- Hadoop 2.x Administration Cookbook
- Gurmukh Singh
- 602字
- 2021-07-09 20:10:26
Installing a multi-node cluster
In the previous recipes, we looked at how to configure a single-node Hadoop cluster, also referred to as pseudo-distributed cluster. In this recipe, we will set up a fully distributed cluster with each daemon running on separate nodes.
There will be one node for Namenode, one for ResourceManager, and four nodes will be used for Datanode and NodeManager. In production, the number of Datanodes could be in the thousands, but here we are just restricted to four nodes. The Datanode and NodeManager coexist on the same nodes for the purposes of data locality and locality of reference.
Getting ready
Make sure that the six nodes the user chooses have JDK installed, with name resolution working. This could be done by making entries in the /etc/hosts file or using DNS.
In this recipe, we are using the following nodes:
- Namenode:
nn1.cluster1.com - ResourceManager:
jt1.cluster1.com - Datanodes and NodeManager:
dn[1-4].cluster1.com
How to do it...
- Make sure all the nodes have the
hadoopuser. - Create the directory structure
/opt/clusteron all the nodes. - Make sure the ownership is correct for
/opt/cluster. - Copy the
/opt/cluster/hadoop-2.7.3directory from thenn1.cluster.comto all the nodes in the cluster:$ for i in 192.168.1.{72..75};do scp -r hadoop-2.7.3 $i:/opt/cluster/ $i;done - The preceding IPs belong to the nodes in the cluster. The user needs to modify them accordingly. Also, to prevent it from prompting for password for each node, it is good to set up pass phraseless access between each node.
- Change to the directory
/opt/clusterand create a symbolic link on each node:$ ln –s hadoop-2.7.3 hadoop - Make sure that the environment variables have been set up on all nodes:
$ . /etc/profile.d/hadoopenv.sh - On Namenode, only the parameters specific to it are needed.
- The file
core-site.xmlremains the same across all nodes in the cluster. - On Namenode, the file
hdfs-site.xmlchanges as follows: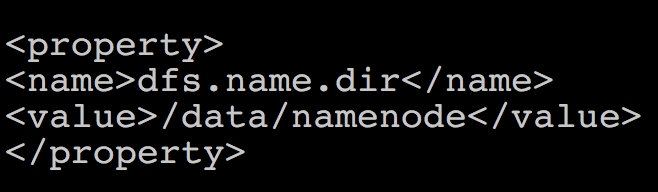
- On Datanode, the file
hdfs-site.xmlchanges as follows: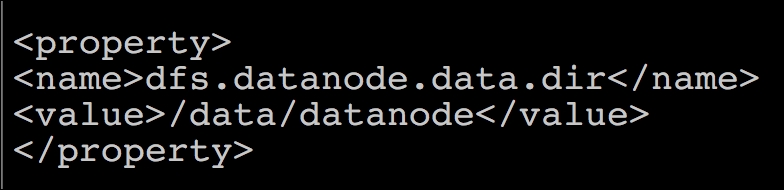
- On Datanodes, the file
yarn-site.xmlchanges as follows: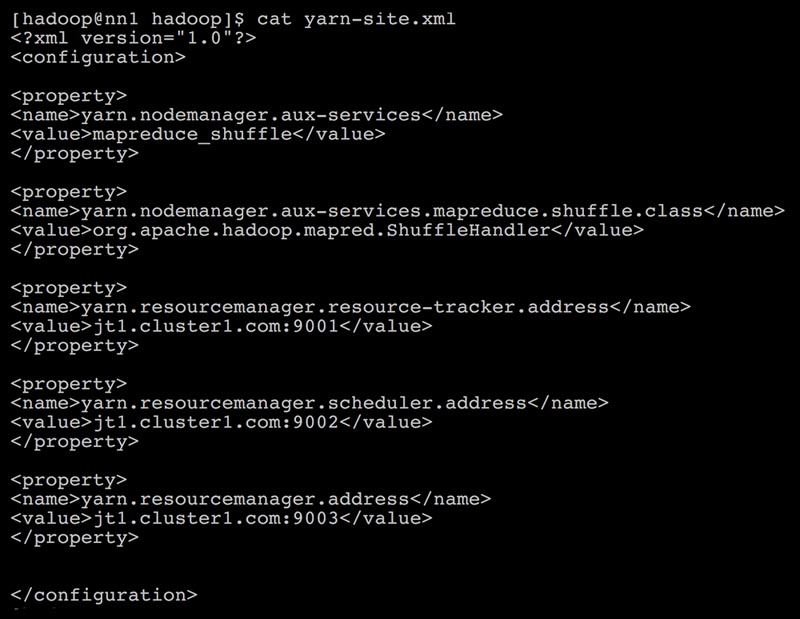
- On the node jt1, which is ResourceManager, the file
yarn-site.xmlis as follows: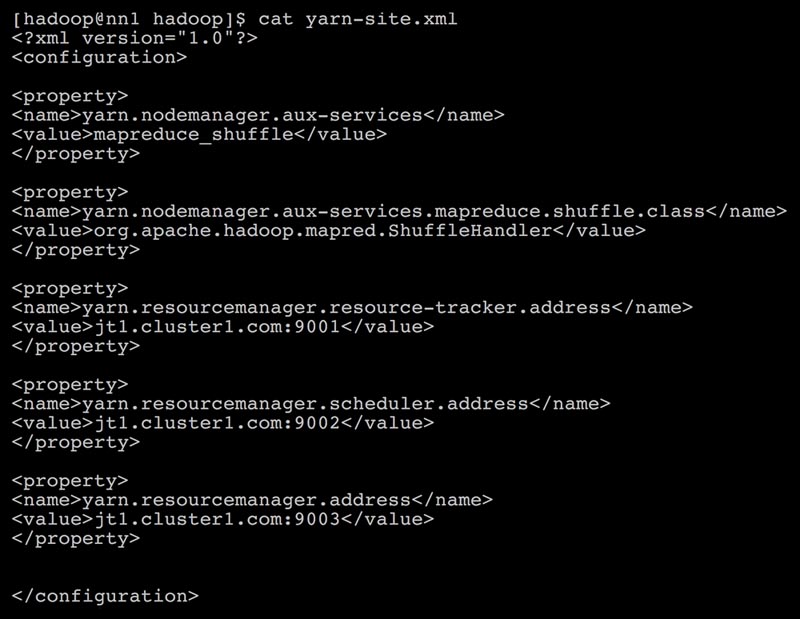
- To start Namenode on
nn1.cluster1.com, enter the following:$ hadoop-daemon.sh start namenode - To start Datanode and NodeManager on
dn[1-4], enter the following:$ hadoop-daemon.sh start datanode $ yarn-daemon.sh start nodemanager
- To start ResourceManager on
jt1.cluster.com, enter the following:$ yarn-daemon.sh start resourcemanager - On each node, execute the command
jpsto see the daemons running on them. Make sure you have the correct services running on each node. - Create a text file
test.txtand copy it to HDFS usinghadoop fs –put test.txt /. This confirms that HDFS is working fine. - To verify that YARN has been set up correctly, run the simple "Pi" estimation program:
$ yarn jar /opt/cluster/hadoop/share/hadoop/mapreduce/hadoop-example.jar Pi 3 3
How it works...
Steps 1 through 7 copy the already extracted and configured Hadoop files to other nodes in the cluster. From step 8 onwards, each node is configured according to the role it plays in the cluster.
The user should see four Datanodes reporting to the cluster, and should also be able to access the UI of the Namenode on port 50070 and on port 8088 for ResourceManager.
To see the number of nodes talking to Namenode, enter the following:
$ hdfs dfsadmin -report Configured Capacity: 9124708352 (21.50 GB) Present Capacity: 5923942400 (20.52 GB) DFS Remaining: 5923938304 (20.52 GB) DFS Used: 4096 (4 KB) DFS Used%: 0.00% Live datanodes (4):
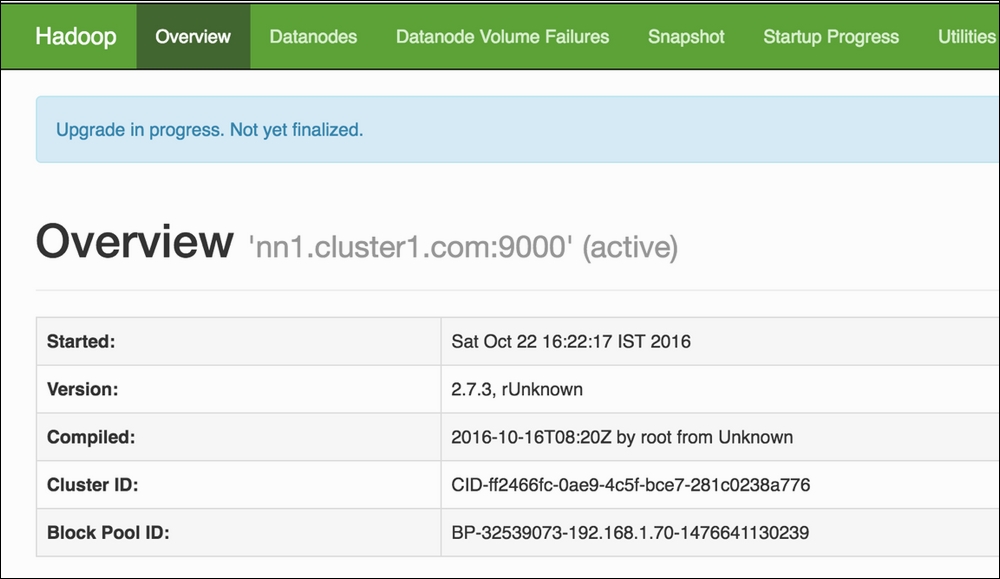
The same information can also be retrieved using the Namenode Web UI as shown in the following screenshot:
- Hands-On Intelligent Agents with OpenAI Gym
- 反饋系統(tǒng):多學(xué)科視角(原書第2版)
- 腦動(dòng)力:PHP函數(shù)速查效率手冊(cè)
- 精通Excel VBA
- Visual C# 2008開發(fā)技術(shù)詳解
- CompTIA Network+ Certification Guide
- AutoCAD 2012中文版繪圖設(shè)計(jì)高手速成
- Moodle Course Design Best Practices
- 統(tǒng)計(jì)學(xué)習(xí)理論與方法:R語(yǔ)言版
- 電腦主板現(xiàn)場(chǎng)維修實(shí)錄
- 人工智能趣味入門:光環(huán)板程序設(shè)計(jì)
- LAMP網(wǎng)站開發(fā)黃金組合Linux+Apache+MySQL+PHP
- 單片機(jī)C語(yǔ)言應(yīng)用100例
- 大數(shù)據(jù)案例精析
- Mastering Ansible(Second Edition)