- Python計算機視覺與深度學習實戰
- 郭卡 戴亮編著
- 333字
- 2021-08-27 20:19:04
第 1 章 機器學習與sklearn
本章將通過介紹sklearn(scikit-learn)為讀者展現機器學習能解決的問題和解決這些問題的合理方案。sklearn是基于Python語言的機器學習工具,建立在NumPy、SciPy和Matplotlib三大工具包之上。在使用sklearn的過程中,建議閱讀一下它的源代碼,這樣能夠加深對算法的理解,提升編程水準。
sklearn提供了分類、回歸、聚類和降維4個類別的經典模型。對于如何根據數據和任務來選擇合適的方法,sklearn官網提供了一張經典的思維導圖,如圖1-1所示,其中的思路如下。
- 如果數據量小于50,一般是無法使用sklearn的機器學習算法建模的,因為機器學習需要借助統計數據才能完成。
- 如果數據有類別標簽,請使用分類模型。
- 如果數據需要預測精確值,請使用回歸模型。
- 如果想查看數據分布情況,可以考慮使用降維算法。
- 如果數據沒有類別標簽,可以使用聚類算法。
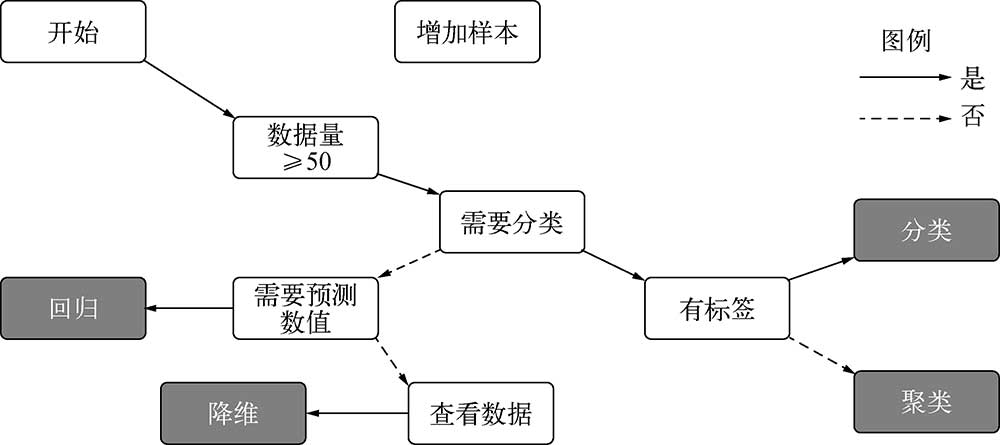
圖 1-1 sklearn算法選擇指導圖
推薦閱讀
- Learning C# by Developing Games with Unity 2020
- Cocos2D-X權威指南(第2版)
- Visual C++程序設計學習筆記
- DevOps for Networking
- Xcode 7 Essentials(Second Edition)
- Django Design Patterns and Best Practices
- Python自然語言處理(微課版)
- SQL Server與JSP動態網站開發
- 深入分布式緩存:從原理到實踐
- Mastering Unity 2D Game Development(Second Edition)
- 用案例學Java Web整合開發
- After Effects CC技術大全
- C語言編程魔法書:基于C11標準
- ASP.NET jQuery Cookbook(Second Edition)
- Implementing NetScaler VPX?(Second Edition)