- 統(tǒng)計策略搜索強化學(xué)習(xí)方法及應(yīng)用
- 趙婷婷
- 1221字
- 2021-10-29 12:05:24
2.1 馬爾可夫決策過程
強化學(xué)習(xí)是機器學(xué)習(xí)領(lǐng)域的一個重要分支,是一種通過不斷與環(huán)境交互學(xué)習(xí)最終獲得最優(yōu)策略的學(xué)習(xí)范式。智能體與環(huán)境的交互過程可建模為馬爾可夫決策過程(Markov Decision Process,MDP)[1]。MDP 通常用狀態(tài)、動作、狀態(tài)轉(zhuǎn)移概率、初始狀態(tài)概率和獎勵函數(shù)構(gòu)成的五元組(S, A, P, P0, r)表示,其中:
S表示狀態(tài)空間,是所有狀態(tài)的集合, st表示 t時刻所處狀態(tài);
A表示動作空間,是所有動作的集合, at表示 t時刻所選擇的動作;
P 表示狀態(tài)轉(zhuǎn)移概率,即環(huán)境模型;根據(jù)狀態(tài)轉(zhuǎn)移概率是否已知,強化學(xué)習(xí)方法分為模型化強化學(xué)習(xí)和無模型強化學(xué)習(xí);狀態(tài)轉(zhuǎn)移概率表明從當(dāng)前狀態(tài)st,采取的動作 at,轉(zhuǎn)移到下一狀態(tài)st+1的概率,表示為 P(s t+1|s t,a t);
P0表示初始狀態(tài)概率,表示隨機選擇某一初始狀態(tài)的可能性;
rt表示 t時刻的瞬時獎勵。
智能體是具有決策能力的主體,通過狀態(tài)感知、動作選擇和接收反饋與環(huán)境進(jìn)行互動。在每個時間步 t,智能體首先觀察當(dāng)前環(huán)境狀態(tài) st,并根據(jù)當(dāng)前策略函數(shù)選擇所要采取的動作 at,所采取的動作一方面與環(huán)境交互,依據(jù)狀態(tài)轉(zhuǎn)移概率 P(s t+1|s t,a t)實現(xiàn)當(dāng)前狀態(tài) st到下一狀態(tài)st+1的轉(zhuǎn)移;另一方面,根據(jù)所采取的動作 at及狀態(tài)的轉(zhuǎn)移獲得瞬時獎勵 rt。上述過程不斷迭代 T次直至最終狀態(tài),得到路徑 ,其中 T為整條路徑的長度,具體過程如圖2-1所示。
,其中 T為整條路徑的長度,具體過程如圖2-1所示。
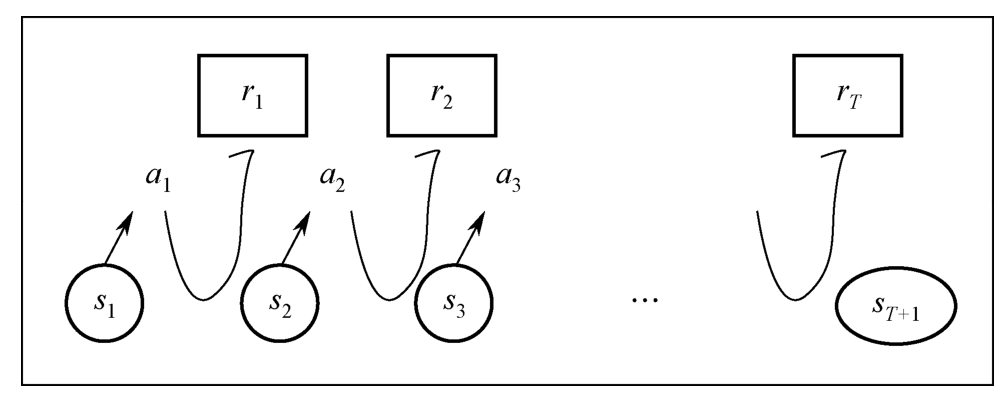
圖2-1 馬爾可夫決策過程
在強化學(xué)習(xí)任務(wù)中,狀態(tài) S和動作 A均可以為離散狀態(tài)動作空間,也可以是連續(xù)狀態(tài)動作空間。其中在許多機器人控制任務(wù)中,狀態(tài)和動作往往是連續(xù)的或者是高維離散的。本書將旨在解決狀態(tài)空間 S完全可被觀測,該空間維度已知并且為高維連續(xù)的任務(wù)。當(dāng)上述條件不成立時,任務(wù)轉(zhuǎn)化為部分可觀測馬爾可夫決策過程(POMDP)[2]。此外,關(guān)于路徑長度 T 可以是有限的,也可以是無限的,路徑是有限長度的任務(wù)意味著任務(wù)在 T 步內(nèi)完成,被稱為回合制任務(wù)(Episodic Task),如圍棋任務(wù),初始時棋盤為空,最后棋盤擺滿,一局棋相當(dāng)于一次回合制任務(wù)。另一方面,無限長度路徑對應(yīng)連續(xù)型任務(wù),此類問題無明確的開始和結(jié)束標(biāo)志。在本書中,我們考慮路徑長度有限的回合制任務(wù)。
強化學(xué)習(xí)的核心是動作選擇策略。簡單地說,策略是從感知到的狀態(tài)到采取的動作的映射,它既可以是確定性策略也可以是隨機性策略。確定性策略是給定狀態(tài) st,可以得到確定的動作 a:at=π( st);隨機性策略是將狀態(tài)空間映射到動作空間的分布,即a t~ π(at|st),表示在狀態(tài)st下執(zhí)行動作at的條件概率密度。強化學(xué)習(xí)是試錯學(xué)習(xí)機制,需要通過與環(huán)境的交互尋找最優(yōu)策略。探索和利用就是進(jìn)行決策時需要平衡的兩個方面,而隨機性策略恰好可以滿足強化學(xué)習(xí)的探索機制。
智能體與環(huán)境交互并探索動作選擇策略,該策略將從任意給定步驟中最大化從該點開始所獲得的折扣累積獎勵。為得到最優(yōu)策略,需要優(yōu)化策略函數(shù),該策略函數(shù)的更新優(yōu)化需要搜集多條路徑作為訓(xùn)練樣本。如何獲得最優(yōu)策略即為強化學(xué)習(xí)的核心內(nèi)容,根據(jù)策略函數(shù)優(yōu)化對象的不同,強化學(xué)習(xí)可分為基于值函數(shù)的策略學(xué)習(xí)算法和策略搜索算法,下面將進(jìn)行詳細(xì)闡述。
- Design for the Future
- 網(wǎng)頁編程技術(shù)
- Windows 8應(yīng)用開發(fā)實戰(zhàn)
- 大數(shù)據(jù)技術(shù)入門(第2版)
- 大數(shù)據(jù)安全與隱私保護(hù)
- 四向穿梭式自動化密集倉儲系統(tǒng)的設(shè)計與控制
- ESP8266 Home Automation Projects
- Microsoft System Center Confi guration Manager
- SAP Business Intelligence Quick Start Guide
- 網(wǎng)絡(luò)管理工具實用詳解
- 嵌入式操作系統(tǒng)原理及應(yīng)用
- Unity Multiplayer Games
- 步步驚“芯”
- 傳感器原理及實用技術(shù)
- 從零開始學(xué)ASP.NET