- Scala Machine Learning Projects
- Md. Rezaul Karim
- 607字
- 2021-06-30 19:05:43
H2O and Sparkling water
H2O is an AI platform for machine learning. It offers a rich set of machine learning algorithms and a web-based data processing UI that comes as both open sources as well as commercial. Using H2O, it's possible to develop machine learning and DL applications with a wide range of languages, such as Java, Scala, Python, and R:

It also has the ability to interface with Spark, HDFS, SQL, and NoSQL databases. In short, H2O works with R, Python, and Scala on Hadoop/Yarn, Spark, or laptop. On the other hand, Sparkling water combines the fast, scalable ML algorithms of H2O with the capabilities of Spark. It drives the computation from Scala/R/Python and utilizes the H2O flow UI. In short, Sparkling water = H2O + Spark.
Throughout the next few chapters, we will explore and the wide rich features of H2O and Sparkling water; however, I believe it would be useful to provide a diagram of all of the functional areas that it covers:
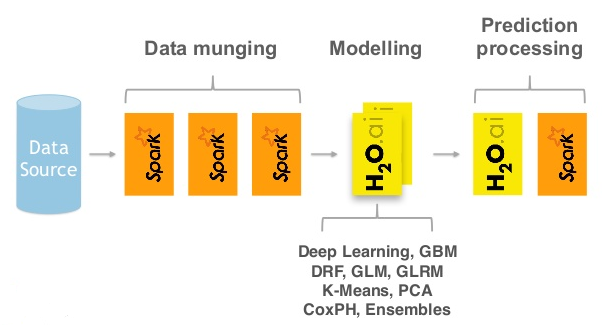
This is a list of features and techniques curated from the H2O website. It can be used for wrangling data, modeling using the data, and scoring the resulting models:
- Process
- Model
- The scoring tool
- Data profiling
- Generalized linear models (GLM)
- Predict
- Summary statistics
- Decision trees
- Confusion matrix
- Aggregate, filter, bin, and derive columns
- Gradient boosting machine (GBM)
- AUC
- Slice, log transform, and anonymize
- K-means
- Hit ratio
- Variable creation
- Anomaly detection
- PCA/PCA score
- DL
- Multimodel scoring
- Training and validation sampling plan
- Naive Bayes
- Grid search
The following figure shows how to provide a clear method of describing the way in which H2O Sparkling water can be used to extend the functionality of Apache Spark. Both H2O and Spark are open source systems. Spark MLlib contains a great deal of functionality, while H2O extends this with a wide range of extra functionalities, including DL. It offers tools to transform, model, and score the data, as we can find in Spark ML. It also offers a web-based user interface to interact with:
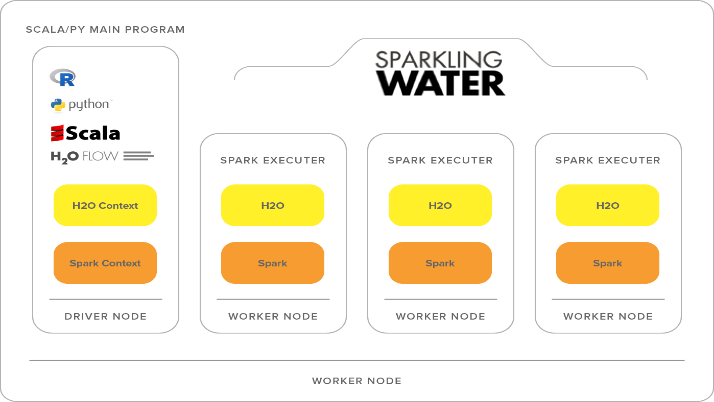
The following figure shows how H2O integrates with Spark. As we already know, Spark has master and worker servers; the workers create executors to do the actual work. The following steps occur to run a Sparkling water-based application:
- Spark's submit command sends the Sparkling water JAR to the Spark master
- The Spark master starts the workers and distributes the JAR file
- The Spark workers start the executor JVMs to carry out the work
- The Spark executor starts an H2O instance
The H2O instance is embedded with the Executor JVM, and so it shares the JVM heap space with Spark. When all of the H2O instances have started, H2O forms a cluster, and then the H2O flow web interface is made available:

The preceding figure explains how H2O fits into the Spark architecture and how it starts, but what about data sharing? Now the question would be: how does data pass between Spark and H2O? The following diagram explains this:

To get a clearer view of the preceding figure, a new H2O RDD data structure has been created for H2O and Sparkling water. It is a layer based at the top of an H2O frame, each column of which represents a data item and is independently compressed to provide the best compression ratio.
- 輕輕松松自動化測試
- Circos Data Visualization How-to
- Excel 2007函數與公式自學寶典
- Mastering D3.js
- MCSA Windows Server 2016 Certification Guide:Exam 70-741
- 流處理器研究與設計
- 聊天機器人:入門、進階與實戰
- 突破,Objective-C開發速學手冊
- TensorFlow Reinforcement Learning Quick Start Guide
- Excel 2007常見技法與行業應用實例精講
- INSTANT Munin Plugin Starter
- Web璀璨:Silverlight應用技術完全指南
- ADuC系列ARM器件應用技術
- Flash CS5二維動畫設計與制作
- Flash CS3動畫制作融會貫通