- 深度學(xué)習(xí)初學(xué)者指南
- (智)巴勃羅·里瓦斯
- 829字
- 2021-12-01 13:58:38
1.3.2 感知機(jī)學(xué)習(xí)算法
PLA在一開始假設(shè)需要將數(shù)據(jù)X分成兩個不同的組,即正組(+)和負(fù)組(-)。該算法將通過優(yōu)化計算的訓(xùn)練方式找到一些關(guān)于參數(shù)w和b的取值來預(yù)測相應(yīng)的正確標(biāo)簽y。PLA使用 函數(shù)作為激活函數(shù)。感知機(jī)學(xué)習(xí)算法采取的步驟如下所示:
函數(shù)作為激活函數(shù)。感知機(jī)學(xué)習(xí)算法采取的步驟如下所示:
1)將w初始化為零向量,迭代次數(shù)記為t=0
2)當(dāng)出現(xiàn)任何分類不正確的實例時:
·選擇一個分類不正確的實例,將其記為 ,它的真實標(biāo)簽記為
,它的真實標(biāo)簽記為 。
。
·將w更新為: 。
。
·增加迭代計數(shù)(t++),并重復(fù)上述過程。
注意,要想讓感知機(jī)學(xué)習(xí)算法按照我們的要求工作,必須做出一些調(diào)整。我們想要的效果是將 表示為
表示為 的形式。唯一可行的方法是設(shè)置
的形式。唯一可行的方法是設(shè)置 和
和 。此時,使用上述規(guī)則尋找w的過程其實也就蘊(yùn)含尋找b的過程。
。此時,使用上述規(guī)則尋找w的過程其實也就蘊(yùn)含尋找b的過程。
為了進(jìn)一步闡釋PLA,現(xiàn)考察線性可分?jǐn)?shù)據(jù)集的情形,如圖1.4所示。
 線性可分?jǐn)?shù)據(jù)集是指數(shù)據(jù)集中數(shù)據(jù)點之間的距離足夠大,以至于至少存在一條可以用來將數(shù)據(jù)分成兩組的假想直線。擁有線性可分?jǐn)?shù)據(jù)集是所有ML科學(xué)家的夢想,但很少能夠找到這樣的自然數(shù)據(jù)集。在以后的章節(jié)中,我們將會看到神經(jīng)網(wǎng)絡(luò)將數(shù)據(jù)轉(zhuǎn)換到新的特征空間,其中可能存在這樣的假想直線。
線性可分?jǐn)?shù)據(jù)集是指數(shù)據(jù)集中數(shù)據(jù)點之間的距離足夠大,以至于至少存在一條可以用來將數(shù)據(jù)分成兩組的假想直線。擁有線性可分?jǐn)?shù)據(jù)集是所有ML科學(xué)家的夢想,但很少能夠找到這樣的自然數(shù)據(jù)集。在以后的章節(jié)中,我們將會看到神經(jīng)網(wǎng)絡(luò)將數(shù)據(jù)轉(zhuǎn)換到新的特征空間,其中可能存在這樣的假想直線。
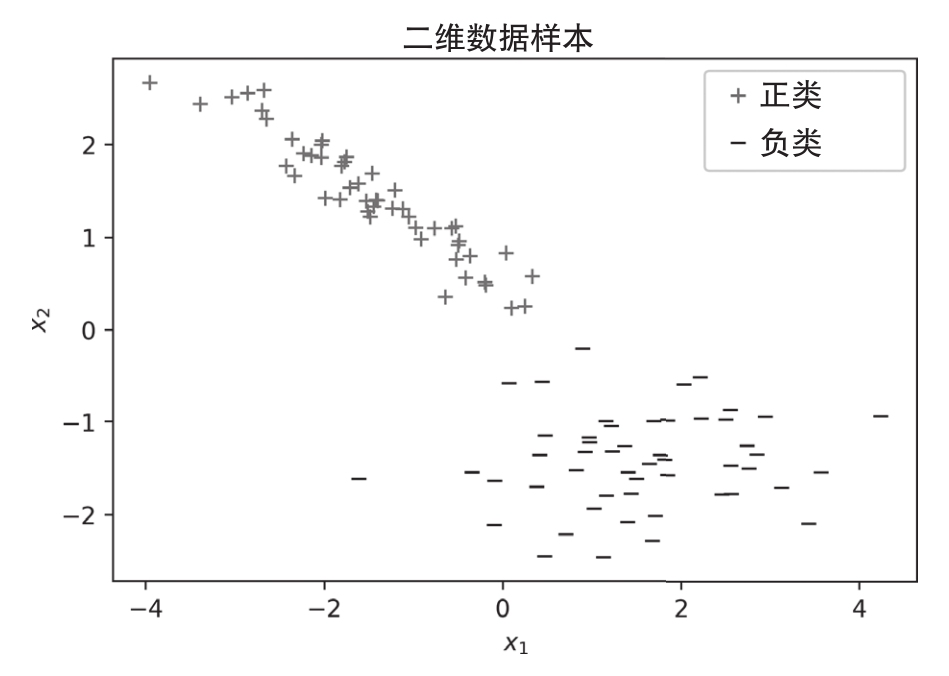
圖 1.4
這個二維數(shù)據(jù)集是使用Python工具隨機(jī)生成的,我們將會在稍后討論Python工具及其使用方法。就目前的情況而言,不言而喻的是你可以在這兩類數(shù)據(jù)之間劃清界限,將它們分開。
按照前面介紹的步驟,PLA可以找到一個解決方案,即在這個特定情況下,只需要進(jìn)行三次更新就可以畫出完全滿足訓(xùn)練數(shù)據(jù)目標(biāo)輸出的分割線。圖1.5~圖1.7分別表示每次更新后的情況,對于每次更新,相應(yīng)的假想直線都會有所變化。
在第0次迭代時,所有100個點都被錯分了,但在隨機(jī)選擇一個錯分點進(jìn)行第一次更新后,新的假想直線只弄錯了4個點,如圖1.5所示。
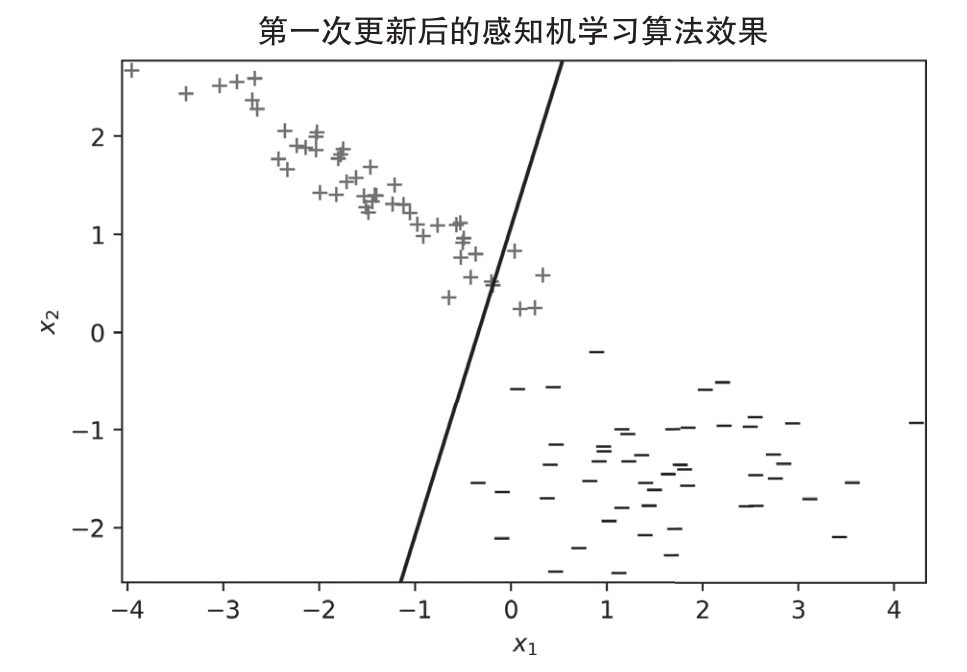
圖 1.5
在第二次更新之后,假想直線只弄錯了一個點,如圖1.6所示。
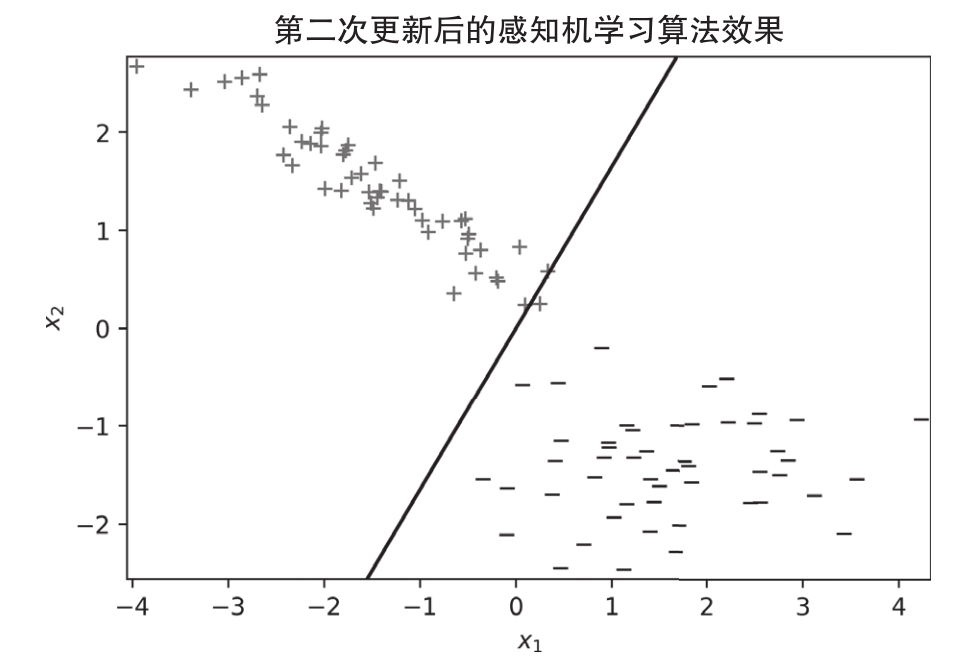
圖 1.6
最后,在第三次更新之后,所有的數(shù)據(jù)點都被正確地分類了,如圖1.7所示。這只是為了說明,一個簡單的學(xué)習(xí)算法可以成功地從數(shù)據(jù)中學(xué)習(xí)。此外,感知機(jī)模型可以產(chǎn)生更復(fù)雜的模型,如神經(jīng)網(wǎng)絡(luò)模型。下面介紹淺層網(wǎng)絡(luò)的概念及其復(fù)雜性。
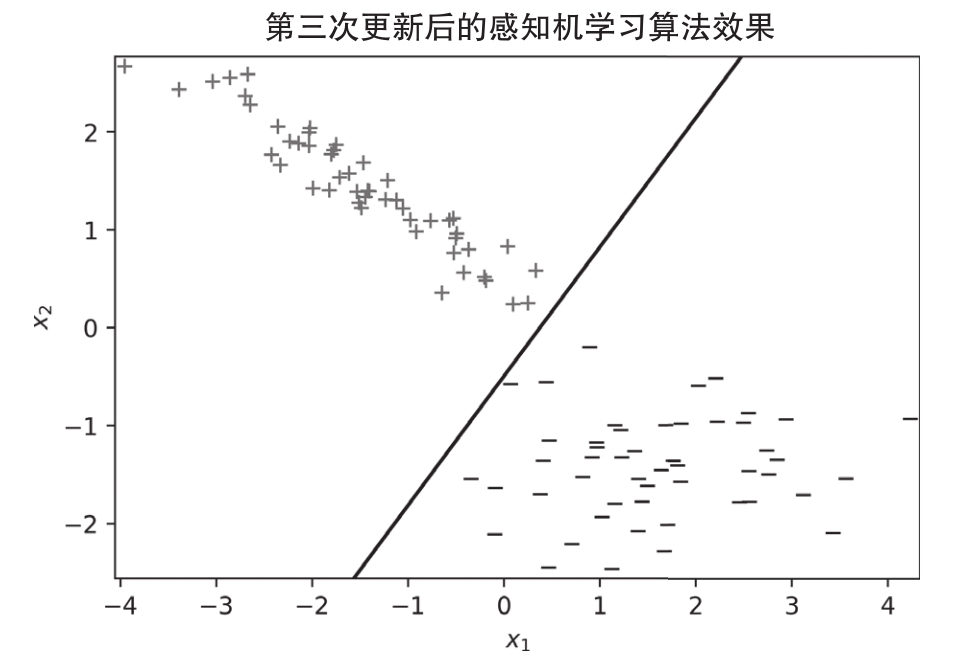
圖 1.7
- 深度學(xué)習(xí)與目標(biāo)檢測(第2版)
- 風(fēng)向:如何應(yīng)對互聯(lián)網(wǎng)變革下的知識焦慮、不確定與個人成長
- PyTorch神經(jīng)網(wǎng)絡(luò)實戰(zhàn):移動端圖像處理
- 科學(xué)+預(yù)見人工智能
- 人工智能簡史
- 深度學(xué)習(xí)實戰(zhàn):基于TensorFlow 2和Keras(原書第2版)
- AI客戶服務(wù)與管理(慕課版)
- 信息流推薦算法
- 自然語言處理技術(shù):文本信息抽取及應(yīng)用研究
- 被人工智能操控的金融業(yè)
- 未來制造:人工智能與工業(yè)互聯(lián)網(wǎng)驅(qū)動的制造范式革命
- 揭秘大模型:從原理到實戰(zhàn)
- 神經(jīng)網(wǎng)絡(luò)與深度學(xué)習(xí):基于TensorFlow框架和Python技術(shù)實現(xiàn)
- 當(dāng)計算機(jī)變成人:人工智能未來導(dǎo)引
- DeepSeek實戰(zhàn):從提示詞到部署和實踐