- Python Web Scraping Cookbook
- Michael Heydt
- 312字
- 2021-06-30 18:44:00
Getting ready
We will use a small web site that is included in the www folder of the sample code. To follow along, start a web server from within the www folder. This can be done with Python 3 as follows:
www $ python3 -m http.server 8080
Serving HTTP on 0.0.0.0 port 8080 (http://0.0.0.0:8080/) ...
The DOM of a web page can be examined in Chrome by right-clicking the page and selecting Inspect. This opens the Chrome Developer Tools. Open a browser page to http://localhost:8080/planets.html. Within chrome you can right click and select 'inspect' to open developer tools (other browsers have similar tools).
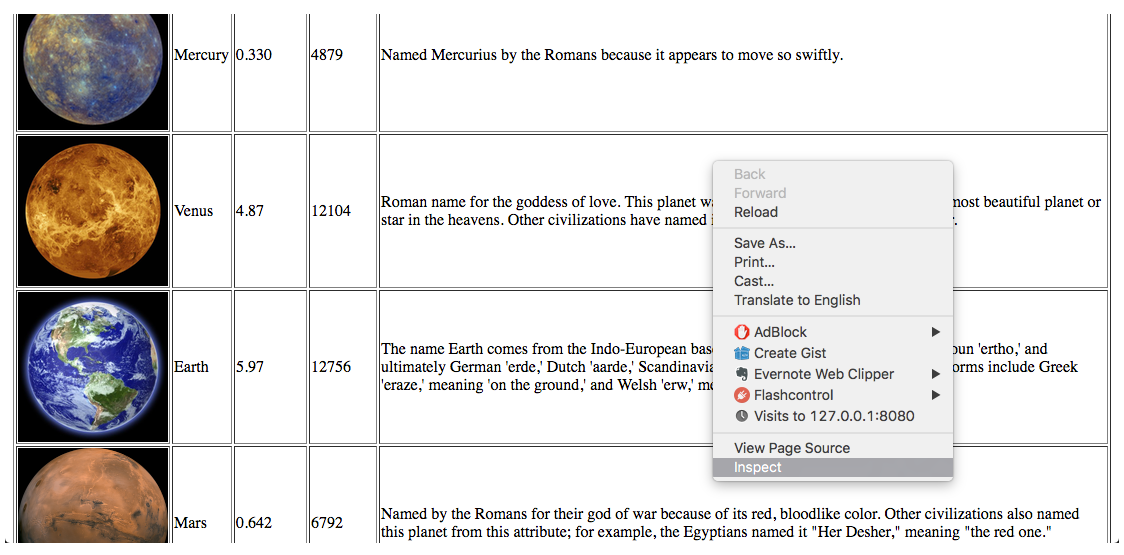
This opens the developer tools and the inspector. The DOM can be examined in the Elements tab.
The following shows the selection of the first row in the table:

Each row of planets is within a <tr> element. There are several characteristics of this element and its neighboring elements that we will examine because they are designed to model common web pages.
Firstly, this element has three attributes: id, planet, and name. Attributes are often important in scraping as they are commonly used to identify and locate data embedded in the HTML.
Secondly, the <tr> element has children, and in this case, five <td> elements. We will often need to look into the children of a specific element to find the actual data that is desired.
This element also has a parent element, <tbody>. There are also sibling elements, and the a set of <tr> child elements. From any planet, we can go up to the parent and find the other planets. And as we will see, we can use various constructs in the various tools, such as the find family of functions in Beautiful Soup, and also XPath queries, to easily navigate these relationships.