- Hadoop 2.x Administration Cookbook
- Gurmukh Singh
- 425字
- 2021-07-09 20:10:31
Hadoop streaming
In this recipe, we will look at how we can execute jobs on an Hadoop cluster using scripts written in Bash or Python. It is not mandatory to use only Java for programming MapReduce code; any language can be used by evoking the Hadoop streaming utility. Do not confuse this with real-time streaming, which is different from what we will be discussing here.
Getting ready
To step through the recipes in this chapter, make sure you have a running cluster with HDFS and YARN setup correctly as discussed in the previous chapters. This can be a single node cluster or a multinode cluster, as long as the cluster is configured correctly.
It is not necessary to know Java to run MapReduce programs on Hadoop. Users can carry forward their existing scripting knowledge and use Bash or Python to run the job on Hadoop.
How to do it...
- Connect to an edge node in the cluster and switch to user
hadoop. - The streaming JAR is also under the location as Hadoop
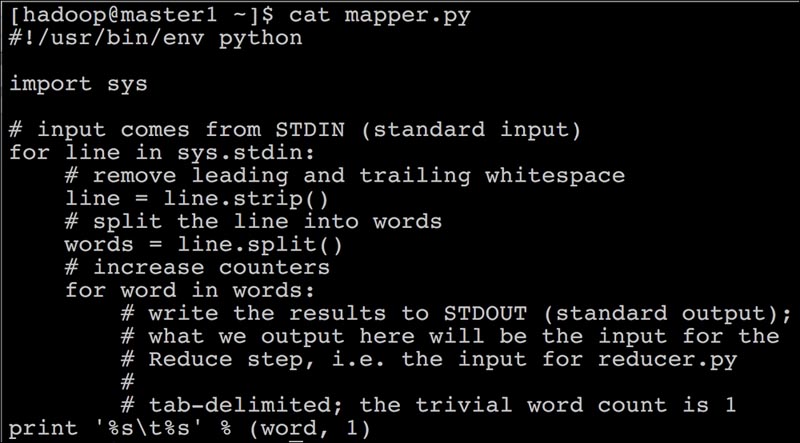
/opt/cluster/hadoop/share/hadoop/tools/lib/hadoop-streaming-2.7.2.jar. - The map script of the wordcount example using Python is shown in the following screenshot:
- The reduce script is as shown next:
#!/usr/bin/env python from operator import itemgetter import sys current_word = None current_count = 0 word = None # input comes from STDIN for line in sys.stdin: # remove leading and trailing whitespace line = line.strip() # parse the input we got from mapper.py word, count = line.split('\t', 1) # convert count (currently a string) to int try: count = int(count) except ValueError: # count was not a number, so silently # ignore/discard this line continue # this IF-switch only works because Hadoop sorts map output # by key (here: word) before it is passed to the reducer if current_word == word: current_count += count else: if current_word: # write result to STDOUT print '%s\t%s' % (current_word, current_count) current_count = count current_word = word # do not forget to output the last word if needed! if current_word == word: print '%s\t%s' % (current_word, current_count) - The user can execute the script as shown in the following screenshot:

How it works...
In this recipe, mapper.py and reducer.py are simple Python scripts, which can be executed directly on the command line, without the need for Hadoop as shown next:
$ cat file | ./mapper.py | ./reducer.py
Here, file is a simple text file. Make sure you understand the indentation in Python to troubleshoot this script.
If the users are finding it difficult to write scripts or configurations, all these are available at GitHub: https://github.com/netxillon/hadoop/tree/master/map_scripts
- 樂高機(jī)器人:WeDo編程與搭建指南
- 面向STEM的mBlock智能機(jī)器人創(chuàng)新課程
- Practical Ansible 2
- OpenStack for Architects
- Dreamweaver 8中文版商業(yè)案例精粹
- 自動(dòng)檢測與傳感技術(shù)
- AWS Administration Cookbook
- 基于多目標(biāo)決策的數(shù)據(jù)挖掘方法評估與應(yīng)用
- Moodle Course Design Best Practices
- Apache Superset Quick Start Guide
- 21天學(xué)通C語言
- 影視后期編輯與合成
- Excel 2007技巧大全
- SMS 2003部署與操作深入指南
- 從零開始學(xué)SQL Server