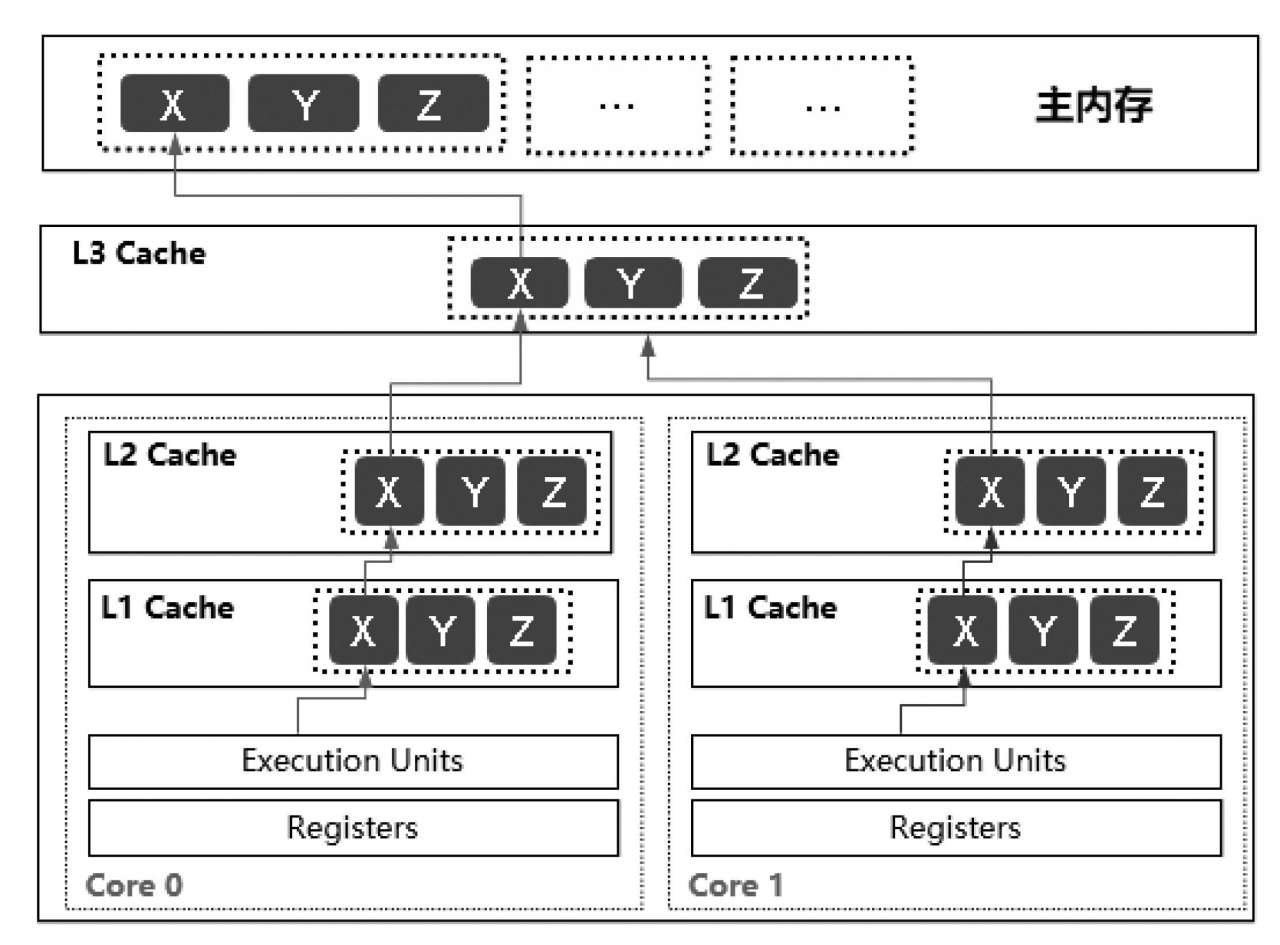
圖3-4 緩存行的偽共享問題
為了更加直觀地理解偽共享問題,我們來看下面這個例子。


上述代碼的核心功能就是,通過創(chuàng)建多個線程并對共享對象的值進行修改,來模擬偽共享的問題,代碼中定義了如下兩個靜態(tài)類。
? ValuePadding,針對成員變量value做了對齊填充,其中p1、p2、p3、p4、p5、p6、p7作為前置填充,p9、p10、p11、p12、p13、p14、p15作為后置填充。之所以要做前后置填充,就是為了使value不管在哪個位置,都能夠保證它處于不同的緩存行中,避免出現(xiàn)偽共享問題。
? ValueNoPadding,沒有做對齊填充。
運行上述代碼,執(zhí)行結(jié)果如下。


下面把實例對象改成ValuePadding,代碼如下。

運行結(jié)果如下:

可以很明顯地發(fā)現(xiàn),做了緩存行填充的程序,其運行效率提高了近10倍。
3.2.2.3 @Contended
JDK 1.8提供了@Contended注解,該注解的作用是實現(xiàn)緩存行填充,解決偽共享的問題。
@Contended注解可以添加在類上,也可以添加在字段上,當添加在字段上時,可以保證該字段處于一個獨立的緩存行中。在使用時,為了確保@Contended注解生效,我們需要配置一個JVM運行時參數(shù):

類級別和字段級別修飾的使用方法如下。

@Contended注解還支持一個contention group屬性(針對字段級別),同一個group的多個字段在內(nèi)存上是連續(xù)存儲的,并且能和其他字段隔離開來。

上述代碼就是把value和value1字段放在了同一個group中,這意味著這兩個字段會放在同一個緩存行,并且和其他字段進行緩存行隔離。而value2沒有做填充,如果對value2進行更新,則仍然會存在偽共享問題。
3.2.3 CPU緩存一致性問題
CPU高速緩存的設計極大地提升了CPU的運算性能(從FalseSharingExample這個例子就可以看出來),但是它存在一個問題:在CPU中的L1和L2緩存是CPU私有的,如果兩個線程同時加載同一塊數(shù)據(jù)并保存到高速緩存中,再分別進行修改,那么如何保證緩存的一致性呢?
如圖3-5所示,兩個CPU的高速緩存中都緩存了x=20這個值,其中CPU1將x=20修改成了x=40,這個修改只對本地緩存可見,而當CPU0后續(xù)對x再進行運算時,它獲取的值仍然是20,這就是緩存不一致的問題。
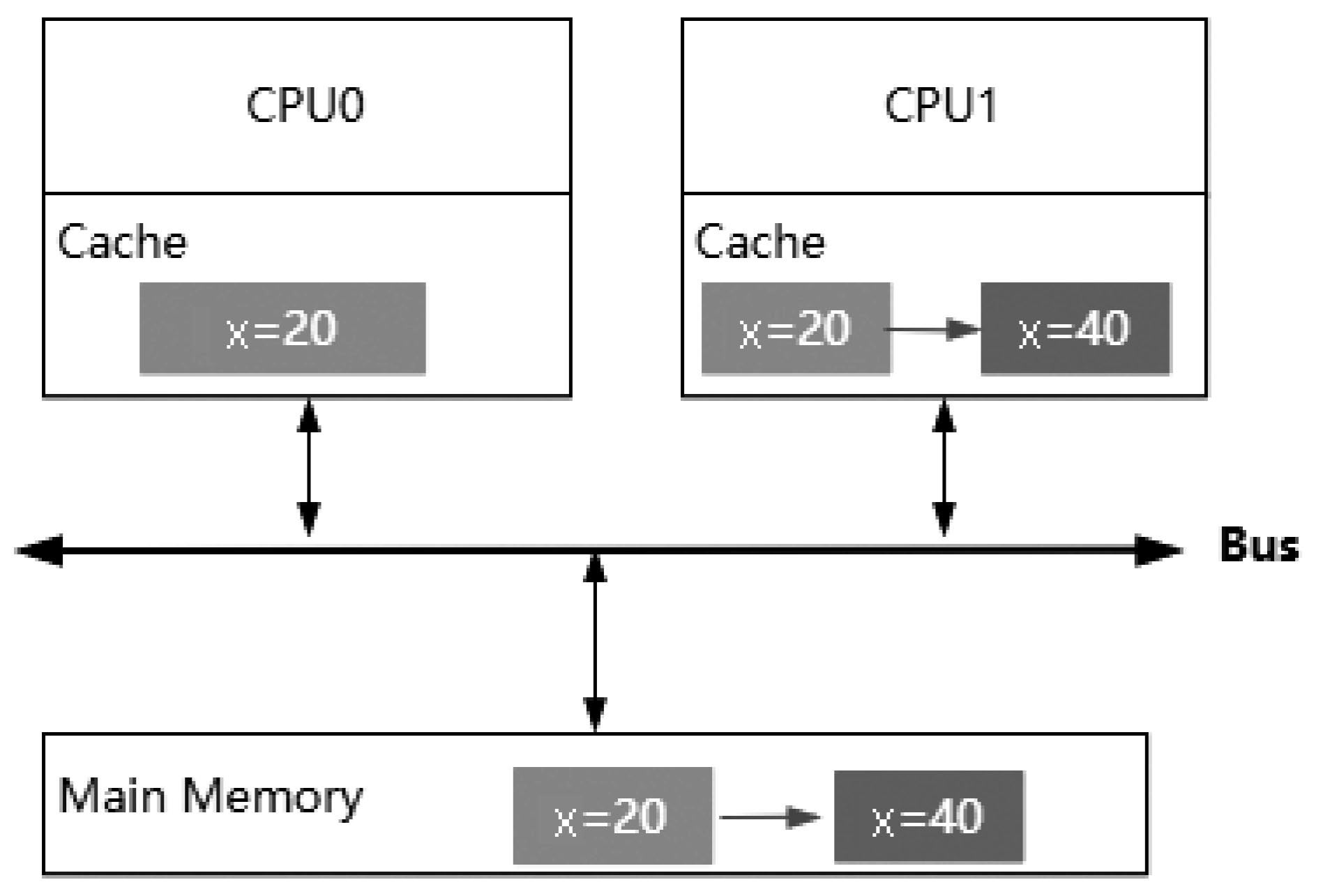
圖3-5 CPU緩存一致性問題
3.2.3.1 總線鎖和緩存鎖機制
為了解決緩存一致性問題,開發(fā)者在CPU層面引入了總線鎖和緩存鎖機制。
在了解鎖之前,我們先介紹一下總線。所謂的總線,就是CPU與內(nèi)存、輸入/輸出設備傳遞信息的公共通道(也叫前端總線),當CPU訪問內(nèi)存進行數(shù)據(jù)交互時,必須經(jīng)過總線來傳輸,那么什么是總線鎖呢?
簡單來說,總線鎖就是在總線上聲明一個Lock#信號,這個信號能夠確保共享內(nèi)存只有當前CPU可以訪問,其他的處理器請求會被阻塞,這就使得同一時刻只有一個處理能夠訪問共享內(nèi)存,從而解決了緩存不一致的問題。但是這種做法產(chǎn)生的代價是,CPU的利用率直線下降,很顯然這是無法讓人接受的,于是從P6系列的處理器開始增加了緩存鎖的機制。
緩存鎖指的是,如果當前CPU訪問的數(shù)據(jù)已經(jīng)緩存在其他CPU的高速緩存中,那么CPU不會在總線上聲明Lock#信號,而是采用緩存一致性協(xié)議來保證多個CPU的緩存一致性。
CPU最終用哪種鎖來解決緩存一致性問題,取決于當前CPU是否支持緩存鎖,如果不支持,就會采用總線鎖。還有一種情況是,當前操作的數(shù)據(jù)不能被緩存在處理器內(nèi)部,或者操作的數(shù)據(jù)跨多個緩存行時,也會使用總線鎖。
3.2.3.2 緩存一致性協(xié)議
緩存鎖通過緩存一致性協(xié)議來保證緩存的一致性,不同的CPU類型支持的緩存一致性協(xié)議也有區(qū)別,比如MSI、MESI、MOSI、MESIF協(xié)議等,比較常見的是MESI(Modified Exclusive Shared Or Invalid)協(xié)議。
具體來說,MESI協(xié)議表示緩存行的四種狀態(tài),分別是:
? M(Modify),表示共享數(shù)據(jù)只緩存在當前CPU緩存中,并且是被修改狀態(tài),緩存的數(shù)據(jù)和主內(nèi)存中的數(shù)據(jù)不一致。
? E(Exclusive),表示緩存的獨占狀態(tài),數(shù)據(jù)只緩存在當前CPU緩存中,并且沒有被修改。
? S(Shared),表示數(shù)據(jù)可能被多個CPU緩存,并且各個緩存中的數(shù)據(jù)和主內(nèi)存數(shù)據(jù)一致。
? 4.I(Invalid),表示緩存已經(jīng)失效。
這四種狀態(tài)會基于CPU對緩存行的操作而產(chǎn)生轉(zhuǎn)移,所以MESI協(xié)議針對不同的狀態(tài)添加了不同的監(jiān)聽任務。
? 如果一個緩存行處于M狀態(tài),則必須監(jiān)聽所有試圖讀取該緩存行對應的主內(nèi)存地址的操作,如果監(jiān)聽到有這類操作的發(fā)生,則必須在該操作執(zhí)行之前把緩存行中的數(shù)據(jù)寫回主內(nèi)存。
? 如果一個緩存行處于S狀態(tài),那么它必須要監(jiān)聽使該緩存行狀態(tài)設置為Invalid或者對緩存行執(zhí)行Exclusive操作的請求,如果存在,則必須要把當前緩存行狀態(tài)設置為Invalid。
? 如果一個緩存行處于E狀態(tài),那么它必須要監(jiān)聽其他試圖讀取該緩存行對應的主內(nèi)存地址的操作,一旦有這種操作,那么該緩存行需要設置為Shared。
這個監(jiān)聽過程是基于CPU中的Snoopy嗅探協(xié)議來完成的,該協(xié)議要求每個CPU緩存都可以監(jiān)聽到總線上的數(shù)據(jù)事件并做出相應的反應,具體的通信原理如圖3-6所示,所有CPU都會監(jiān)聽地址總線上的事件,當某個處理器發(fā)出請求時,其他CPU會監(jiān)聽到地址總線的請求,根據(jù)當前緩存行的狀態(tài)及監(jiān)聽的請求類型對緩存行狀態(tài)進行更新。
為了讓大家更好地理解MESI協(xié)議的工作原理,我們在本書配套源碼的concurrent-chapter-3模塊的resource目錄下放了一個針對MESI狀態(tài)變更的動畫,讀者可以下載下來演示。
在基于嗅探協(xié)議實現(xiàn)緩存一致性的過程中涉及的消息類型如圖3-7所示,CPU根據(jù)不同的消息類型進行不同的處理,以實現(xiàn)緩存的一致性。
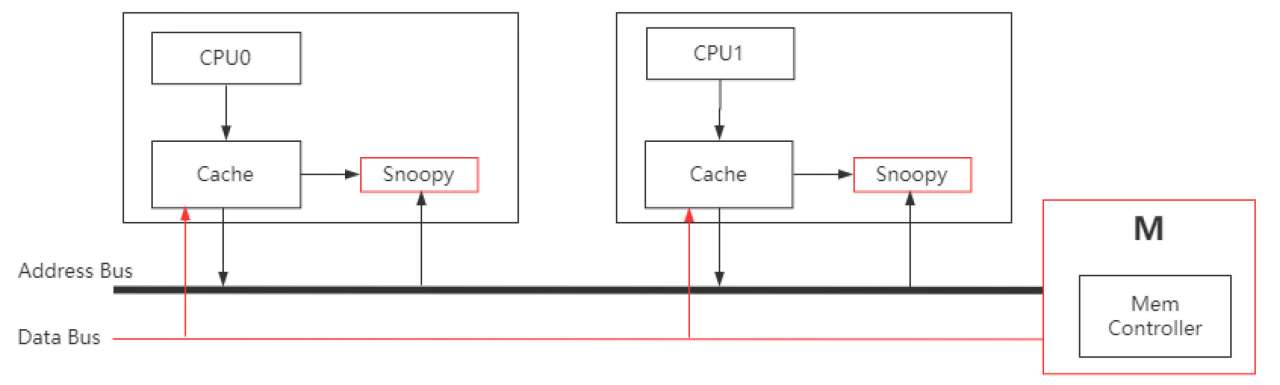
圖3-6 CPU通信原理
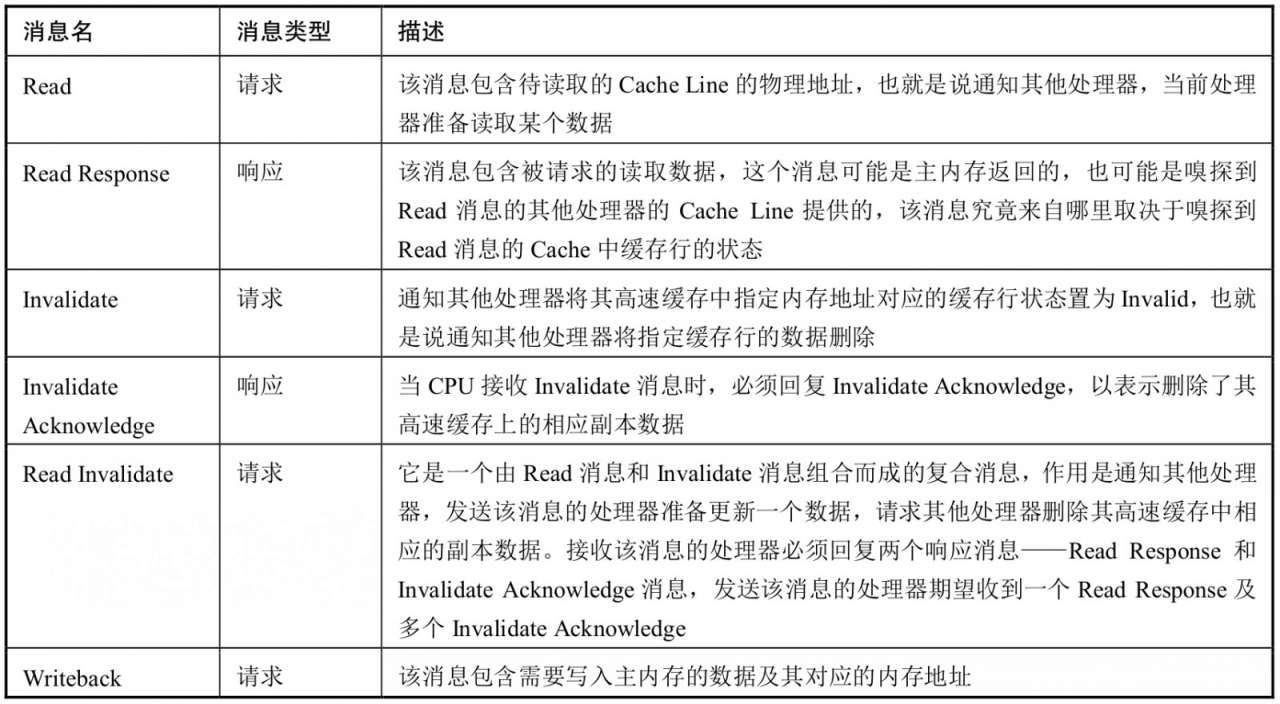
圖3-7 消息類型
理解了MESI協(xié)議的基本原理之后,我們通過一個簡圖來了解一下MESI協(xié)議是如何協(xié)助處理器來實現(xiàn)緩存一致性的。
如圖3-8所示,當單個CPU從主內(nèi)存中讀取一個數(shù)據(jù)保存到高速緩存中時,具體的流程是,CPU0發(fā)出一條從內(nèi)存中讀取x變量的指令,主內(nèi)存通過總線返回數(shù)據(jù)后緩存到CPU0的高速緩存中,并且設置該緩存狀態(tài)為E。
如圖3-9所示,此時如果CPU1同樣發(fā)出一條針對x的讀取指令,那么當CPU0檢測到緩存地址沖突時就會針對該消息做出響應,將緩存在CPU0中的x的值通過Read Response消息返回給CPU1,此時x分別存在于CPU0和CPU1的高速緩存中,所以x的狀態(tài)被設置為S。
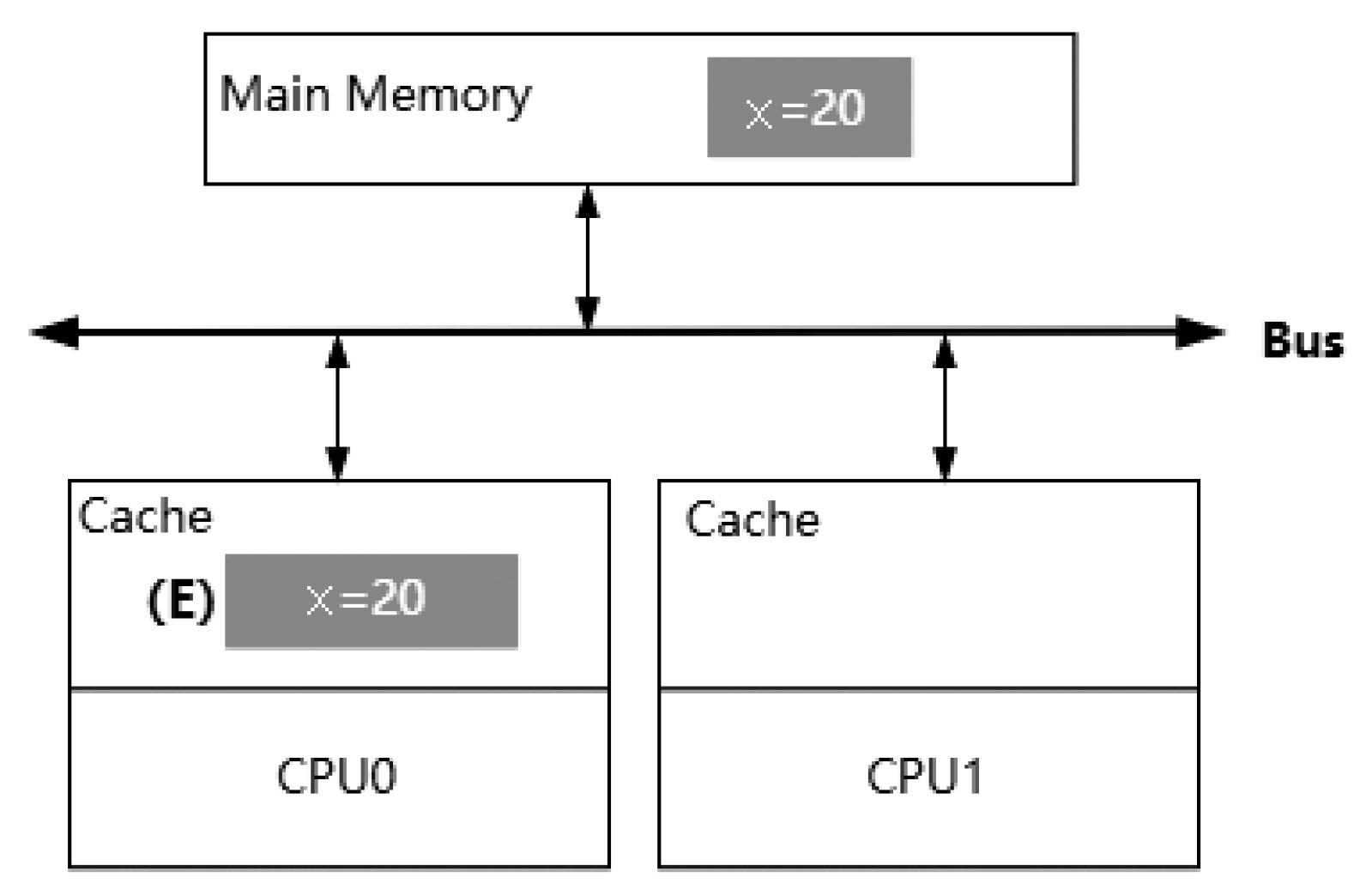
圖3-8 單個CPU讀取內(nèi)存數(shù)據(jù)
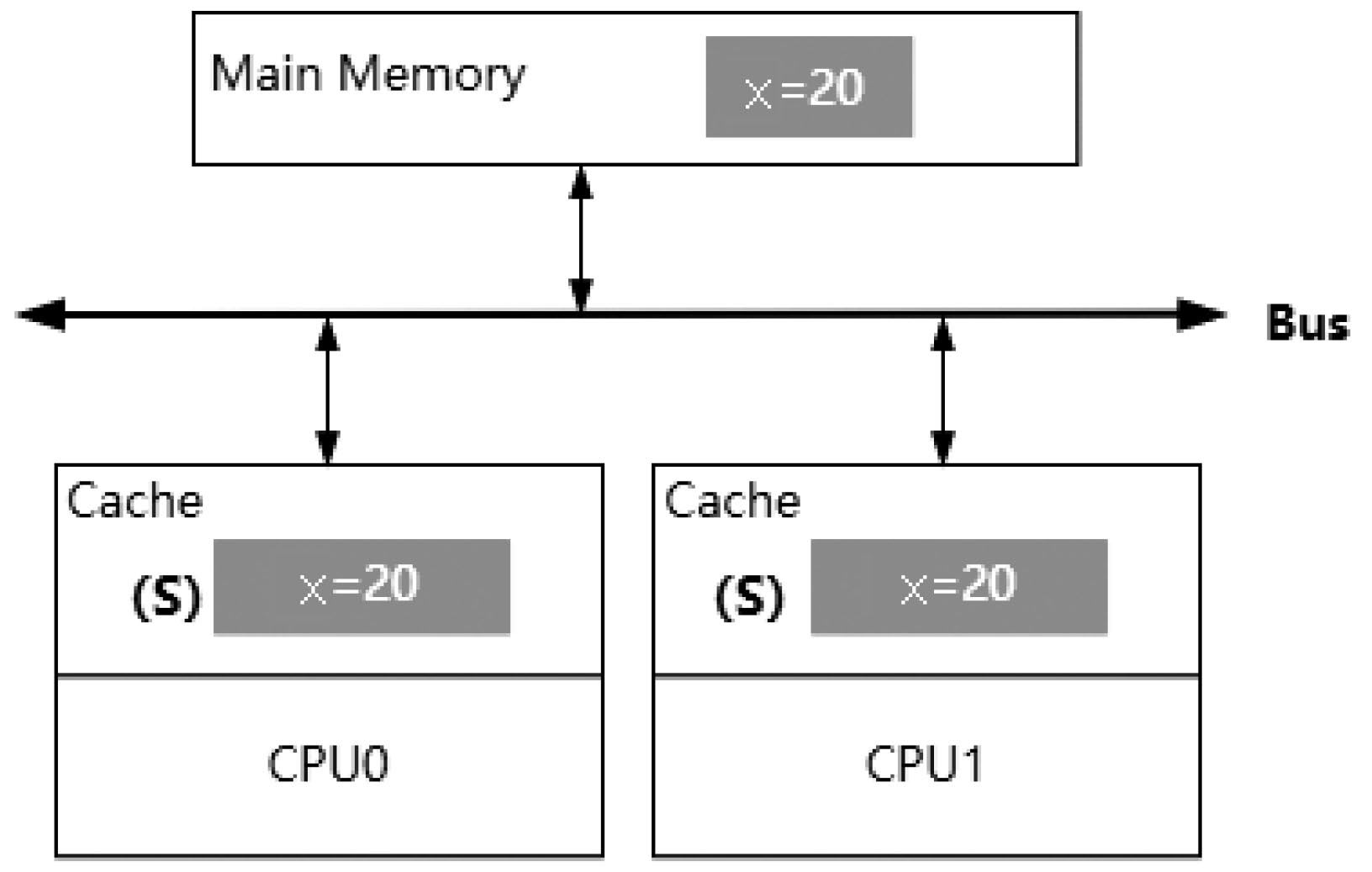
圖3-9 多個CPU同時讀取相同的數(shù)據(jù)
然后,CPU0把x變量的值修改成x=30,把自己的緩存行狀態(tài)設置為E。接著,把修改后的值寫入內(nèi)存中,此時x的緩存行是共享狀態(tài),同時需要發(fā)送一個Invalidate消息給其他緩存,CPU1收到該消息后,把高速緩存中的x置為Invalid狀態(tài),最終得到如圖3-10所示的結(jié)構(gòu)。
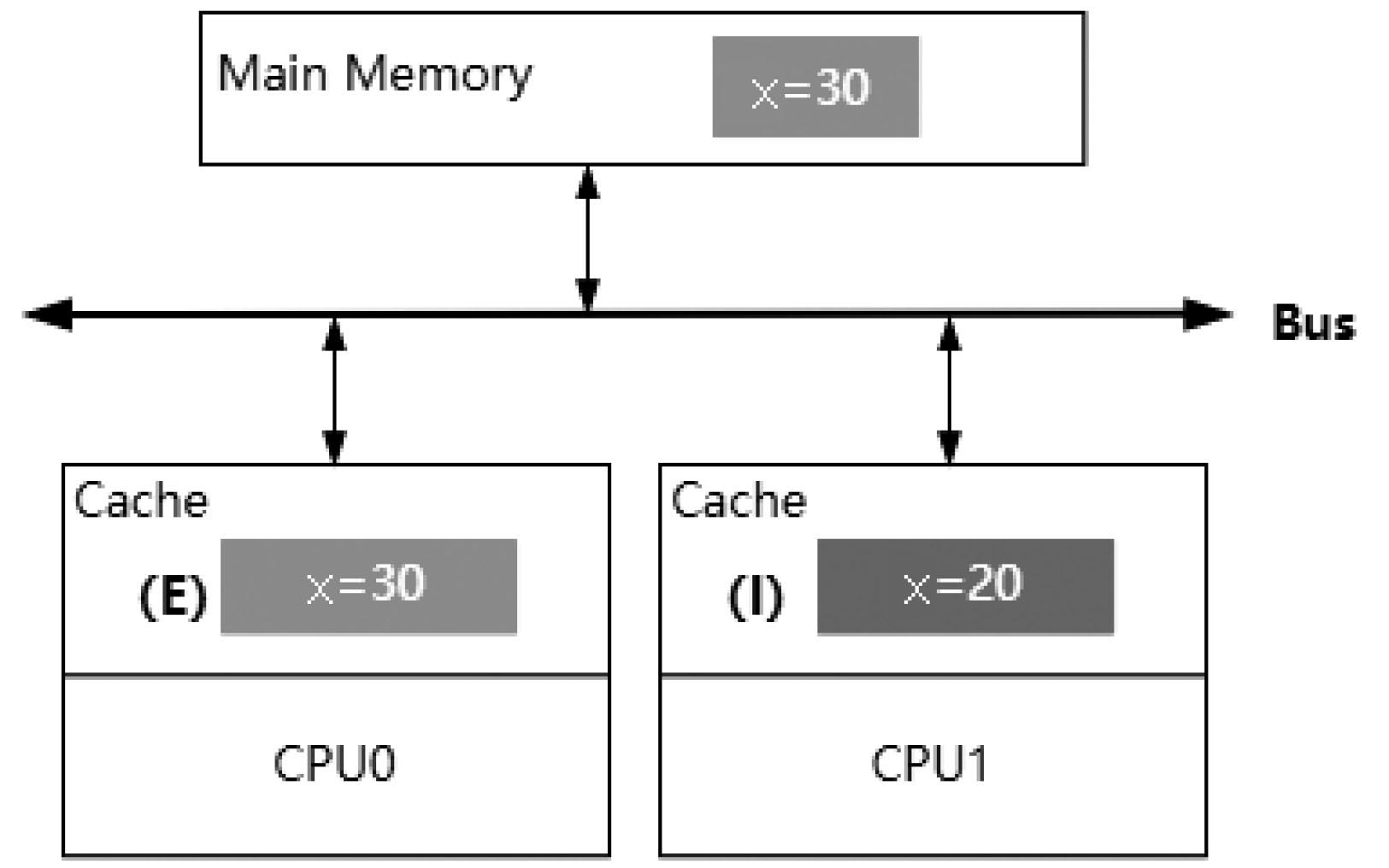
圖3-10 緩存行修改
3.2.4 總結(jié)可見性問題的本質(zhì)
至此,我們基本上理解了部分可見性問題的本質(zhì),CPU高速緩存的設計導致了緩存一致性問題,為了解決這一問題,開發(fā)者在CPU層面提供了總線鎖和緩存鎖的機制。
總線鎖和緩存鎖通過Lock#信號觸發(fā),如果當前CPU支持緩存鎖,則不會在總線上聲明Lock#信號,而是基于緩存一致性協(xié)議來保證緩存的一致性。如果CPU不支持緩存鎖,則會在總線上聲明Lock#信號鎖定總線,從而保證同一時刻只允許一個CPU對共享內(nèi)存的讀寫操作。緩存一致性保證如圖3-11所示。
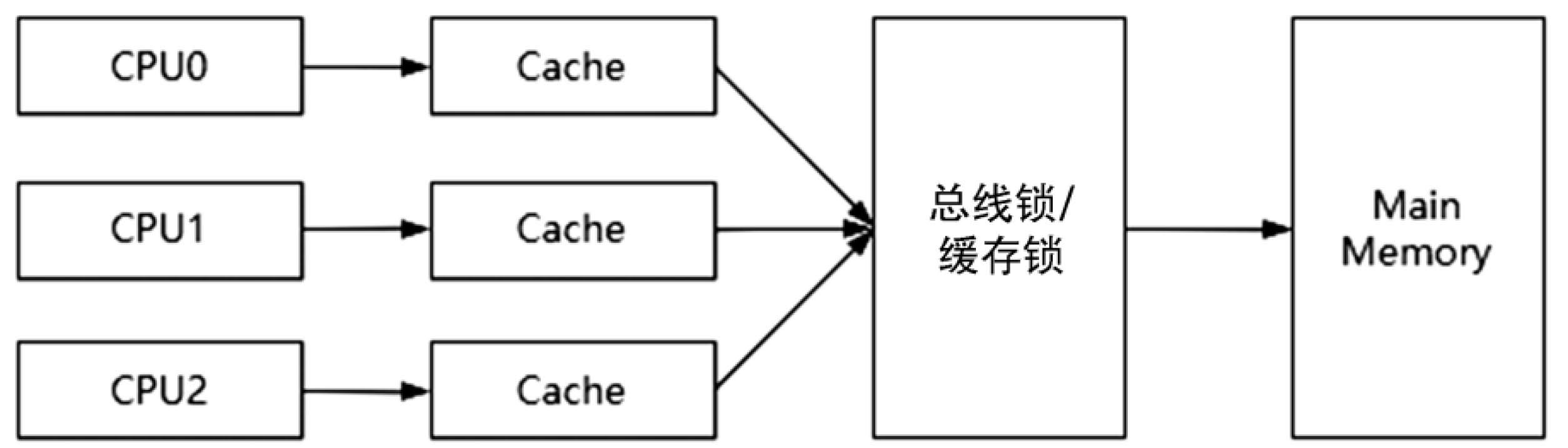
圖3-11 緩存一致性保證
- 大學計算機基礎(第二版)
- Instant Apache Stanbol
- HTML5 移動Web開發(fā)從入門到精通(微課精編版)
- Python計算機視覺編程
- Hands-On JavaScript High Performance
- Troubleshooting PostgreSQL
- PHP+MySQL+Dreamweaver動態(tài)網(wǎng)站開發(fā)實例教程
- Visual C++開發(fā)入行真功夫
- Python之光:Python編程入門與實戰(zhàn)
- Raspberry Pi Robotic Blueprints
- 數(shù)據(jù)庫技術及應用教程上機指導與習題(第2版)
- Switching to Angular 2
- Getting Started with Hazelcast
- RPA開發(fā):UiPath入門與實戰(zhàn)
- Django 3 Web應用開發(fā)從零開始學(視頻教學版)