- Scala Machine Learning Projects
- Md. Rezaul Karim
- 345字
- 2021-06-30 19:05:38
Historical data collection
For training the ML algorithm, there is a Bitcoin Historical Price Data dataset available to the public on Kaggle (version 10). The dataset can be downloaded from https://www.kaggle.com/mczielinski/bitcoin-historical-data/. It has 1 minute OHLC data for BTC-USD pairs from several exchanges.
At the beginning of the project, for most of them, data was available from January 1, 2012 to May 31, 2017; but for the Bitstamp exchange, it's available until October 20, 2017 (as well as for Coinbase, but that dataset became available later):
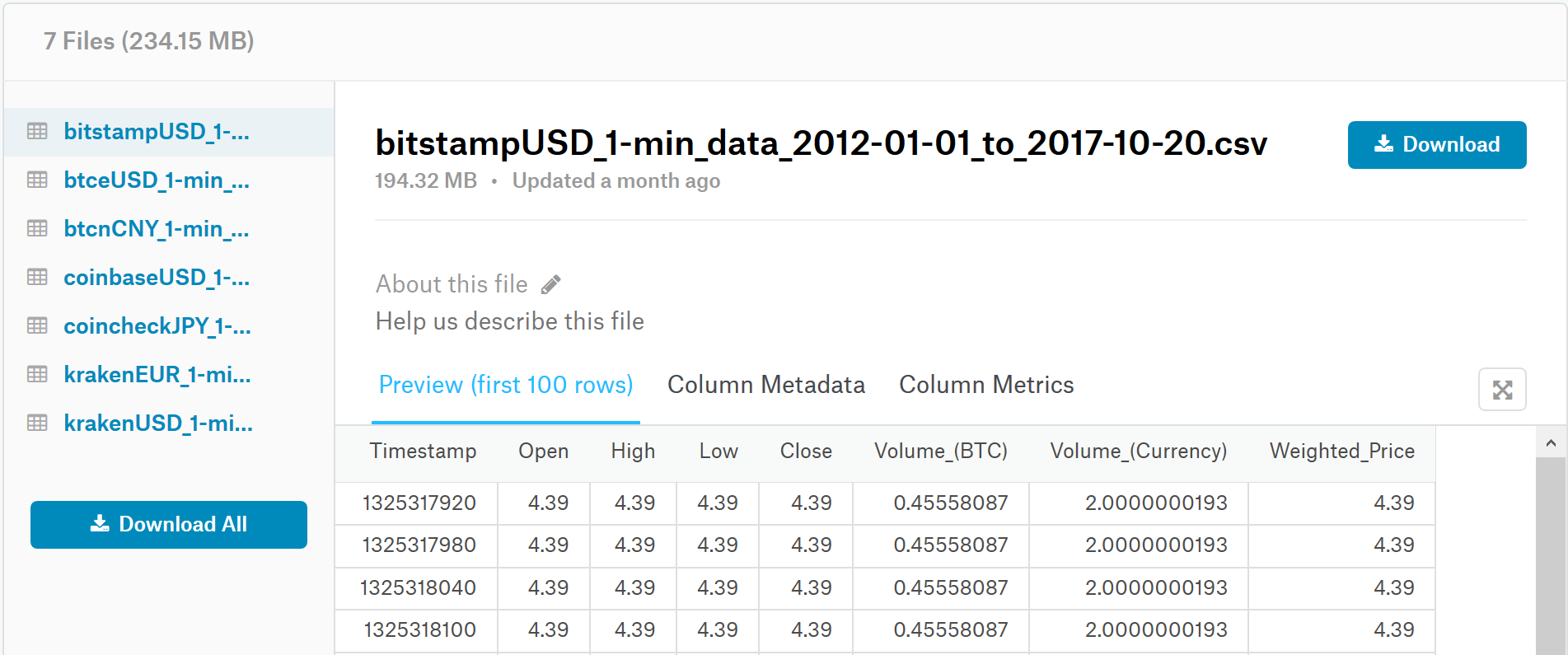
Note that you need to be a registered user and be logged in in order to download the file. The file that we are using is bitstampUSD_1-min_data_2012-01-01_to_2017-10-20.csv. Now, let us get the data we have. It has eight columns:
- Timestamp: The time elapsed in seconds since January 1, 1970. It is 1,325,317,920 for the first row and 1,325,317,920 for the second 1. (Sanity check! The difference is 60 seconds).
- Open: The price at the opening of the time interval. It is 4.39 dollars. Therefore it is the price of the first trade that happened after Timestamp (1,325,317,920 in the first row's case).
- Close: The price at the closing of the time interval.
- High: The highest price from all orders executed during the interval.
- Low: The same as High but it is the lowest price.
- Volume_(BTC): The sum of all Bitcoins that were transferred during the time interval. So, take all transactions that happened during the selected interval and sum up the BTC values of each of them.
- Volume_(Currency): The sum of all dollars transferred.
- Weighted_Price: This is derived from the volumes of BTC and USD. By dividing all dollars traded by all bitcoins, we can get the weighted average price of BTC during this minute. So Weighted_Price=Volume_(Currency)/Volume_(BTC).
One of the most important parts of the data-science pipeline after data collection (which is in a sense outsourced; we use data collected by others) is data preprocessing—clearing a dataset and transforming it to suit our needs.