- Scala Machine Learning Projects
- Md. Rezaul Karim
- 450字
- 2021-06-30 19:05:33
Developing a churn analytics pipeline
In ML, we observe an algorithm's performance in two stages: learning and inference. The ultimate target of the learning stage is to prepare and describe the available data, also called the feature vector, which is used to train the model.
The learning stage is one of the most important stages, but it is also truly time-consuming. It involves preparing a list of vectors, also called feature vectors (vectors of numbers representing the value of each feature), from the training data after transformation so that we can feed them to the learning algorithms. On the other hand, training data also sometimes contains impure information that needs some pre-processing, such as cleaning.
Once we have the feature vectors, the next step in this stage is preparing (or writing/reusing) the learning algorithm. The next important step is training the algorithm to prepare the predictive model. Typically, (and of course based on data size), running an algorithm may take hours (or even days) so that the features converge into a useful model, as shown in the following figure:

The second most important stage is the inference that is used for making an intelligent use of the model, such as predicting from the never-before-seen data, making recommendations, deducing future rules, and so on. Typically, it takes less time compared to the learning stage, and is sometimes even in real time. Thus, inferencing is all about testing the model against new (that is, unobserved) data and evaluating the performance of the model itself, as shown in the following figure:

However, during the whole process and for making the predictive model a successful one, data acts as the first-class citizen in all ML tasks. Keeping all this in mind, the following figure shows an analytics pipeline that can be used by telecommunication companies:
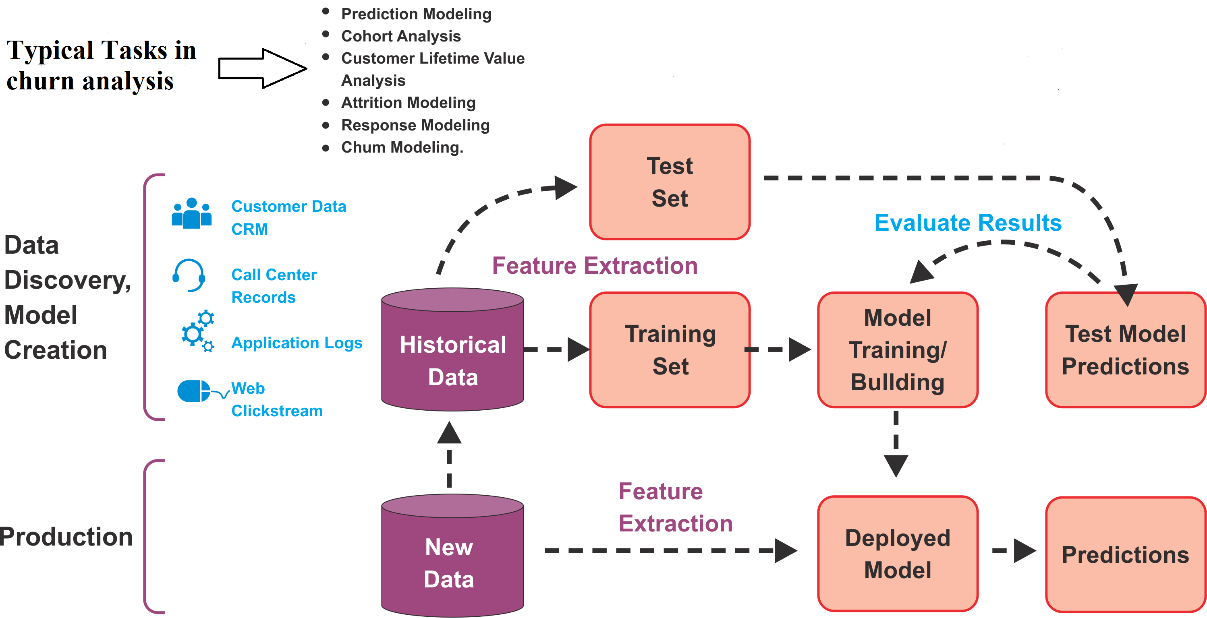
With this kind of analysis, telecom companies can discern how to predict and enhance the customer experience, which can, in turn, prevent churn and tailor marketing campaigns. In practice, often these business assessments are used in order to retain the customers most likely to leave, as opposed to those who are likely to stay.
Thus, we need to develop a predictive model so that it ensures that our model is sensitive to the Churn = True samples—that is, a binary classification problem. We will see more details in upcoming sections.
- Introduction to DevOps with Kubernetes
- Learning Microsoft Azure Storage
- Excel 2007函數與公式自學寶典
- VMware Performance and Capacity Management(Second Edition)
- PyTorch深度學習實戰
- Visual C# 2008開發技術詳解
- Apache Spark Deep Learning Cookbook
- 樂高機器人—槍械武器庫
- 分數階系統分析與控制研究
- 單片機C語言程序設計完全自學手冊
- Hands-On Dashboard Development with QlikView
- Mastering OpenStack(Second Edition)
- 單片機C51應用技術
- SolarWinds Server & Application Monitor:Deployment and Administration
- 這樣用Word!