- Scala Machine Learning Projects
- Md. Rezaul Karim
- 348字
- 2021-06-30 19:05:36
Selecting the best model for deployment
From the preceding results, it can be seen that LR and SVM models have the same but higher false positive rate compared to Random Forest and DT. So we can say that DT and Random Forest have better accuracy overall in terms of true positive counts. Let's see the validity of the preceding statement with prediction distributions on pie charts for each model:
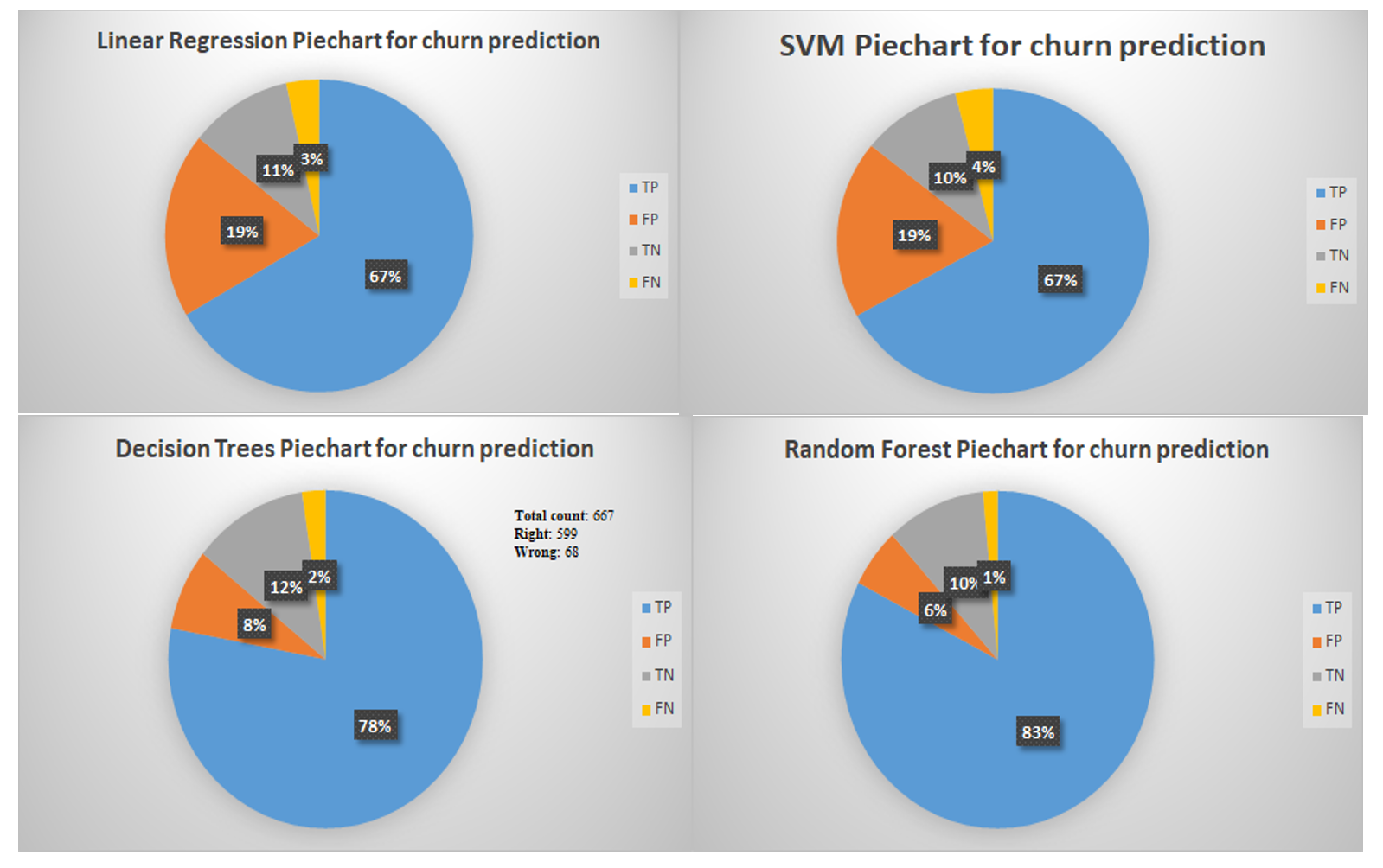
Now, it's worth mentioning that using random forest, we are actually getting high accuracy, but it's a very resource, as well as time-consuming job; the training, especially, takes a considerably longer time as compared to LR and SVM.
Therefore, if you don't have higher memory or computing power, it is recommended to increase the Java heap space prior to running this code to avoid OOM errors.
Finally, if you want to deploy the best model (that is, Random Forest in our case), it is recommended to save the cross-validated model immediately after the fit() method invocation:
// Save the workflow
cvModel.write.overwrite().save("model/RF_model_churn")
Your trained model will be saved to that location. The directory will include:
- The best model
- Estimator
- Evaluator
- The metadata of the training itself
Now the next task will be restoring the same model, as follows:
// Load the workflow back
val cvModel = CrossValidatorModel.load("model/ RF_model_churn/")
Finally, we need to transform the test set to the model pipeline that maps the features according to the same mechanism we described in the preceding feature engineering step:
val predictions = cvModel.transform(Preprocessing.testSet)
Finally, we evaluate the restored model:
val evaluator = new BinaryClassificationEvaluator()
.setLabelCol("label")
.setRawPredictionCol("prediction")
val accuracy = evaluator.evaluate(predictions)
println("Accuracy: " + accuracy)
evaluator.explainParams()
val predictionAndLabels = predictions
.select("prediction", "label")
.rdd.map(x => (x(0).asInstanceOf[Double], x(1)
.asInstanceOf[Double]))
val metrics = new BinaryClassificationMetrics(predictionAndLabels)
val areaUnderPR = metrics.areaUnderPR
println("Area under the precision-recall curve: " + areaUnderPR)
val areaUnderROC = metrics.areaUnderROC
println("Area under the receiver operating characteristic (ROC) curve: " + areaUnderROC)
>>>
You will receive the following output:
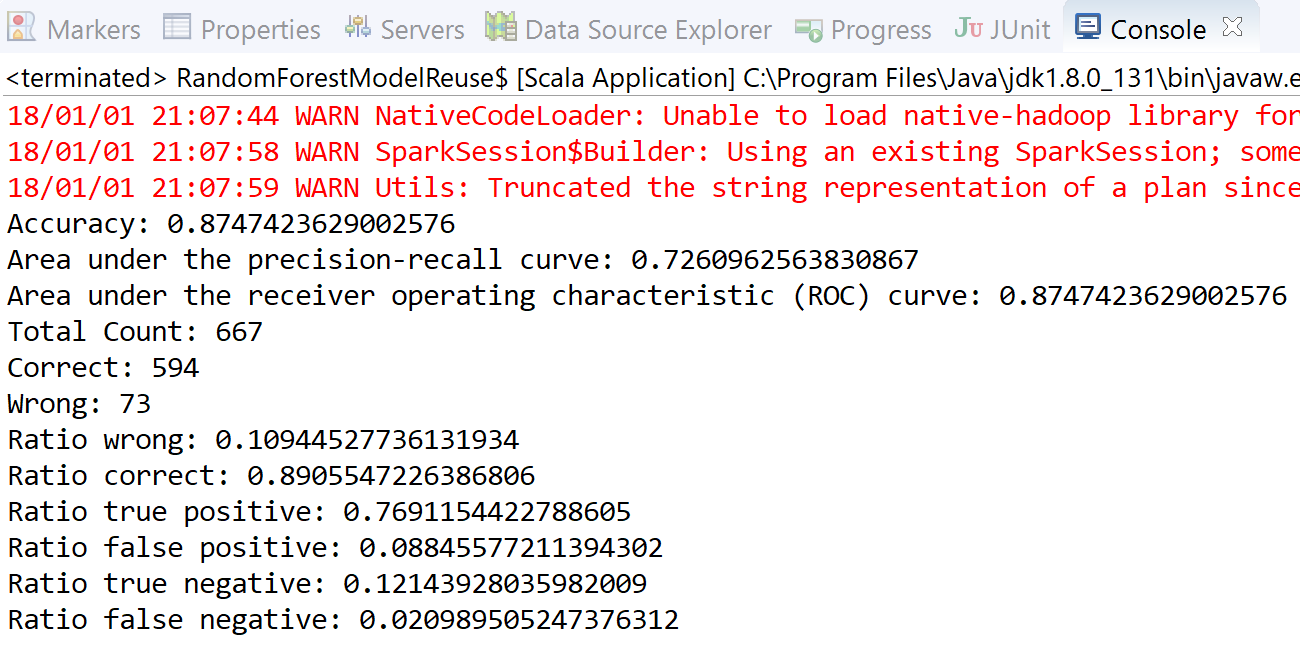
Well, done! We have managed to reuse the model and do the same prediction. But, probably due to the randomness of data, we observed slightly different predictions.